5 Tricky SQL Queries Solved
KDnuggets
AUGUST 19, 2022
Explaining the approach to solving a few complex SQL queries.
KDnuggets
AUGUST 19, 2022
Explaining the approach to solving a few complex SQL queries.

Analytics Vidhya
AUGUST 18, 2022
This article was published as a part of the Data Science Blogathon. Introduction More often than not, developers run into issues of an application running on one machine versus not running on another. Dockers help prevent this by ensuring the application runs on any machine if it works on yours. Simply put, if your job as […]. The post Building a simple Flask App using Docker vs Code appeared first on Analytics Vidhya.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Smart Data Collective
AUGUST 14, 2022
Data loss is a serious problem for many businesses. An estimated 94% do not survive a catastrophic data loss. Data loss prevention (DLP) strives to protect your business data from inside or outside compromise. This includes data leakage, data loss , misuse of data, or data compromised by unauthorized parties. DLP software aims to identify and classify crucial business data and pinpoint potential organization or policy packs violations.
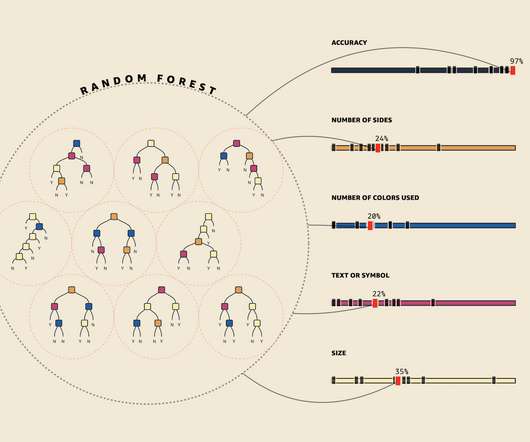
FlowingData
AUGUST 15, 2022
As part of a teaching initiative by Amazon, MLU-Explain is a series of interactive explainers on core machine learning concepts. Learn about training sets, decision trees, random forests, and more. Seems like a good way to spend a Friday night if you ask me. Tags: Amazon , machine learning.

Speaker: Tamara Fingerlin, Developer Advocate
Apache Airflow® 3.0, the most anticipated Airflow release yet, officially launched this April. As the de facto standard for data orchestration, Airflow is trusted by over 77,000 organizations to power everything from advanced analytics to production AI and MLOps. With the 3.0 release, the top-requested features from the community were delivered, including a revamped UI for easier navigation, stronger security, and greater flexibility to run tasks anywhere at any time.

KDnuggets
AUGUST 15, 2022
ETL during the process of producing effective machine learning algorithms is found at the base - the foundation. Let’s go through the steps on how ETL is important to machine learning.

Analytics Vidhya
AUGUST 18, 2022
Dear Readers, Data Science is a vast subject, and the learning you can get is immense. And we at Analytics Vidhya always try to bring new learning topics and build up your skills. This time, we have not one, not two, but six new DataHour for you to attend. So, keep your notepad handy and […]. The post The DataHour: Your Upcoming Learning Timeline appeared first on Analytics Vidhya.
Data Science Current brings together the best content for data science professionals from the widest variety of thought leaders.
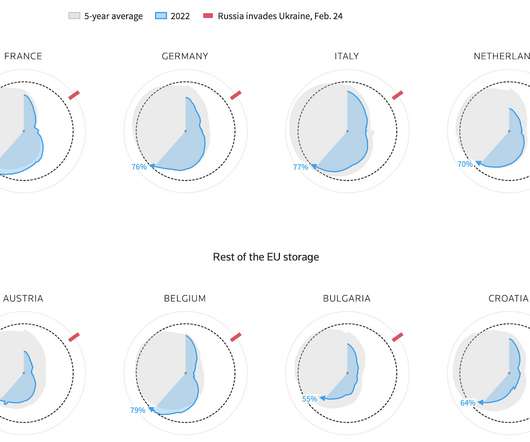
FlowingData
AUGUST 17, 2022
Reuters goes with the radar chart to show gas supplies , as European countries prepare for the winter and possibly no gas from Russia. The circular shape shows the annual cycle, the gray shows the previous five-year average, and the blue shows the current year’s supply. Tags: Europe , gas.

KDnuggets
AUGUST 18, 2022
If you’re considering a career in data science, it’s important to understand how these two fields differ, and which one might be more appropriate for someone with your skills and interests.

Analytics Vidhya
AUGUST 19, 2022
This article was published as a part of the Data Science Blogathon. Introduction AWS Glue helps Data Engineers to prepare data for other data consumers through the Extract, Transform & Load (ETL) Process. The managed service offers a simple and cost-effective method of categorizing and managing big data in an enterprise. It provides organizations with […].

Smart Data Collective
AUGUST 17, 2022
Cloud technology is becoming more important to modern businesses than ever. Ninety-four percent of enterprises invest in cloud infrastructures, due to the benefits it offers. An estimated 87% of companies using the cloud rely on hybrid cloud environments. However, some companies use other cloud solutions, which need to be discussed as well. These days, most companies’ cloud ecosystem includes infrastructure, compliance, security, and other aspects.

Speaker: Alex Salazar, CEO & Co-Founder @ Arcade | Nate Barbettini, Founding Engineer @ Arcade | Tony Karrer, Founder & CTO @ Aggregage
There’s a lot of noise surrounding the ability of AI agents to connect to your tools, systems and data. But building an AI application into a reliable, secure workflow agent isn’t as simple as plugging in an API. As an engineering leader, it can be challenging to make sense of this evolving landscape, but agent tooling provides such high value that it’s critical we figure out how to move forward.
Eugene Yan
AUGUST 13, 2022
Pushing back on the cult of complexity.
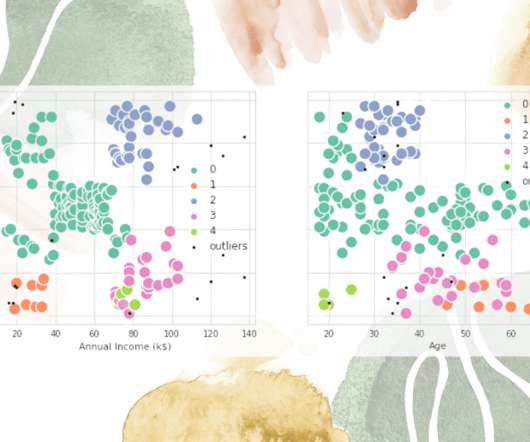
KDnuggets
AUGUST 17, 2022
Density-based clustering algorithm explained with scikit-learn code example.

Analytics Vidhya
AUGUST 17, 2022
This article was published as a part of the Data Science Blogathon. Introduction Transformers were one of the game-changer advancements in Natural language processing in the last decade. A team at Google Brain developed Transformers in 2017, and they are now replacing RNN models like long short-term memory(LSTM) as the model of choice for NLP […].

Smart Data Collective
AUGUST 15, 2022
Technology has become so advanced that, today, there’s an app for almost anything, from children’s education, to home improvement, to health monitoring, to workplace productivity. Gathering critical data to determine the best action to apply to specific situations has become integral in people’s daily lives. Because of technology, critical decisions are now mostly based on scientific data.

Speaker: Andrew Skoog, Founder of MachinistX & President of Hexis Representatives
Manufacturing is evolving, and the right technology can empower—not replace—your workforce. Smart automation and AI-driven software are revolutionizing decision-making, optimizing processes, and improving efficiency. But how do you implement these tools with confidence and ensure they complement human expertise rather than override it? Join industry expert Andrew Skoog as he explores how manufacturers can leverage automation to enhance operations, streamline workflows, and make smarter, data-dri
FlowingData
AUGUST 18, 2022
Welcome to issue #202 of The Process , the newsletter for FlowingData members that looks closer at how the charts get made. I’m Nathan Yau, and I’m visualizing data for one person and hoping for the best. Become a member for access to this — plus tutorials, courses, and guides.
KDnuggets
AUGUST 19, 2022
Looking to sort out the difference between Type I and Type II errors? Read on for more.

Analytics Vidhya
AUGUST 17, 2022
This article was published as a part of the Data Science Blogathon. Introduction In this article, we will introduce you to the big data ecosystem and the role of Apache Spark in Big data. We will also cover the Distributed database system, the backbone of big data. In today’s world, data is the fuel. Almost […]. The post Introduction to Apache Spark and its Datasets appeared first on Analytics Vidhya.

Smart Data Collective
AUGUST 15, 2022
Businesses are evolving and searching for newer ways to accomplish their goals, hence the need for artificial intelligence (AI). AI involves building smart machines to carry out tasks that typically need human intelligence, and AI simulates human intelligence using computer systems. The two major AI types used in businesses today are reactive machines and limited memory.

Speaker: Frank Taliano
Documents are the backbone of enterprise operations, but they are also a common source of inefficiency. From buried insights to manual handoffs, document-based workflows can quietly stall decision-making and drain resources. For large, complex organizations, legacy systems and siloed processes create friction that AI is uniquely positioned to resolve.

FlowingData
AUGUST 18, 2022
Dominic Royé mapped river discharge in Europe over the past few months: A single map for the worst #drought in 500 years in Europe. The river discharge anomaly based on reanalysis data from June to August 12 2022, shows an average negative anomaly of -29%, even reaching less than -62% at some points. #rstats #dataviz pic.twitter.com/LSGMfS52Lm. — Dr.

KDnuggets
AUGUST 16, 2022
This blog outlines a solution to the Kaggle Titanic challenge that employs Privacy-Preserving Machine Learning (PPML) using the Concrete-ML open-source toolkit.

Analytics Vidhya
AUGUST 17, 2022
This article was published as a part of the Data Science Blogathon. Introduction Contrast enhancement algorithms have evolved over the last few decades to meet the needs of its objectives. There are two main goals in enhancing an image’s contrast: (i) Improving its appearance for visual interpretation and (ii) facilitating/increasing the performance of subsequent tasks […].

The Data Administration Newsletter
AUGUST 16, 2022
I had a great experience attending the MIT Chief Data Officer and Information Quality Symposium in Cambridge this July. It was truly enlightening to hear from so many experienced data leaders. This year, there were 2,855 registered attendees from 63 countries, including 1,218 Chief Data Officers. I always learn so much at these symposia. In […].

Speaker: Chris Townsend, VP of Product Marketing, Wellspring
Over the past decade, companies have embraced innovation with enthusiasm—Chief Innovation Officers have been hired, and in-house incubators, accelerators, and co-creation labs have been launched. CEOs have spoken with passion about “making everyone an innovator” and the need “to disrupt our own business.” But after years of experimentation, senior leaders are asking: Is this still just an experiment, or are we in it for the long haul?
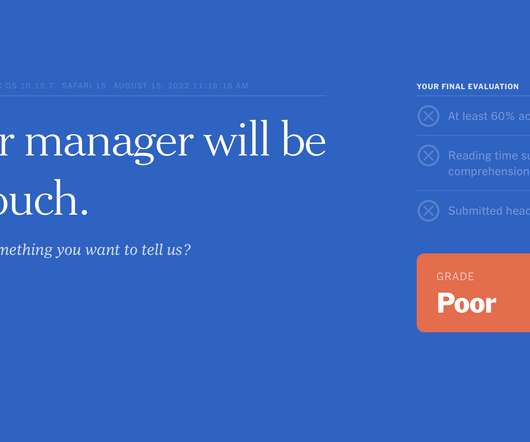
FlowingData
AUGUST 16, 2022
While reading this NYT article, by Jodi Kantor and Arya Sundaram, on the drawbacks of activity and time tracking for work, the article itself tracks your reading behavior. You see counters for the time you spend reading and scrolling, clicks, keystrokes, idle time, and active time. It comes complete with snippy comments and a final grade — and a bitter taste for productivity tracking.

KDnuggets
AUGUST 16, 2022
High data availability may help power digital transformation, but data management systems are needed to keep that data organizaed and make it accessible. Read this article to see why data management is important to data science.

Analytics Vidhya
AUGUST 17, 2022
This article was published as a part of the Data Science Blogathon. Introduction Impala is an open-source and native analytics database for Hadoop. Vendors such as Cloudera, Oracle, MapReduce, and Amazon have shipped Impala. If you want to learn all things Impala, you’ve come to the right place. source: -[link] It rapidly processes large […].

The Data Administration Newsletter
AUGUST 16, 2022
Unfortunately, a lot of data governance programs fail and there are many reasons why. The silver lining is that there are great lessons from these failures that we can learn from and make sure that we will avoid them in our data governance program. Here are the keys to data governance success: Treat Data Governance as […].

Speaker: Ben Epstein, Stealth Founder & CTO | Tony Karrer, Founder & CTO, Aggregage
When tasked with building a fundamentally new product line with deeper insights than previously achievable for a high-value client, Ben Epstein and his team faced a significant challenge: how to harness LLMs to produce consistent, high-accuracy outputs at scale. In this new session, Ben will share how he and his team engineered a system (based on proven software engineering approaches) that employs reproducible test variations (via temperature 0 and fixed seeds), and enables non-LLM evaluation m

FlowingData
AUGUST 19, 2022
If you’ve eaten at a restaurant lately, you might have noticed a substantially higher bill than you’re used to. You’d be right to assume that it’s because of things like inflation and pandemic-induced prices, but you might not realize how much the cost of ingredients, labor, and a new takeout business model has gone up for restaurants.

KDnuggets
AUGUST 15, 2022
The second part covers the list of Machine Learning, Deep Learning, Computer Vision, Natural Language Processing, Data Engineering, and MLOps.
Analytics Vidhya
AUGUST 16, 2022
This article was published as a part of the Data Science Blogathon. Introduction The Data science pipeline is the procedure and equipment used to compile raw data from many sources, evaluate it, and display the findings in a clear and concise manner. Businesses use the method to get answers to certain business queries and produce […]. The post Basic Introduction to Data Science Pipeline appeared first on Analytics Vidhya.

Dataversity
AUGUST 16, 2022
How organizations manage their data directly impacts their success or failure. The correlation between data analytics and intelligence to competitive advantage and growth has led to heavy investments in those technologies throughout the last decade. So, if you consider that content is the consumable form of data, then it follows that the era of big […].

Speaker: Tamara Fingerlin, Developer Advocate
In this new webinar, Tamara Fingerlin, Developer Advocate, will walk you through many Airflow best practices and advanced features that can help you make your pipelines more manageable, adaptive, and robust. She'll focus on how to write best-in-class Airflow DAGs using the latest Airflow features like dynamic task mapping and data-driven scheduling!

Expert insights. Personalized for you.






Let's personalize your content