
Improve Cluster Balance with the CPD Scheduler?—?Part 1
IBM Data Science in Practice
AUGUST 23, 2023
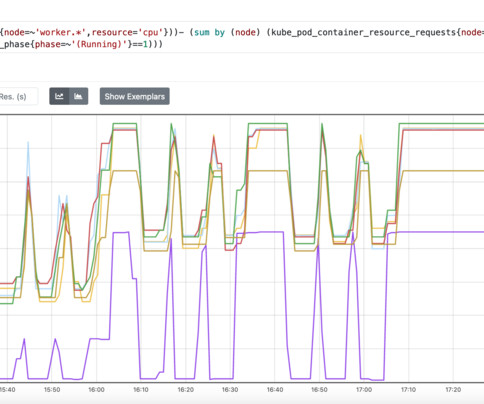
Improve Cluster Balance with the CPD Scheduler — Part 1 The default Kubernetes (“k8s”) scheduler can be thought of as a sort of “greedy” scheduler, in that it always tries to place pods on the nodes that have the most free resources. This frequently exacerbates cluster imbalance. This can lead to performance problems and even outages.







































Let's personalize your content