

An Introduction to Data Analysis using Spark SQL
Analytics Vidhya
AUGUST 30, 2021
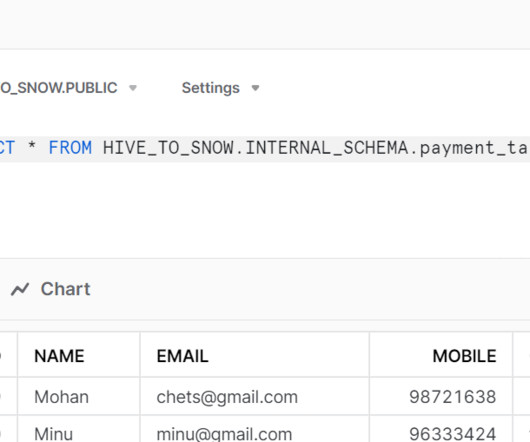
It is built on top of Hadoop and can process batch as well as streaming data. Hadoop is a framework for distributed computing that […]. The post An Introduction to Data Analysis using Spark SQL appeared first on Analytics Vidhya.













































Let's personalize your content