

Transforming Your Data Pipeline with dbt(data build tool)
Analytics Vidhya
JUNE 14, 2024
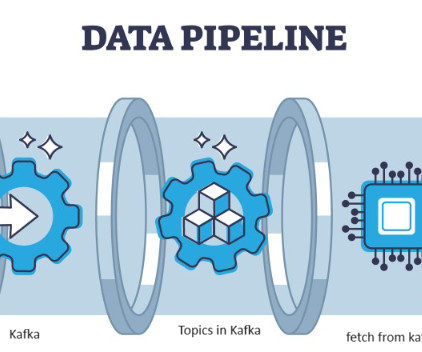
While many ETL tools exist, dbt (data build tool) is emerging as a game-changer. This article dives into the core functionalities of dbt, exploring its unique strengths and how […] The post Transforming Your Data Pipeline with dbt(data build tool) appeared first on Analytics Vidhya.









































Let's personalize your content