This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
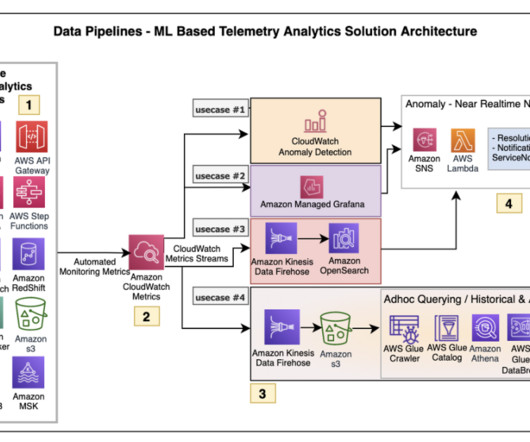
More than ever, advanced analytics, ML, and AI are providing the foundation for innovation, efficiency, and profitability. But insights derived from day-old data don’t cut it. Many scenarios call for up-to-the-minute information. Now, information is dynamic. That’s where streaming datapipelines come into play.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
Over the last few years, with the rapid growth of data, pipeline, AI/ML, and analytics, DataOps has become a noteworthy piece of day-to-day business New-age technologies are almost entirely running the world today. Among these technologies, big data has gained significant traction. This concept is …
With that, the need for data scientists and machine learning (ML) engineers has grown significantly. These skilled professionals are tasked with building and deploying models that improve the quality and efficiency of BMW’s business processes and enable informed leadership decisions.
Machine Learning (ML) is a powerful tool that can be used to solve a wide variety of problems. Getting your ML model ready for action: This stage involves building and training a machine learning model using efficient machine learning algorithms. This involves removing any errors or inconsistencies in the data.
Instead, organizations are increasingly looking to take advantage of transformative technologies like machine learning (ML) and artificial intelligence (AI) to deliver innovative products, improve outcomes, and gain operational efficiencies at scale. Data is presented to the personas that need access using a unified interface.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
Key skills and qualifications for machine learning engineers include: Strong programming skills: Proficiency in programming languages such as Python, R, or Java is essential for implementing machine learning algorithms and building datapipelines.
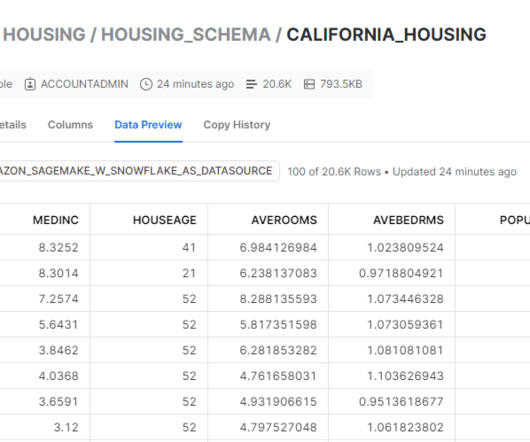
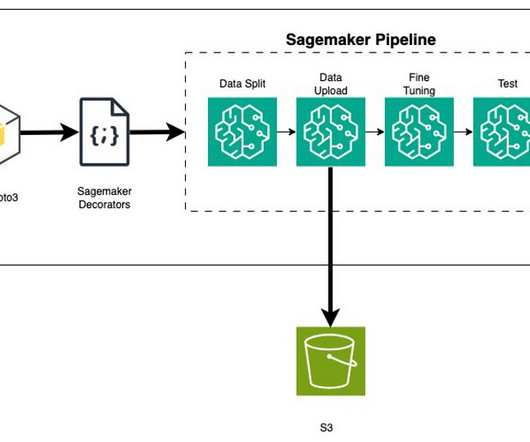
Amazon SageMaker is a fully managed machine learning (ML) service. With SageMaker, data scientists and developers can quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment. We add this data to Snowflake as a new table.
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML. The next step is to build ML models using features selected from one or multiple feature groups.
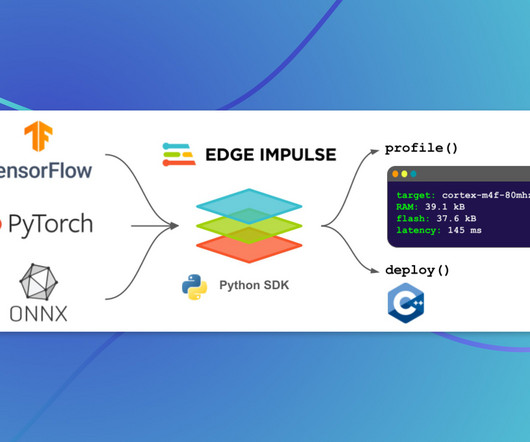
Last Updated on April 4, 2023 by Editorial Team Introducing a Python SDK that allows enterprises to effortlessly optimize their ML models for edge devices. With their groundbreaking web-based Studio platform, engineers have been able to collect data, develop and tune ML models, and deploy them to devices.
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
The growth of the AI and Machine Learning (ML) industry has continued to grow at a rapid rate over recent years. Hidden Technical Debt in Machine Learning Systems More money, more problems — Rise of too many ML tools 2012 vs 2023 — Source: Matt Turck People often believe that money is the solution to a problem. Spark, Flink, etc.)
While these models are trained on vast amounts of generic data, they often lack the organization-specific context and up-to-date information needed for accurate responses in business settings. After ingesting the data, you create an agent with specific instructions: agent_instruction = """You are the Amazon Bedrock Agent.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
Aleksandr Timashov is an ML Engineer with over a decade of experience in AI and Machine Learning. In this interview, Aleksandr shares his unique experiences of leading groundbreaking projects in Computer Vision and Data Science at the Petronas global energy group (Malaysia). This does sound intriguing!
Building generative AI applications presents significant challenges for organizations: they require specialized ML expertise, complex infrastructure management, and careful orchestration of multiple services. These components will work together to process and retrieve information for your generative AI application.
Data is one of the most critical assets of many organizations. Theyre constantly seeking ways to use their vast amounts of information to gain competitive advantages. This enables OMRON to extract meaningful patterns and trends from its vast data repositories, supporting more informed decision-making at all levels of the organization.
AWS recently released Amazon SageMaker geospatial capabilities to provide you with satellite imagery and geospatial state-of-the-art machine learning (ML) models, reducing barriers for these types of use cases. For more information, refer to Preview: Use Amazon SageMaker to Build, Train, and Deploy ML Models Using Geospatial Data.
Machine learning (ML) engineer Potential pay range – US$82,000 to 160,000/yr Machine learning engineers are the bridge between data science and engineering. Integrating the knowledge of data science with engineering skills, they can design, build, and deploy machine learning (ML) models.
This makes managing and deploying these updates across a large-scale deployment pipeline while providing consistency and minimizing downtime a significant undertaking. Generative AI applications require continuous ingestion, preprocessing, and formatting of vast amounts of data from various sources.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
With an increasing reliance on ML models across various sectors, identifying potential failures before they manifest is vital for maintaining user trust and operational efficiency. A thorough understanding of these failures can inform better practices and approaches. What is failure analysis machine learning?
It enhances scalability, experimentation, and reproducibility, allowing ML teams to focus on innovation. This blog highlights the importance of organised, flexible configurations in ML workflows and introduces Hydra. It also simplifies managing configuration dependencies in Deep Learning projects and large-scale datapipelines.
Statistical methods and machine learning (ML) methods are actively developed and adopted to maximize the LTV. In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
We are excited to announce the launch of Amazon DocumentDB (with MongoDB compatibility) integration with Amazon SageMaker Canvas , allowing Amazon DocumentDB customers to build and use generative AI and machine learning (ML) solutions without writing code. Follow the tutorial to load sample restaurant data into Amazon DocumentDB.
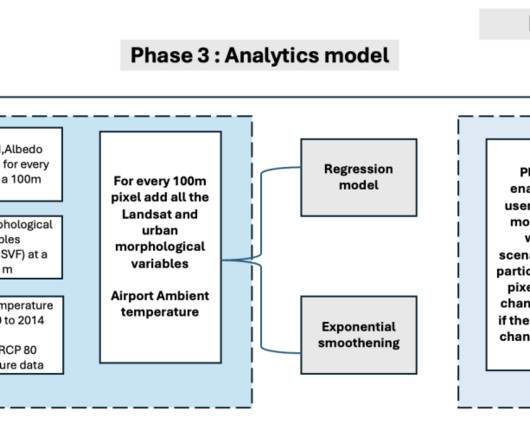
By providing authorities with the tools and insights they need to make informed decisions about environmental and social impact, Gramener is playing a vital role in building a more sustainable future. Urban heat islands (UHIs) are areas within cities that experience significantly higher temperatures than their surrounding rural areas.
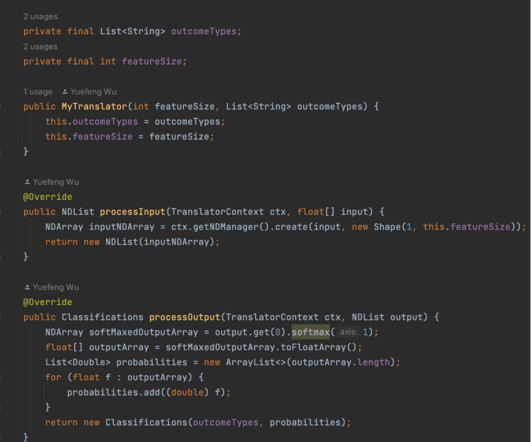
Since 2018, our team has been developing a variety of ML models to enable betting products for NFL and NCAA football. These models are then pushed to an Amazon Simple Storage Service (Amazon S3) bucket using DVC, a version control tool for ML models. For more information on the DJL and its other features, see Deep Java Library.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. For more information, see Zeta Global’s home page. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
In their implementation of generative AI technology, enterprises have real concerns about data exposure and ownership of confidential information that may be sent to LLMs. These concerns of privacy and data protection can slow down or limit the usage of LLMs in organizations.
Recent improvements in Generative AI based large language models (LLMs) have enabled their use in a variety of applications surrounding information retrieval. Given the data sources, LLMs provided tools that would allow us to build a Q&A chatbot in weeks, rather than what may have taken years previously, and likely with worse performance.
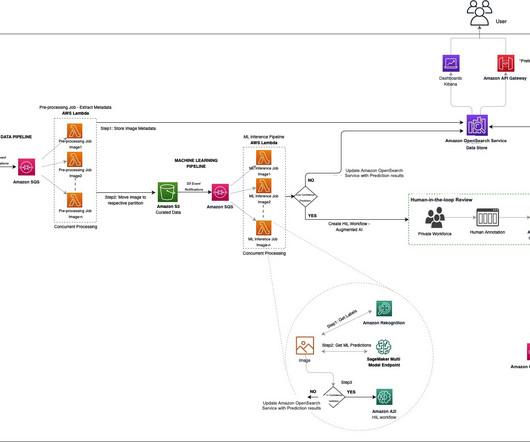
Purina used artificial intelligence (AI) and machine learning (ML) to automate animal breed detection at scale. The solution focuses on the fundamental principles of developing an AI/ML application workflow of data preparation, model training, model evaluation, and model monitoring. DynamoDB is used to store the pet attributes.
Long-term ML project involves developing and sustaining applications or systems that leverage machine learning models, algorithms, and techniques. An example of a long-term ML project will be a bank fraud detection system powered by ML models and algorithms for pattern recognition. 2 Ensuring and maintaining high-quality data.
AI offers a transformative approach by automating the interpretation of regulations, supporting data cleansing, and enhancing the efficacy of surveillance systems. AI-powered systems can analyze transactions in real-time and flag suspicious activities more accurately, which helps institutions take informed actions to prevent financial losses.
As one of the largest AWS customers, Twilio engages with data, artificial intelligence (AI), and machine learning (ML) services to run their daily workloads. Data is the foundational layer for all generative AI and ML applications.
Machine learning (ML) is becoming increasingly complex as customers try to solve more and more challenging problems. This complexity often leads to the need for distributed ML, where multiple machines are used to train a single model. SageMaker is a fully managed service for building, training, and deploying ML models.
Datapipelines In cases where you need to provide contextual data to the foundation model using the RAG pattern, you need a datapipeline that can ingest the source data, convert it to embedding vectors, and store the embedding vectors in a vector database.
For data science practitioners, productization is key, just like any other AI or ML technology. However, it's important to contextualize generative AI within the broader landscape of AI and ML technologies. By thinking about the ML process in advance: preparing, managing, and versioning data, reusing components, etc.,
Through evaluations of sensors and informed decision-making support, Afri-SET empowers governments and civil society for effective air quality management. The attempt is disadvantaged by the current focus on data cleaning, diverting valuable skills away from building ML models for sensor calibration.
Amazon SageMaker Feature Store is a fully managed, purpose-built repository to store, share, and manage features for machine learning (ML) models. Features are inputs to ML models used during training and inference. Their task is to construct and oversee efficient datapipelines.
When working on real-world ML projects , you come face-to-face with a series of obstacles. The ml model reproducibility problem is one of them. Instead, we tend to spend much time on data exploration, preprocessing, and modeling. This is indeed an erroneous thing to do when working on ML projects at scale.
Today, personally identifiable information (PII) is everywhere. It refers to any data or information that can be used to identify a specific individual. It’s a critical component of modern data management and cybersecurity practices. PII is in emails, slack messages, videos, PDFs, and so on.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.




























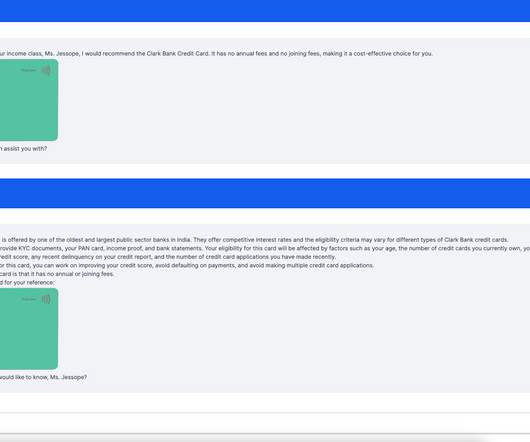

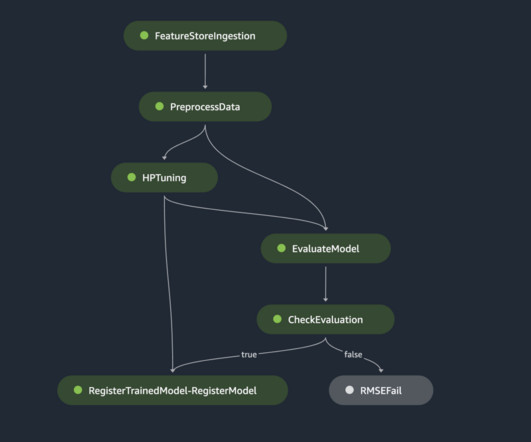



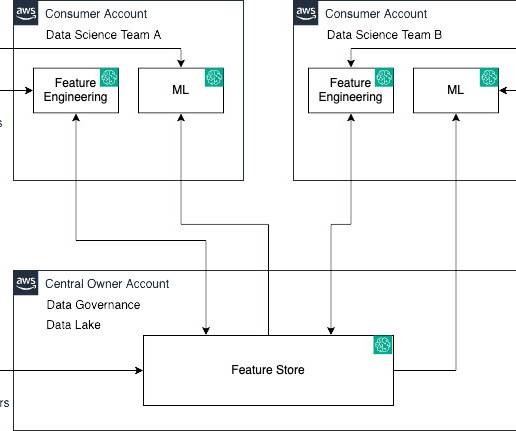

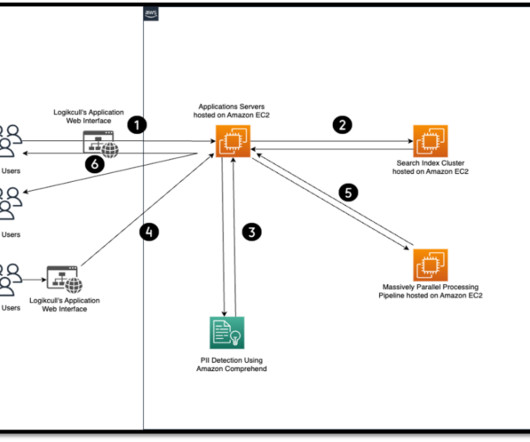






Let's personalize your content