This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
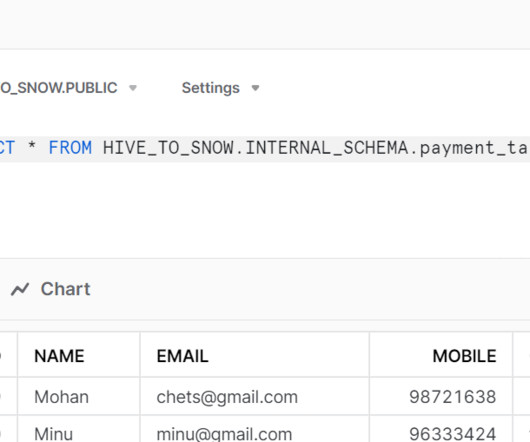
One common scenario that we’ve helped many clients with involves migrating data from Hive tables in a Hadoop environment to the Snowflake Data Cloud. Click Create cluster and choose software (Hadoop, Hive, Spark, Sqoop) and configuration (instance types, node count). Configure security (EC2 key pair). Find ElasticMapReduce-master.
Hadoop, SQL, Python, R, Excel are some of the tools you’ll need to be familiar using. In addition to having the skills, you’ll need to then learn how to use the modern data science tools. Each tool plays a different role in the data science process.
Released in 2022, DagsHub’s Direct Data Access (DDA for short) allows Data Scientists and Machine Learning engineers to stream files from DagsHub repository without needing to download them to their local environment ahead of time. This can prevent lengthy data downloads to the local disks before initiating their mode training.
When we download a Git repository, we also get the.dvc files which we use to download the data associated with them. More about Neptune: Working with artifacts: versioning datasets in runs How to version datasets or models stored in the S3 compatible storage Dolt Dolt is a SQL database that is created for versioning and sharing data.
Here’s the structured equivalent of this same data in tabular form: With structured data, you can use query languages like SQL to extract and interpret information. Popular data lake solutions include Amazon S3 , Azure Data Lake , and Hadoop. This text has a lot of information, but it is not structured.
It is specifically designed to work seamlessly with Hadoop and other big data processing frameworks. This file format is optimized for use with Hadoop and other big data processing frameworks and is highly compressed, offering excellent performance for batch processing and interactive querying.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content