This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Large language model embeddings, or LLM embeddings, are a powerful approach to capturing semantically rich information in text and utilizing it to leverage other machine learning models — like those trained using Scikit-learn — in tasks that require deep contextual understanding of text, such as intent recognition or sentiment analysis.
This post is divided into five parts; they are: • Preparing the Dataset for Training • Implementing the Seq2Seq Model with LSTM • Training the Seq2Seq Model • Using the Seq2Seq Model • Improving the Seq2Seq Model In
This post covers three main areas: • Why Mixture of Experts is Needed in Transformers • How Mixture of Experts Works • Implementation of MoE in Transformer Models The Mixture of Experts (MoE) concept was first introduced in 1991 by
MLOps, or machine learning operations, is all about managing the end-to-end process of building, training, deploying, and maintaining machine learning models.
In this article, you will learn: • the purpose and benefits of image augmentation techniques in computer vision for improving model generalization and diversity.
This post is divided into five parts; they are: • Why Normalization is Needed in Transformers • LayerNorm and Its Implementation • Adaptive LayerNorm • RMS Norm and Its Implementation • Using PyTorch's Built-in Normalization Normalization layers improve model quality in deep learning.
Machine learning practitioners spend countless hours on repetitive tasks: monitoring model performance, retraining pipelines, data quality checks, and experiment tracking.
Unity makes strength. This well-known motto perfectly captures the essence of ensemble methods: one of the most powerful machine learning (ML) approaches -with permission from deep neural networks- to effectively address complex problems predicated on complex data, by combining multiple models for addressing one predictive task.
Fine-tuning a large language model (LLM) is the process of taking a pre-trained model — usually a vast one like GPT or Llama models, with millions to billions of weights — and continuing to train it, exposing it to new data so that the model weights (or typically parts of them) get updated.
Introduction Training large language models (LLMs) is an involved process that requires planning, computational resources, and domain expertise. Data scientists, machine learning practitioners, and AI engineers alike can fall into common training or fine-tuning patterns that could compromise a model’s performance or scalability.
This post is divided into three parts; they are: • Why Attention is Needed • The Attention Operation • Multi-Head Attention (MHA) • Grouped-Query Attention (GQA) and Multi-Query Attention (MQA) Traditional neural networks struggle with long-range dependencies in sequences.
Ever felt like trying to find a needle in a haystack? That’s part of the process of building and optimizing machine learning models, particularly complex ones like ensembles and neural networks, where several hyperparameters need to be manually set by us before training them.
The rise of language models, and more specifically large language models (LLMs), has been of such a magnitude that it has permeated every aspect of modern AI applications — from chatbots and search engines to enterprise automation and coding assistants.
Versatile, interpretable, and effective for a variety of use cases, decision trees have been among the most well-established machine learning techniques for decades, widely used for classification and regression tasks.
This post is divided into three parts; they are: • Why Linear Layers and Activations are Needed in Transformers • Typical Design of the Feed-Forward Network • Variations of the Activation Functions The attention layer is the core function of a transformer model.
This post is divided into five parts; they are: • Understanding Positional Encodings • Sinusoidal Positional Encodings • Learned Positional Encodings • Rotary Positional Encodings (RoPE) • Relative Positional Encodings Consider these two sentences: "The fox jumps over the dog" and "The dog jumps over the fox".
Machine learning workflows typically involve plenty of numerical computations in the form of mathematical and algebraic operations upon data stored as large vectors, matrices, or even tensors — matrix counterparts with three or more dimensions.
Introduction Text-based adventure games have a timeless appeal. They allow players to imagine entire worlds, from shadowy dungeons and towering castles to futuristic spacecraft and mystic realms, all through the power of language.
This post is divided into five parts; they are: Naive Tokenization Stemming and Lemmatization Byte-Pair Encoding (BPE) WordPiece SentencePiece and Unigram The simplest form of tokenization splits text into tokens based on whitespace.
It would be difficult to argue that word embeddings — dense vector representations of words — have not dramatically revolutionized the field of natural language processing (NLP) by quantitatively capturing semantic relationships between words.
Quantization is a frequently used strategy applied to production machine learning models, particularly large and complex ones, to make them lightweight by reducing the numerical precision of the models parameters (weights) — usually from 32-bit floating-point to lower representations like 8-bit integers.
Artificial intelligence (AI) is an umbrella computer science discipline focused on building software systems capable of mimicking human or animal intelligence capabilities to solve a task.
This tutorial is in two parts; they are: Using DistilBart for Summarization Improving the Summarization Process Let's start with a fundamental implementation that demonstrates the key concepts of text summarization with DistilBart: import torch from transformers import AutoTokenizer, AutoModelForSeq2SeqLM class TextSummarizer: def __init__(self, model_name="sshleifer/distilbart-cnn-12-6"): """Initialize the summarizer with a pre-trained model.
It’s no secret that most advanced artificial intelligence solutions today are predominantly based on impressively powerful and complex models like transformers, diffusion models, and other deep learning architectures.
A lot (if not nearly all) of the success and progress made by many generative AI models nowadays, especially large language models (LLMs), is due to the stunning capabilities of their underlying architecture: an advanced deep learning-based architectural model called the
Last Updated on May 19, 2023 Large language models (LLMs) are recent advances in deep learning models to work on human languages. Some great use case of LLMs has been demonstrated. A large language model is a trained deep-learning model that understands and generates text in a human-like fashion. Behind the scene, it is a […] The post What are Large Language Models appeared first on MachineLearningMastery.com.
Ever wondered why your neural network seems to get stuck during training, or why it starts strong but fails to reach its full potential? The culprit might be your learning rate arguably one of the most important hyperparameters in machine learning.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































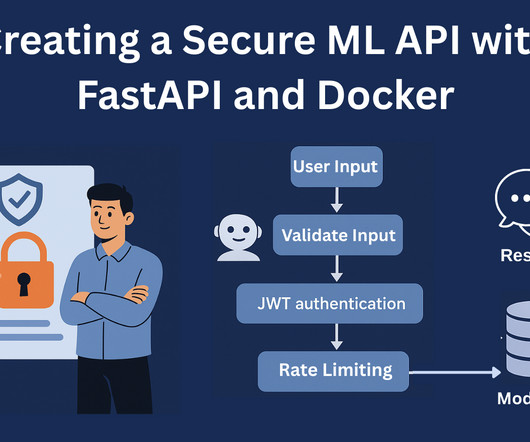




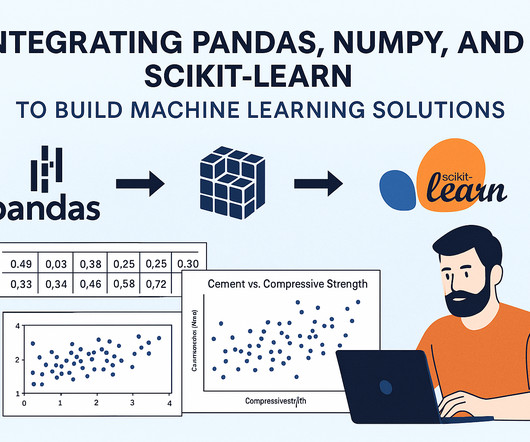






Let's personalize your content