This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Final Stage Overall Prizes where models were rigorously evaluated with cross-validation and model reports were judged by a panel of experts. The cross-validations for all winners were reproduced by the DrivenData team. Lower is better. Unsurprisingly, the 0.10 quantile was easier to predict than the 0.90
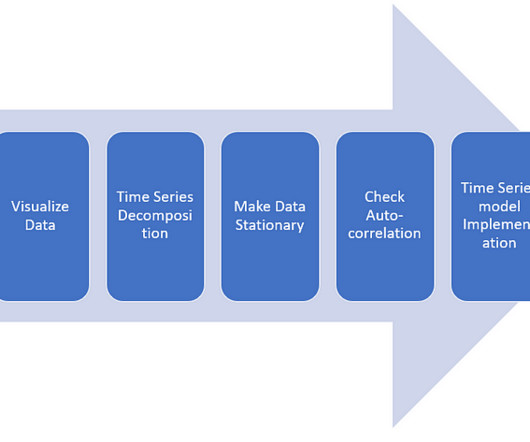
Last Updated on July 19, 2023 by Editorial Team Author(s): Yashashri Shiral Originally published on Towards AI. Sales Prediction| Using Time Series| End-to-End Understanding| Part -2 Sales Forecasting determines how the company invests and grows to create a massive impact on company valuation.
These packages are built to handle various aspects of machine learning, including tasks such as classification, regression, clustering, dimensionality reduction, and more. These packages cover a wide array of areas including classification, regression, clustering, dimensionality reduction, and more.
billion in 2023 to $181.15 Key techniques in unsupervised learning include: Clustering (K-means) K-means is a clustering algorithm that groups data points into clusters based on their similarities. Validation strategies, such as cross-validation, help assess a model’s generalisation ability and prevent overfitting.
from 2023 to 2030. Projecting data into two or three dimensions reveals hidden structures and clusters, particularly in large, unstructured datasets. Cross-validation ensures these evaluations generalise across different subsets of the data. The global market was valued at USD 36.73
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











Let's personalize your content