This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Continuous Integration and Continuous Delivery (CI/CD) for DataPipelines: It is a Game-Changer with AnalyticsCreator! The need for efficient and reliable datapipelines is paramount in datascience and data engineering. They transform data into a consistent format for users to consume.
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Spark offers a rich set of libraries for data processing, machine learning, graph processing, and stream processing.
Datagovernance challenges Maintaining consistent datagovernance across different systems is crucial but complex. The company aims to integrate additional data sources, including other mission-critical systems, into ODAP. The following diagram shows a basic layout of how the solution works.
This will become more important as the volume of this data grows in scale. DataGovernanceDatagovernance is the process of managing data to ensure its quality, accuracy, and security. Datagovernance is becoming increasingly important as organizations become more reliant on data.
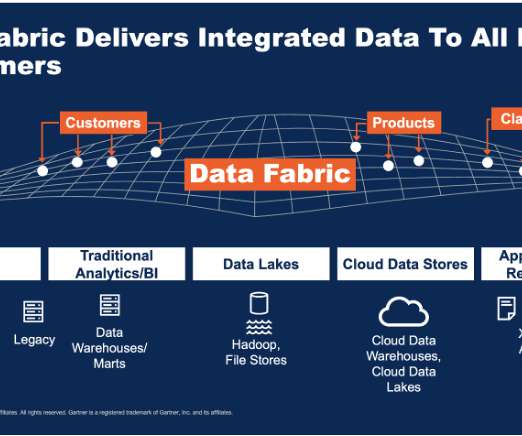
Implementing a data fabric architecture is the answer. What is a data fabric? Data fabric is defined by IBM as “an architecture that facilitates the end-to-end integration of various datapipelines and cloud environments through the use of intelligent and automated systems.”
This past week, I had the pleasure of hosting DataGovernance for Dummies author Jonathan Reichental for a fireside chat , along with Denise Swanson , DataGovernance lead at Alation. Can you have proper data management without establishing a formal datagovernance program?
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Read more to know.
This individual is responsible for building and maintaining the infrastructure that stores and processes data; the kinds of data can be diverse, but most commonly it will be structured and unstructured data. They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable.
This shift leverages the capabilities of modern data warehouses, enabling faster data ingestion and reducing the complexities associated with traditional transformation-heavy ETL processes. These platforms provide a unified view of data, enabling businesses to derive insights from diverse datasets efficiently. Image credit ) 5.
With built-in components and integration with Google Cloud services, Vertex AI simplifies the end-to-end machine learning process, making it easier for datascience teams to build and deploy models at scale. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy datascience projects.
IBM Cloud Pak for Data Express solutions provide new clients with affordable and high impact capabilities to expeditiously explore and validate the path to become a data-driven enterprise. IBM Cloud Pak for Data Express solutions offer clients a simple on ramp to start realizing the business value of a modern architecture.
Key components include data modelling, warehousing, pipelines, and integration. Effective datagovernance enhances quality and security throughout the data lifecycle. What is Data Engineering? They are crucial in ensuring data is readily available for analysis and reporting. from 2025 to 2030.
In particular, its progress depends on the availability of related technologies that make the handling of huge volumes of data possible. These technologies include the following: Datagovernance and management — It is crucial to have a solid data management system and governance practices to ensure data accuracy, consistency, and security.
A potential option is to use an ELT system — extract, load, and transform — to interact with the data on an as-needed basis. It may conflict with your datagovernance policy (more on that below), but it may be valuable in establishing a broader view of the data and directing you toward better data sets for your main models.
What is Data Observability? It is the practice of monitoring, tracking, and ensuring data quality, reliability, and performance as it moves through an organization’s datapipelines and systems. Data quality tools help maintain high data quality standards. Tools Used in Data Observability?
This involves creating data validation rules, monitoring data quality, and implementing processes to correct any errors that are identified. Creating datapipelines and workflows Data engineers create datapipelines and workflows that enable data to be collected, processed, and analyzed efficiently.
In today’s fast-paced business environment, the significance of Data Observability cannot be overstated. Data Observability enables organizations to detect anomalies, troubleshoot issues, and maintain datapipelines effectively. How Are Data Quality and Data Observability Similar—and How Are They Different?
It helps companies streamline and automate the end-to-end ML lifecycle, which includes data collection, model creation (built on data sources from the software development lifecycle), model deployment, model orchestration, health monitoring and datagovernance processes.
And even though Santa had made the leap to the data cloud — using Snowflake of course — making a list of all the data turned out to be tougher than finding a polar bear in a snowstorm. And Santa was hoping to make 2021 his most data-driven year yet. For the first time, datagovernance was no longer a naughty concept.
These virtual, self-paced resources will help attendees brush up on essential datascience and AI skills before diving into the main event. Attendees can immerse themselves in hands-on training sessions, workshops, and deep dives into AI engineering, large language models, and datascience best practices.
As you can imagine, datascience is a pretty loose term or big tent idea overall. Though just about every industry imaginable utilizes the skills of a data-focused professional, each has its own challenges, needs, and desired outcomes. What makes this job title unique is the “Swiss army knife” approach to data.
Additionally, Alation and Paxata announced the new data exploration capabilities of Paxata in the Alation Data Catalog, where users can find trusted data assets and, with a single click, work with their data in Paxata’s Self-Service Data Prep Application. 3) Data professionals come in all shapes and forms.
Semantics, context, and how data is tracked and used mean even more as you stretch to reach post-migration goals. This is why, when data moves, it’s imperative for organizations to prioritize data discovery. Data discovery is also critical for datagovernance , which, when ineffective, can actually hinder organizational growth.
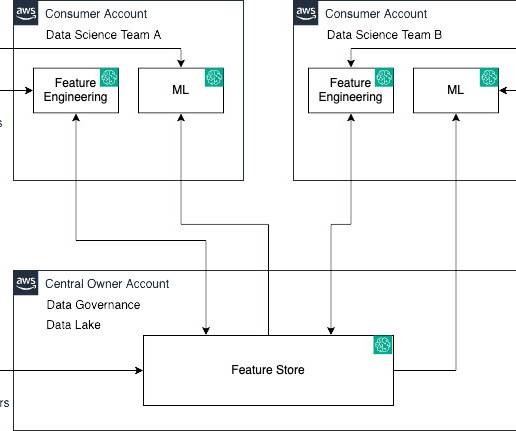
Let’s demystify this using the following personas and a real-world analogy: Data and ML engineers (owners and producers) – They lay the groundwork by feeding data into the feature store Data scientists (consumers) – They extract and utilize this data to craft their models Data engineers serve as architects sketching the initial blueprint.
The main goal of a data mesh structure is to drive: Domain-driven ownership Data as a product Self-service infrastructure Federated governance One of the primary challenges that organizations face is datagovernance.
This is the practice of creating, updating and consistently enforcing the processes, rules and standards that prevent errors, data loss, data corruption, mishandling of sensitive or regulated data, and data breaches. Datascience tasks such as machine learning also greatly benefit from good data integrity.
Top Use Cases of Snowpark With Snowpark, bringing business logic to data in the cloud couldn’t be easier. Transitioning work to Snowpark allows for faster ML deployment, easier scaling, and robust datapipeline development. ML Applications For data scientists, models can be developed in Python with common machine learning tools.
Automation Automation plays a pivotal role in streamlining ETL processes, reducing the need for manual intervention, and ensuring consistent data availability. By automating key tasks, organisations can enhance efficiency and accuracy, ultimately improving the quality of their datapipelines.
The combination of these capabilities allows organizations to quickly implement advanced analytics without the need for extensive datascience expertise. With the ability to write custom functions and procedures, developers can create sophisticated datapipelines and analytical workflows, all within the same unified environment.
We already know that a data quality framework is basically a set of processes for validating, cleaning, transforming, and monitoring data. DataGovernanceDatagovernance is the foundation of any data quality framework. It primarily caters to large organizations with complex data environments.
The right data architecture can help your organization improve data quality because it provides the framework that determines how data is collected, transported, stored, secured, used and shared for business intelligence and datascience use cases. What does a modern data architecture do for your business?
Powered by cloud computing, more data professionals have access to the data, too. Data analysts have access to the data warehouse using BI tools like Tableau; data scientists have access to datascience tools, such as Dataiku. Better Data Culture. Who Can Adopt the Modern Data Stack?
Image generated with Midjourney In today’s fast-paced world of datascience, building impactful machine learning models relies on much more than selecting the best algorithm for the job. Data scientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust datapipelines.
While the concept of data mesh as a data architecture model has been around for a while, it was hard to define how to implement it easily and at scale. Two data catalogs went open-source this year, changing how companies manage their datapipeline. The departments closest to data should own it.
Support for Advanced Analytics : Transformed data is ready for use in Advanced Analytics, Machine Learning, and Business Intelligence applications, driving better decision-making. Compliance and Governance : Many tools have built-in features that ensure data adheres to regulatory requirements, maintaining datagovernance across organisations.
Apache Nifi Apache Nifi is an open-source ETL tool that automates data flow between systems. It is well known for its data provenance and seamless data routing capabilities. Nifi provides a graphical interface for designing datapipelines , allowing users to track data flows in real-time.
Universities were only just beginning to plan formal academic datascience programs, and the skills to be taught in those programs were still being identified. This year, there are more than 900 academic programs offering training in datascience. A lack of data literacy slows down the process.
Three experts from Capital One ’s datascience team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of DataScience, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
Three experts from Capital One ’s datascience team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of DataScience, Erin Babinski; and Head of Data and Machine Learning, Kishore Mosaliganti.
Focusing only on what truly matters reduces data clutter, enhances decision-making, and improves the speed at which actionable insights are generated. Streamlined DataPipelines Efficient datapipelines form the backbone of lean data management.
Strategies to Improve Data Quality High-quality data is a strategic asset that fuels innovation, drives informed decision-making, and enhances operational efficiency. DataGovernance and Management Effective datagovernance is the cornerstone of data quality.
Apache NiFi As an open-source data integration tool, Apache NiFi enables seamless data flow and transformation across systems. Its drag-and-drop interface simplifies the design of datapipelines, making it easier for users to implement complex transformation logic.
Learn more Version Control for Machine Learning and DataScience Dataset version management challenges Data storage and retrieval As a machine learning project advances in its lifecycle, its demand for data also increases. Data aggregation: Data sources could increase as more data points are required to train ML models.
In the data-driven world we live in today, the field of analytics has become increasingly important to remain competitive in business. In fact, a study by McKinsey Global Institute shows that data-driven organizations are 23 times more likely to outperform competitors in customer acquisition and nine times […].
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content