

Build a Scalable Data Pipeline with Apache Kafka
Analytics Vidhya
MARCH 10, 2023
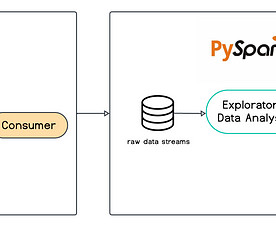
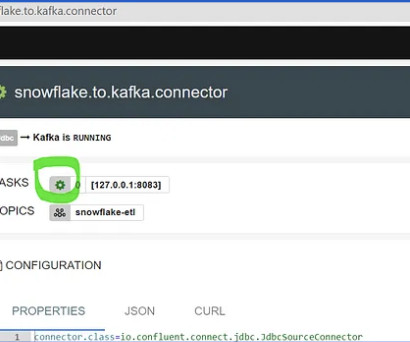
Introduction Apache Kafka is a framework for dealing with many real-time data streams in a way that is spread out. It was made on LinkedIn and shared with the public in 2011.





















Let's personalize your content