

Introduction to K-Fold Cross-Validation in R
Analytics Vidhya
MARCH 14, 2021
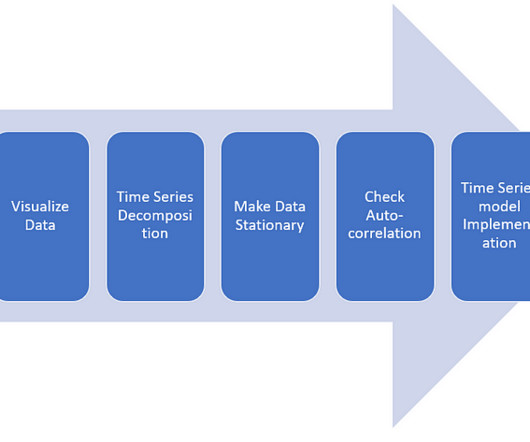
The post Introduction to K-Fold Cross-Validation in R appeared first on Analytics Vidhya. ArticleVideo Book This article was published as a part of the Data Science Blogathon. Photo by Myriam Jessier on Unsplash Prerequisites: Basic R programming.
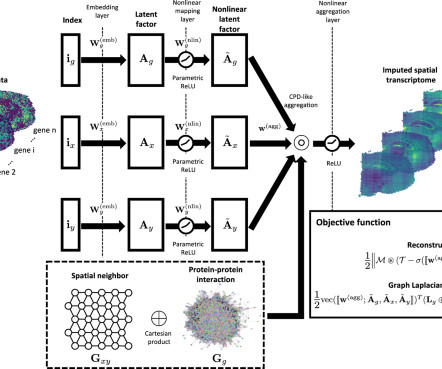



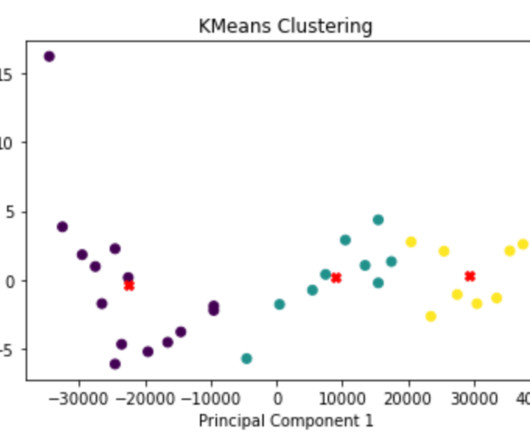














Let's personalize your content