This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Companies are spending a lot of money on data and analytics capabilities, creating more and more data products for people inside and outside the company. These products rely on a tangle of datapipelines, each a choreography of software executions transporting data from one place to another.
DataObservability and Data Quality are two key aspects of data management. The focus of this blog is going to be on DataObservability tools and their key framework. The growing landscape of technology has motivated organizations to adopt newer ways to harness the power of data.
Author’s note: this article about dataobservability and its role in building trusted data has been adapted from an article originally published in Enterprise Management 360. Is your data ready to use? That’s what makes this a critical element of a robust data integrity strategy. What is DataObservability?
quintillion exabytes of data every day. That information resides in multiple systems, including legacy on-premises systems, cloud applications, and hybrid environments. It includes streaming data from smart devices and IoT sensors, mobile trace data, and more. Data is the fuel that feeds digital transformation.
Summary: This blog explains how to build efficient datapipelines, detailing each step from data collection to final delivery. Introduction Datapipelines play a pivotal role in modern data architecture by seamlessly transporting and transforming raw data into valuable insights.
In this blog, we are going to unfold the two key aspects of data management that is DataObservability and Data Quality. Data is the lifeblood of the digital age. Today, every organization tries to explore the significant aspects of data and its applications. What is DataObservability and its Significance?
quintillion exabytes of data every da y. That information resides in multiple systems, including legacy on-premises systems, cloud applications, and hybrid environments. It includes streaming data from smart devices and IoT sensors, mobile trace data, and more. Data is the fuel that feeds digital transformation.
Suppose you’re in charge of maintaining a large set of datapipelines from cloud storage or streaming data into a data warehouse. How can you ensure that your data meets expectations after every transformation? That’s where data quality testing comes in.
In part one of this article, we discussed how data testing can specifically test a data object (e.g., table, column, metadata) at one particular point in the datapipeline.
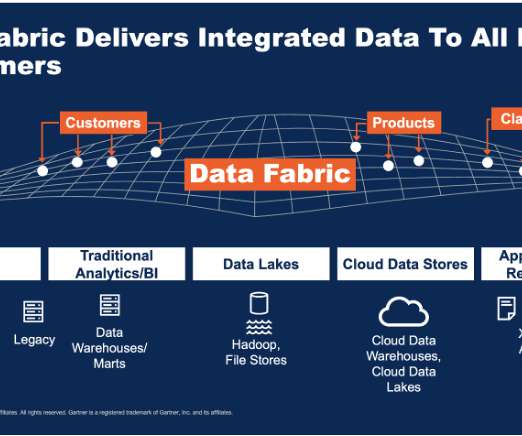
Implementing a data fabric architecture is the answer. What is a data fabric? Data fabric is defined by IBM as “an architecture that facilitates the end-to-end integration of various datapipelines and cloud environments through the use of intelligent and automated systems.”
This is in contrast to batch processing, where data is collected and processed at regular intervals. Real-time data is becoming increasingly important as organizations look to make faster and more informed decisions. Data engineers will need to develop the skills and tools to collect, store, and process real-time data.
Today, businesses and individuals expect instant access to information and swift delivery of services. The same expectation applies to data, […] The post Leveraging DataPipelines to Meet the Needs of the Business: Why the Speed of Data Matters appeared first on DATAVERSITY.
A data catalog serves the same purpose. It organizes the information your company has on hand so you can find it easily. By using metadata (or short descriptions), data catalogs help companies gather, organize, retrieve, and manage information. It helps you locate and discover data that fit your search criteria.
Data lineage helps during these investigations. Because lineage creates an environment where reports and data can be trusted, teams can make more informed decisions. Data lineage provides that reliability—and more. That’s why datapipelineobservability is so important. Stakeholders?
Key Takeaways Data quality ensures your data is accurate, complete, reliable, and up to date – powering AI conclusions that reduce costs and increase revenue and compliance. Dataobservability continuously monitors datapipelines and alerts you to errors and anomalies. What does “quality” data mean, exactly?
Everyone would be using the same data set to make informed decisions which may range from goal setting to prioritizing investments in sustainability. A data fabric is an architectural approach designed to simplify data access to facilitate self-service data consumption at scale.
Alation and Bigeye have partnered to bring dataobservability and data quality monitoring into the data catalog. Read to learn how our newly combined capabilities put more trustworthy, quality data into the hands of those who are best equipped to leverage it. Extract data quality information.
Alation and Soda are excited to announce a new partnership, which will bring powerful data-quality capabilities into the data catalog. Soda’s dataobservability platform empowers data teams to discover and collaboratively resolve data issues quickly. Do we have end-to-end datapipeline control?
When the job is complete, you can see more job information, including model name, job duration, status, and locations of input and output data. You can check the status of your batch inference job by choosing the corresponding job name on the Amazon Bedrock console.
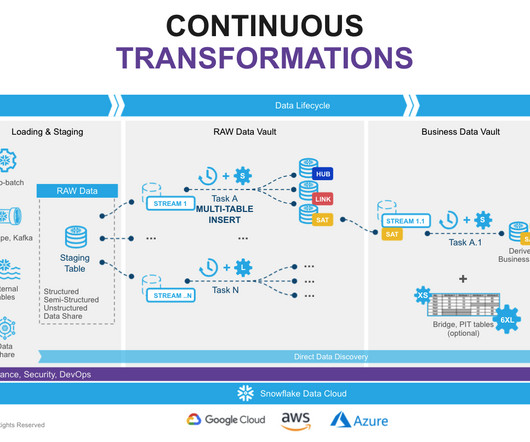
The implementation of a data vault architecture requires the integration of multiple technologies to effectively support the design principles and meet the organization’s requirements. Business data vault: Data vault objects with soft business rules applied. Information Mart: A layer of consumer-oriented models.
Can you debug system information? Metadata management : Robust metadata management capabilities enable you to associate relevant information, such as dataset descriptions, annotations, preprocessing steps, and licensing details, with the datasets, facilitating better organization and understanding of the data.
It’s important to note that end-to-end dataobservability of your complex datapipelines is a necessity if you’re planning to fully automate the monitoring, diagnosis, and remediation of data quality issues. Get your copy today to be on your way to more strategic, informed, and successful data quality initiatives.
So, if we are training a LLM on proprietary data about an enterprise’s customers, we can run into situations where the consumption of that model could be used to leak sensitive information. In-model learning data Many simple AI models have a training phase and then a deployment phase during which training is paused.
So, instead of wandering the aisles in hopes you’ll stumble across the book, you can walk straight to it and get the information you want much faster. An enterprise data catalog does all that a library inventory system does – namely streamlining data discovery and access across data sources – and a lot more.
The more complete, accurate and consistent a dataset is, the more informed business intelligence and business processes become. The different types of data integrity There are two main categories of data integrity: Physical data integrity and logical data integrity. Are there missing data elements or blank fields?
Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high data quality, and informed decision-making capabilities. Introduction In today’s business landscape, data integration is vital. It is part of IBM’s Infosphere Information Server ecosystem.
As a result, Gartner estimates that poor data quality costs organizations an average of $13 million annually. High-quality data significantly reduces the risk of costly errors, and the resulting penalties or legal issues. Completeness determines whether all required data fields are filled with appropriate and valid information.
With the Data Enrichment service of the Suite, you can add rich, valuable context for analysis by attaching attributes from hundreds of our curated, up-to-date datasets. And when you search for enriched values using the PreciselyID, you can find the most relevant information – and make better, smarter decisions – faster.
While the concept of data mesh as a data architecture model has been around for a while, it was hard to define how to implement it easily and at scale. Two data catalogs went open-source this year, changing how companies manage their datapipeline. The departments closest to data should own it.
Missing Data Incomplete datasets with missing values can distort the training process and lead to inaccurate models. Missing data can occur due to various reasons, such as data entry errors, loss of information, or non-responses in surveys. Bias in data can result in unfair and discriminatory outcomes.
You wished the traceability could have been better to relieve […] The post Observability: Traceability for Distributed Systems appeared first on DATAVERSITY. Have you ever waited for that one expensive parcel that shows “shipped,” but you have no clue where it is? But wait, 11 days later, you have it at your doorstep.
You wished the traceability could have been better to relieve […] The post Observability: Traceability for Distributed Systems appeared first on DATAVERSITY. Have you ever waited for that one expensive parcel that shows “shipped,” but you have no clue where it is? But wait, 11 days later, you have it at your doorstep.
Summary: Data engineering tools streamline data collection, storage, and processing. Learning these tools is crucial for building scalable datapipelines. offers Data Science courses covering these tools with a job guarantee for career growth. What Does a Data Engineer Do?
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.






































Let's personalize your content