This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
One of my favorite learning resources for gaining an understanding for the mathematics behind deeplearning is "Math for DeepLearning" by Ronald T. If you're interested in getting quickly up to speed with how deeplearning algorithms work at a basic level, then this is the book for you.
Deeplearning GPU benchmarks has revolutionized the way we solve complex problems, from image recognition to natural language processing. CPUs, being widely available and cost-efficient, often serve […] The post Tools and Frameworks for DeepLearning GPU Benchmarks appeared first on Analytics Vidhya.
Deeplearning has revolutionised the AI field by allowing machines to grasp more in-depth information within our data. Deeplearning has been able to do this by replicating how our brain functions through the logic of neuron synapses.
This principle can be encoded in many model classes, and thus deeplearning is not as mysterious or different from other model classes as it might seem.
Your new best friend in your machine learning, deeplearning, and numerical computing journey. Hey there, fellow Python enthusiast! Have you ever wished your NumPy code run at supersonic speed? Think of it as NumPy with superpowers.
This post is divided into five parts; they are: • Why Normalization is Needed in Transformers • LayerNorm and Its Implementation • Adaptive LayerNorm • RMS Norm and Its Implementation • Using PyTorch's Built-in Normalization Normalization layers improve model quality in deeplearning.
We’re in close contact with the movers and shakers making waves in the technology areas of big data, data science, machine learning, AI and deeplearning. The team here at insideAI News is deeply entrenched in keeping the pulse of the big data ecosystem of companies from around the globe.
We’re in close contact with the movers and shakers making waves in the technology areas of big data, data science, machine learning, AI and deeplearning. The team here at insideBIGDATA is deeply entrenched in keeping the pulse of the big data ecosystem of companies from around the globe.
We’re in close contact with the movers and shakers making waves in the technology areas of big data, data science, machine learning, AI and deeplearning. The team here at insideBIGDATA is deeply entrenched in keeping the pulse of the big data ecosystem of companies from around the globe.
This paper is a major turning point in deeplearning research. In this video presentation, Mohammad Namvarpour presents a comprehensive study on Ashish Vaswani and his coauthors' renowned paper, “Attention Is All You Need.”
Today at NVIDIA GTC, Hewlett Packard Enterprise (NYSE: HPE) announced updates to one of the industry’s most comprehensive AI-native portfolios to advance the operationalization of generative AI (GenAI), deeplearning, and machine learning (ML) applications.
In this regular column, we’ll bring you all the latest industry news centered around our main topics of focus: big data, data science, machine learning, AI, and deeplearning. Our industry is constantly accelerating with new products and services being announced everyday.
As part of #OpenSourceWeek Day 4, DeepSeek introduces 2 new tools to make deeplearning faster and more efficient: DualPipe and EPLB. These tools help improve how computers handle calculations and communication during training, making the process smoother and quicker.
They use deeplearning techniques, particularly transformers, to perform various language tasks such as translation, text generation, and summarization. […] The post 12 Free And Paid LLMs for Your Daily Tasks appeared first on Analytics Vidhya.
We’re in close contact with the movers and shakers making waves in the technology areas of big data, data science, machine learning, AI and deeplearning. The team here at insideBIGDATA is deeply entrenched in keeping the pulse of the big data ecosystem of companies from around the globe.
On Thursday, Google and the Computer History Museum (CHM) jointly released the source code for AlexNet , the convolutional neural network (CNN) that many credit with transforming the AI field in 2012 by proving that "deeplearning" could achieve things conventional AI techniques could not.
This week, the Thirteenth International Conference on Learning Representations (ICLR) will be held in Singapore. ICLR brings together leading experts on deeplearning and the application of representation
Deeplearning intelligent agents are revolutionizing the concept of machine and technology around us. Cognitive systems are able to reason, decide, operate and even solve problems without human interferences.
A lot (if not nearly all) of the success and progress made by many generative AI models nowadays, especially large language models (LLMs), is due to the stunning capabilities of their underlying architecture: an advanced deeplearning-based architectural model called the
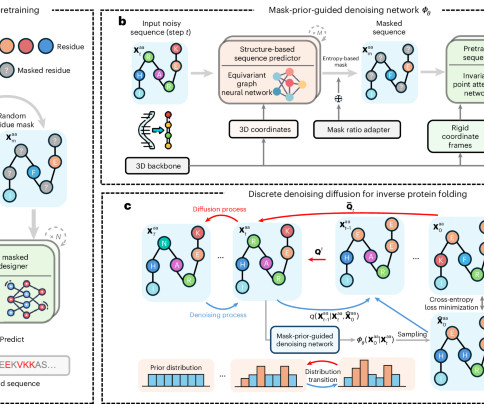
Inverse protein folding generates valid amino acid sequences that can fold into a desired protein structure, with recent deeplearning advances showing strong potential and competitive performance. However, challenges remain, such as predicting elements with high structural uncertainty, including disordered regions.
How Kumo is generalizing transformers for databases Kumo’s approach, “relational deeplearning,” sidesteps this manual process with two key insights. Relational deeplearning (source: Kumo AI) Second, Kumo generalized the transformer architecture , the engine behind LLMs, to learn directly from this graph representation.
Transformer is a deeplearning architecture that is very popular in natural language processing (NLP) tasks. Specifically, you will learn: What problems do the transformer models address What is… It is a type of neural network that is designed to process sequential data, such as text.
Some researchers say that deep-learning ‘foundation’ models will revolutionize the field — but others are not so sure. Some researchers say that deep-learning ‘foundation’ models will revolutionize the field — but others are not so sure.
The notable features of the IEEE conference are: Cutting-Edge AI Research & Innovations Gain exclusive insights into the latest breakthroughs in artificial intelligence, including advancements in deeplearning, NLP, and AI-driven automation.
Thats according to researchers from Mass General Brigham, who developed a deep-learning algorithm called FaceAge. A simple selfie could hold hidden clues to ones biological age and even how long theyll live. Using a photo of someones face, the artificial intelligence tool generates predictions
Relational Graph Transformers represent the next evolution in Relational DeepLearning, allowing AI systems to seamlessly navigate and learn from data spread across multiple tables.
Jax: Jax is a high-performance numerical computation library for Python with a focus on machine learning and deeplearning research. It is developed by Google AI and has been used to achieve state-of-the-art results in a variety of machine learning tasks, including generative AI.
The canonical deeplearning approach for learning requires computing a gradient term at each layer by back-propagating the error signal from the output towards each learnable parameter.
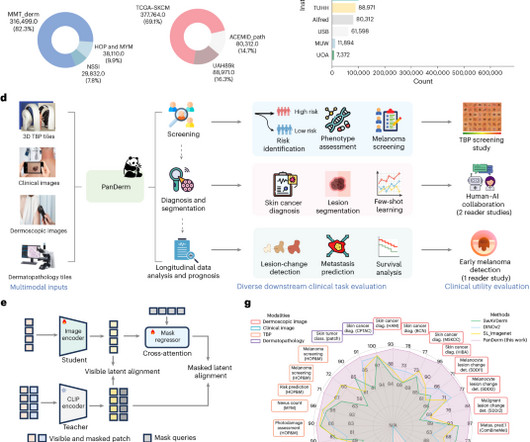
While current deeplearning models excel at specific tasks such as skin cancer diagnosis from dermoscopic images, they struggle to meet the complex, multimodal requirements of clinical practice.
This led us to refer to research highlighting how image resolution impacts deeplearning models. First fix: Mixing image resolutions One thing we noticed was how much image quality affected the model’s output. Users uploaded all kinds of images ranging from sharp and high-resolution to blurry.
The next step for researchers was to use deeplearning approaches such as NeRFs and 3D Gaussian Splatting, which have shown promising results in novel view synthesis, computer graphics, high-resolution image generation, and real-time rendering. In short, it’s a basic reconstruction. Or requires a degree in computer science?
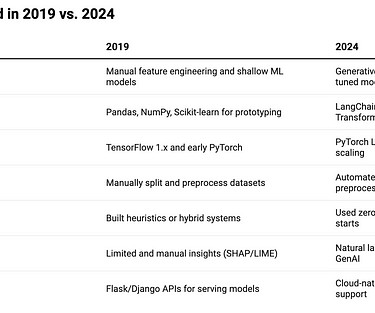
Tasks like splitting timestamps for session analysis or encoding categorical variables had to be scripted manually.Model Building: I would use Scikit-learn or XGBoost for collaborative filtering and content-based methods. For deeplearning, I used TensorFlow 1.x,
It also includes free machine learning books, courses, blogs, newsletters, and links to local meetups and communities. Awesome Machine Learning Tutorials: Practical Guides and Articles Link: ujjwalkarn/Machine-Learning-Tutorials A collection of machine learning and deeplearning tutorials, articles, and resources.
Key techniques in text mining Text mining has significantly advanced with the introduction of deeplearning. This development allows for more nuanced and sophisticated analyses as neural networks iteratively learn from vast datasets. Factors like syntax, semantics, slang, and jargon complicate the analysis.
Currently, shes working on learning and sharing her knowledge with the developer community by authoring tutorials, how-to guides, opinion pieces, and more. Bala also creates engaging resource overviews and coding tutorials.
This post is divided into three parts; they are: • Why Skip Connections are Needed in Transformers • Implementation of Skip Connections in Transformer Models • Pre-norm vs Post-norm Transformer Architectures Transformer models, like other deeplearning models, stack many layers on top of each other.
Long short-term memory (LSTM) networks have revolutionized the field of deeplearning by providing advanced solutions to processing sequence data. Applications of LSTM networks LSTM networks boast a variety of applications across multiple domains in deeplearning, showcasing their adaptability and effectiveness.
Figure 13: Multi-Object Tracking for Pose Estimation (source: output video generated by running the above code) How to Train with YOLO11 Training a deeplearning model is a crucial step in building a solution for tasks like object detection. Or has to involve complex mathematics and equations? Or requires a degree in computer science?
These methods may leverage machine learning, deeplearning, large language models, network science, and other related computational techniques for diverse cybersecurity applications. TAISAP also aims to publish high-quality scholarly articles that contribute to the development of AI-enabled analytical methods.
Course information: 86+ total classes 115+ hours hours of on-demand code walkthrough videos Last updated: March 2025 4.84 (128 Ratings) 16,000+ Students Enrolled I strongly believe that if you had the right teacher you could master computer vision and deeplearning. Or has to involve complex mathematics and equations?
Course information: 86 total classes 115+ hours of on-demand code walkthrough videos Last updated: October 2024 4.84 (128 Ratings) 16,000+ Students Enrolled I strongly believe that if you had the right teacher you could master computer vision and deeplearning. Or has to involve complex mathematics and equations? Download the code!
Dropout in deeplearning In deeplearning, dropout is a regularization technique where random neurons are excluded during training. This process encourages the model to learn robust features that are not reliant on any single neuron, thereby improving generalization.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.














































Let's personalize your content