This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Reinforcement Learning from Human Feedback (RLHF) is a popular technique used to align AI systems with human preferences by training them using feedback from people, rather than relying solely on predefined reward functions. Instead of coding every desirable behavior manually (which is often infeasible in complex tasks) RLHF allows models, especially large language models (LLMs), to learn from examples of what humans consider good or bad outputs.
Machine unlearning is a promising approach to mitigate undesirable memorization of training data in ML models. In this post, we will discuss our work (which appeared at ICLR 2025) demonstrating that existing approaches for unlearning in LLMs are surprisingly susceptible to a simple set of benign relearning attacks : With access to only a small and potentially loosely related set of data, we find that we can jog the memory of unlearned models to reverse the effects of unlearning.
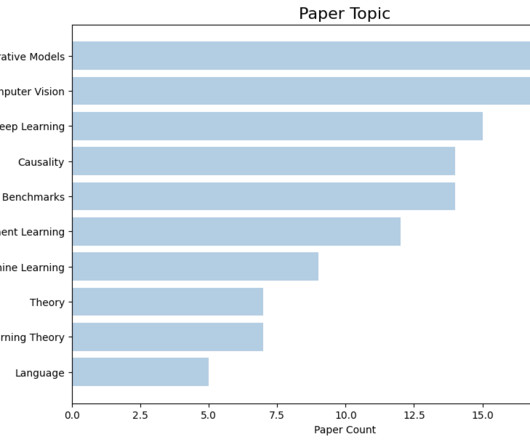
CMU researchers are presenting 143 papers at the Thirteenth International Conference on Learning Representations (ICLR 2025), held from April 24 – 28 at the Singapore EXPO. Here is a quick overview of the areas our researchers are working on: And here are our most frequent collaborator institutions: Table of Contents Oral Papers Spotlight Papers Poster Papers Alignment, Fairness, Safety, Privacy, And Societal Considerations Applications to Computer Vision, Audio, Language, And Other Modali
Play against Allie on lichess ! Introduction In 1948, Alan Turning designed what might be the first chess playing AI , a paper program that Turing himself acted as the computer for. Since then, chess has been a testbed for nearly every generation of AI advancement. After decades of improvement, today’s top chess engines like Stockfish and AlphaZero have far surpassed the capabilities of even the strongest human grandmasters.
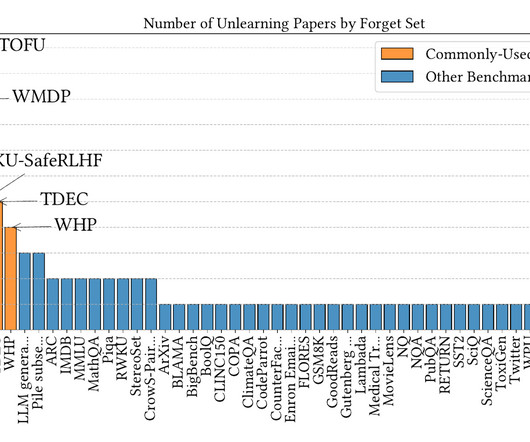
TL;DR: “Machine unlearning” aims to remove data from models without retraining the model completely. Unfortunately, state-of-the-art benchmarks for evaluating unlearning in LLMs are flawed, especially because they separately test “forget queries” and “retain queries” without examining potential dependencies between forget and retain data.
Figure 1. Copilot Arena is a VSCode extension that collects human preferences of code directly from developers. As model capabilities improve, large language models (LLMs) are increasingly integrated into user environments and workflows. In particular, software developers code with LLM-powered tools in integrated development environments such as VS Code, IntelliJ, or Eclipse.
Figure 1: Training models to optimize test-time compute and learn how to discover correct responses, as opposed to the traditional learning paradigm of learning what answer to output. The major strategy to improve large language models (LLMs) thus far has been to use more and more high-quality data for supervised fine-tuning (SFT) or reinforcement learning (RL).
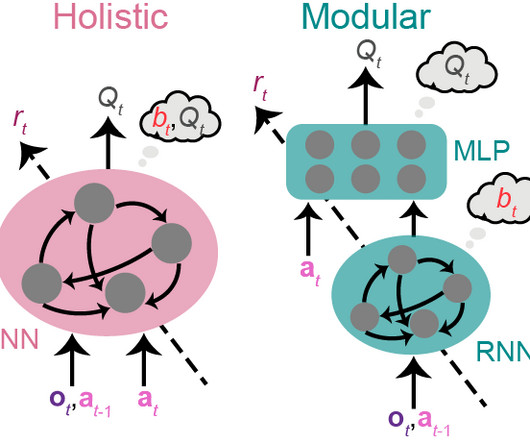
TL;DR: The brain may have evolved a modular architecture for daily tasks, with circuits featuring functionally specialized modules that match the task structure. We hypothesize that this architecture enables better learning and generalization than architectures with less specialized modules. To test this, we trained reinforcement learning agents with various neural architectures on a naturalistic navigation task.
TL;DR: At SmashLab , we’re creating an intelligent assistant that uses the sensors in a smartwatch to support physical tasks such as cooking and DIY. This blog post explores how we use less intrusive scene understandingcompared to camerasto enable helpful, context-aware interactions for task execution in their daily lives. Thinking about AI assistants for tasks beyond just the digital world?
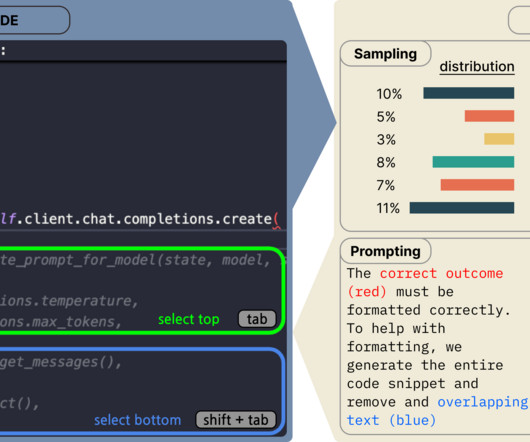
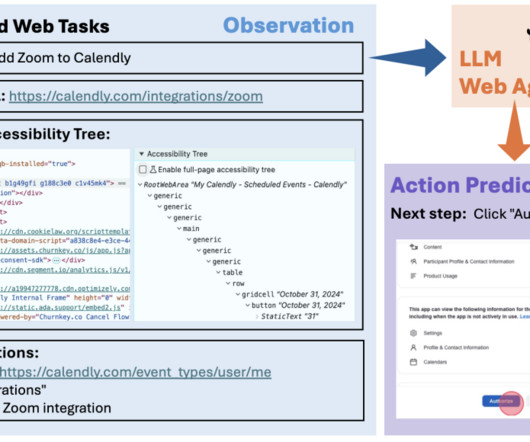
TL;DR: LLM web agents are designed to predict a sequence of actions to complete a user-specified task. Most existing agents are built on top of general-purpose, proprietary models like GPT-4 and rely heavily on prompt engineering. We demonstrate that fine-tuning open-source LLMs using a large set of high-quality, real- world workflow data can improve performance while using a smaller LLM backbone, which can reduce serving costs.
Carnegie Mellon University is proud to present 194 papers at the 38th conference on Neural Information Processing Systems (NeurIPS 2024), held from December 10-15 at the Vancouver Convention Center. Here is a quick overview of the areas our researchers are working on: Here are some of our top collaborator institutions: Table of Contents Oral Papers Spotlight Papers Poster Papers Causality Computational Biology Computer Vision Computer Vision (Image Generation) Computer Vision (Video Generation)
TL;DR: Landmines pose a persistent threat and hinder development in over 70 war-affected countries. Humanitarian demining aims to clear contaminated areas, but progress is slow: at the current pace, it will take 1,100 years to fully demine the planet. In close collaboration with the UN and local NGOs, we co-develop an interpretable predictive tool for landmine contamination to identify hazardous clusters under geographic and budget constraints, experimentally reducing false alarms and clearance
Summary. Recent research has shown that large language models (LLMs) such as ChatGPT are susceptible to jailbreaking attacks, wherein malicious users fool an LLM into generating toxic content (e.g., bomb-building instructions). However, these attacks are generally limited to producing text. In this blog post, we consider the possibility of attacks on LLM-controlled robots, which, if jailbroken, could be fooled into causing physical harm in the real world.
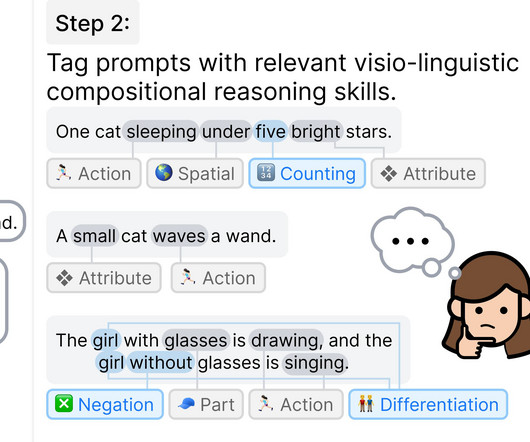
Introduction Text-to-image/video models like Midjourney, Imagen3, Stable Diffusion, and Sora can generate aesthetic, photo-realistic visuals from natural language prompts, for example, given “ Several giant woolly mammoths approach, treading through a snowy meadow… ”, Sora generates: But how do we know if these models generate what we desire? For example, if the prompt is “ The brown dog chases the black dog around a tree ”, how can we tell if the model shows the dogs “ chasing around a tree ” r
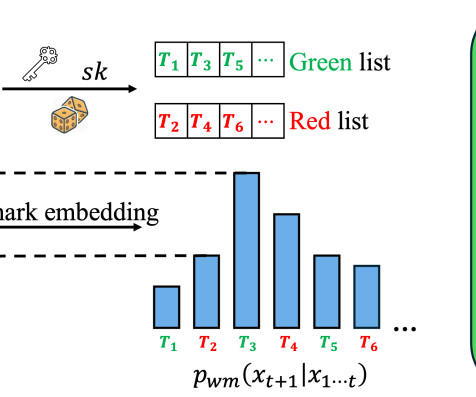
Advances in generative models have made it possible for AI-generated text, code, and images to mirror human-generated content in many applications. Watermarking , a technique that embeds information in the output of a model to verify its source, aims to mitigate the misuse of such AI-generated content. Current state-of-the-art watermarking schemes embed watermarks by slightly perturbing probabilities of the LLM’s output tokens, which can be detected via statistical testing during verification.
Introduction A central question in the discussion of large language models (LLMs) concerns the extent to which they memorize their training data versus how they generalize to new tasks and settings. Most practitioners seem to (at least informally) believe that LLMs do some degree of both: they clearly memorize parts of the training data—for example, they are often able to reproduce large portions of training data verbatim [ Carlini et al., 2023 ]—but they also seem to learn from this data, allow
Causal inference is the process of determining whether and how a cause leads to an effect, typically using statistical methods to distinguish correlation from causation. Learning causal relationships from data is an important task across a wide variety of domains ranging from healthcare and drug development, to online advertising and e-commerce. As a result, there has been much work in the literature on economics, statistics, computer science, and public policy on designing algorithms and method
Recently, our CMU-MATH team proudly clinched 2nd place in the Artificial Intelligence Mathematical Olympiad (AIMO) out of 1,161 participating teams, earning a prize of $65,536! This prestigious competition aims to revolutionize AI in mathematical problem-solving, with the ultimate goal of building a publicly-shared AI model capable of winning a gold medal in the International Mathematical Olympiad (IMO).
TL;DR : Off-the-shelf text spotting and re-identification models fail in basic off-road racing settings, even more so during muddy events. Making matters worse, there aren’t any public datasets to evaluate or improve models in this domain. To this end, we introduce datasets, benchmarks, and methods for the challenging off-road racing setting. In the dynamic world of sports analytics, machine learning (ML) systems play a pivotal role, transforming vast arrays of visual data into actionable
TL;DR : Off-the-shelf text spotting and re-identification models fail in basic off-road racing settings, even more so during muddy events. Making matters worse, there aren’t any public datasets to tune or improve models in this domain. To this end, we introduce datasets, benchmarks, and methods for the challenging off-road racing setting. In the dynamic world of sports analytics, machine learning (ML) systems play a pivotal role, transforming vast arrays of visual data into actionable insi
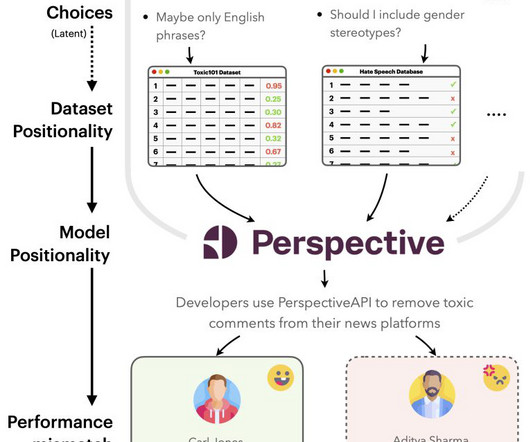
TLDR; Design biases in NLP systems, such as performance differences for different populations, often stem from their creator’s positionality, i.e., views and lived experiences shaped by identity and background. Despite the prevalence and risks of design biases, they are hard to quantify because researcher, system, and dataset positionality are often unobserved.
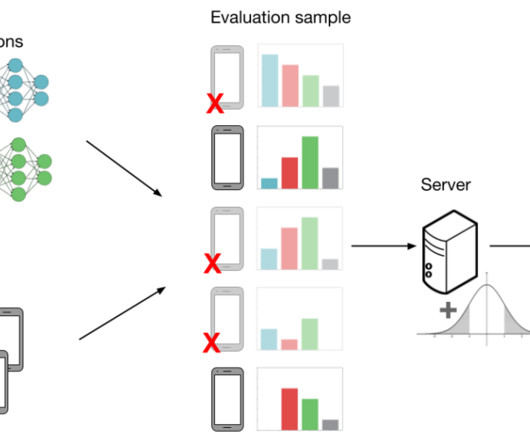
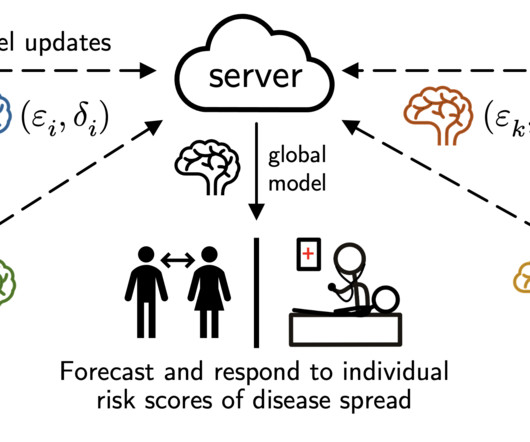
Evaluating models in federated networks is challenging due to factors such as client subsampling, data heterogeneity, and privacy. These factors introduce noise that can affect hyperparameter tuning algorithms and lead to suboptimal model selection. Hyperparameter tuning is critical to the success of cross-device federated learning applications. Unfortunately, federated networks face issues of scale, heterogeneity, and privacy, which introduce noise in the tuning process and make it difficult to
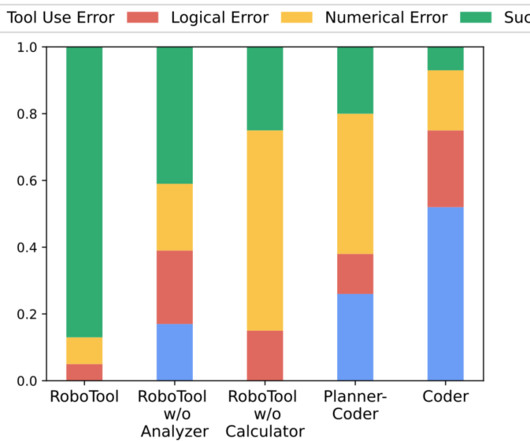
TLDR: We introduce RoboTool , enabling robots to use tools creatively with large language models, which solves long-horizon hybrid discrete-continuous planning problems with the environment- and embodiment-related constraints. Tool use is an essential hallmark of advanced intelligence. Some animals can use tools to achieve goals that are infeasible without tools.
Alexander Goldberg , Ivan Stelmakh, Kyunghyun Cho, Alice Oh, Alekh Agarwal, Danielle Belgrave, and Nihar Shah Is it possible to reliably evaluate the quality of peer reviews? We study peer reviewing of peer reviews driven by two primary motivations: (i) Incentivizing reviewers to provide high-quality reviews is an important open problem. The ability to reliably assess the quality of reviews can help design such incentive mechanisms.
Illustration depicting the process of a human and a large language model working together to find failure cases in a (not necessarily different) large language model. Overview In the era of ChatGPT, where people increasingly take assistance from a large language model (LLM) in day-to-day tasks, rigorously auditing these models is of utmost importance.
TLDR: Current SOTA methods for scene understanding, though impressive, often fail to decompose out-of-distribution scenes. In our ICML paper, Slot-TTA ( [link] ) we find that optimizing per test sample over reconstruction loss improves scene decomposition accuracy. Problem Statement: In machine learning, we often assume the train and test split are IID samples from the same distribution.
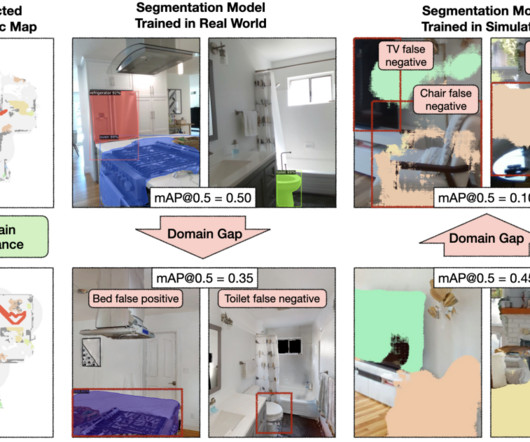
Empirical study: We evaluated three approaches for robots to navigate to objects in six visually diverse homes. TLDR : Semantic navigation is necessary to deploy mobile robots in uncontrolled environments like our homes, schools, and hospitals. Many learning-based approaches have been proposed in response to the lack of semantic understanding of the classical pipeline for spatial navigation.
ReLM enables writing tests that are guaranteed to come from the set of valid strings, such as dates. Without ReLM, LLMs are free to complete prompts with non-date answers, which are difficult to assess. TL;DR: While large language models (LLMs) have been touted for their ability to generate natural-sounding text, there are concerns around potential negative effects of LLMs such as data memorization, bias, and inappropriate language.
TL;DR: We study the use of differential privacy in personalized, cross-silo federated learning ( NeurIPS’22 ), explain how these insights led us to develop a 1st place solution in the US/UK Privacy-Enhancing Technologies (PETs) Prize Challenge , and share challenges and lessons learned along the way. If you are feeling adventurous, checkout the extended version of this post with more technical details!
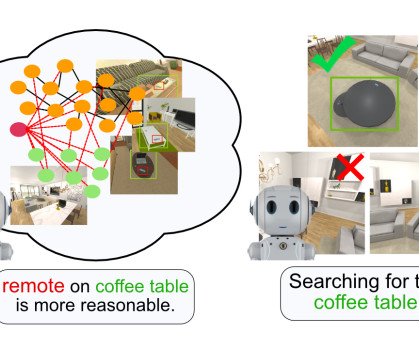
Example of embodied commonsense reasoning. A robot proactively identifies a remote on the floor and knows it is out of place without instruction. Then, the robot figures out where to place it in the scene and manipulates it there. For robots to operate effectively in the world, they should be more than explicit step-by-step instruction followers. Robots should take actions in situations when there is a clear violation of the normal circumstances and be able to infer relevant context from partial
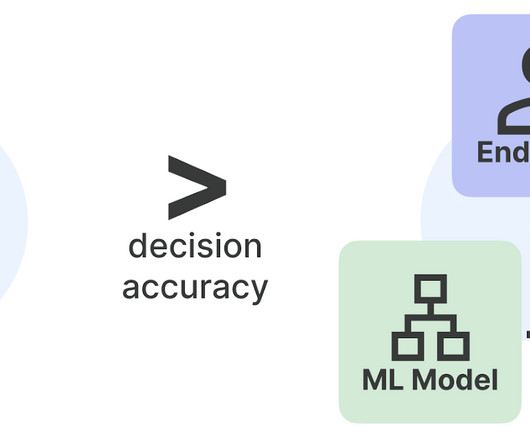
Figure 1. This blog post discusses the effectiveness of black-box model explanations in aiding end users to make decisions. We observe that explanations do not in fact help with concrete applications such as fraud detection and paper matching for peer review. Our work further motivates novel directions for developing and evaluating tools to support human-ML interactions.
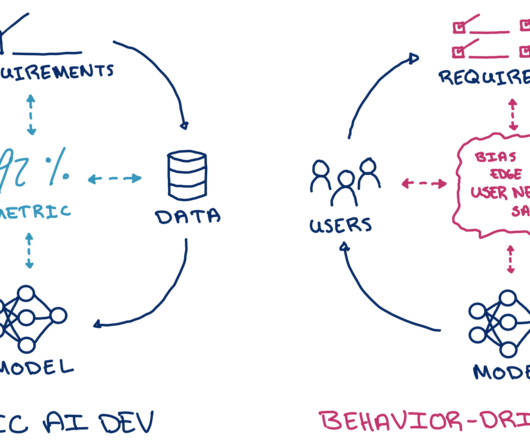
Figure 1: Behavior-driven AI development centers model iteration on evaluating and improving specific real-world use cases. It has never been easier to prototype AI-driven systems. With a bit of programming knowledge and a couple of hours, you can spin up a chatbot for your notes , a text-based image editor , or a tool for summarizing customer feedback.
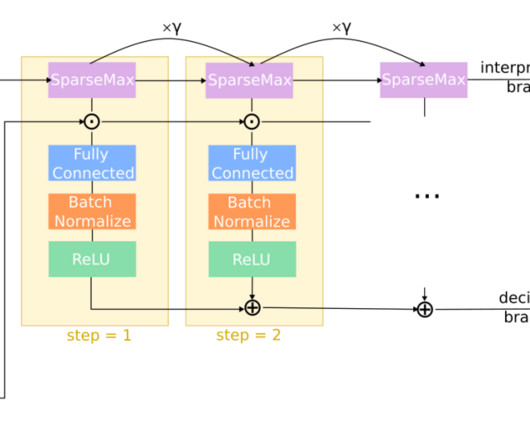
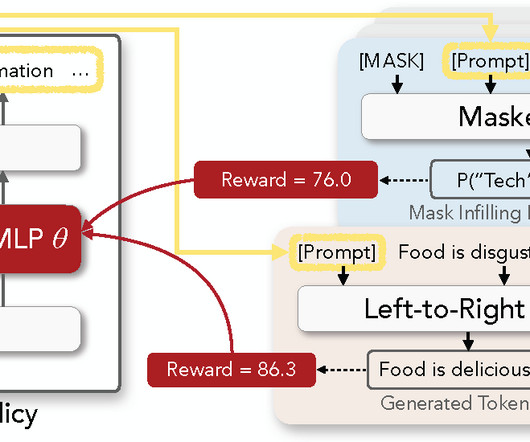
Figure 1 : Overview of RL Prompt for discrete prompt optimization. All language models (LMs) are frozen. We build our policy network by training a task-specific multi-layer perceptron (MLP) network inserted into a frozen pre-trained LM. The figure above illustrates 1) generation of a prompt ( left ), 2) example usages in a masked LM for classification ( top right ) and a left-to-right LM for generation ( bottom right ), and 3) update of the MLP using RL reward signals ( red arrows ).
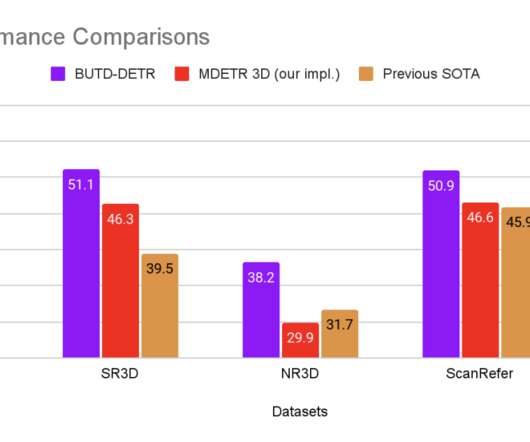
We perform open vocabulary detection of the objects mentioned in the sentence using both bottom-up and top-down feedback. Object detection is the fundamental computer vision task of finding all “objects” that are present in a visual scene. However, this raises the question, what is an object? Typically, this question is side-stepped by defining a vocabulary of categories and then training a model to detect instances of this vocabulary.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content