This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Traditional keyword-based search mechanisms are often insufficient for locating relevant documents efficiently, requiring extensive manual review to extract meaningful insights. This solution improves the findability and accessibility of archival records by automating metadata enrichment, document classification, and summarization.
For many of these use cases, businesses are building Retrieval Augmented Generation (RAG) style chat-based assistants, where a powerful LLM can reference company-specific documents to answer questions relevant to a particular business or use case. Generate a grounded response to the original question based on the retrieved documents.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machinelearning (ML) or generative AI. If you’re using a Retrieval Augmented Generation (RAG) system to provide context to your LLM, you can use your existing ML feature pipelines as context.
Challenges in deploying advanced ML models in healthcare Rad AI, being an AI-first company, integrates machinelearning (ML) models across various functions—from product development to customer success, from novel research to internal applications. Let’s transition to exploring solutions and architectural strategies.
The traditional approach of manually sifting through countless research documents, industry reports, and financial statements is not only time-consuming but can also lead to missed opportunities and incomplete analysis. This event-driven architecture provides immediate processing of new documents.
While AI has the potential to revolutionize everything from healthcare to transportation, the unpredictability and complexities associated with machinelearning models like GPT-5 cannot be overlooked. Understanding systemarchitecture A killswitch engineer at OpenAI would be responsible for more than just pulling a plug.
Here’s a simple rough sketch of RAG: Start with a collection of documents about a domain. Split each document into chunks. One more embellishment is to use a graph neural network (GNN) trained on the documents. Chunk your documents from unstructured data sources, as usual in GraphRAG. at Facebook—both from 2020.
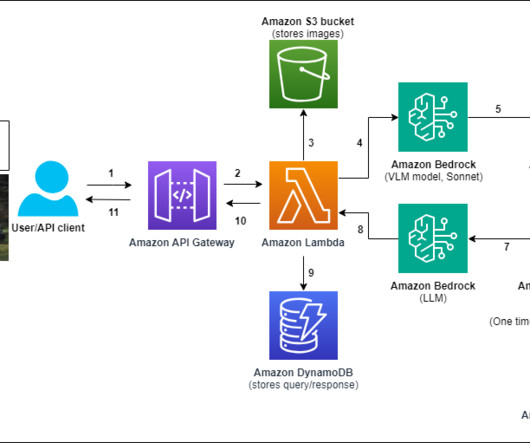
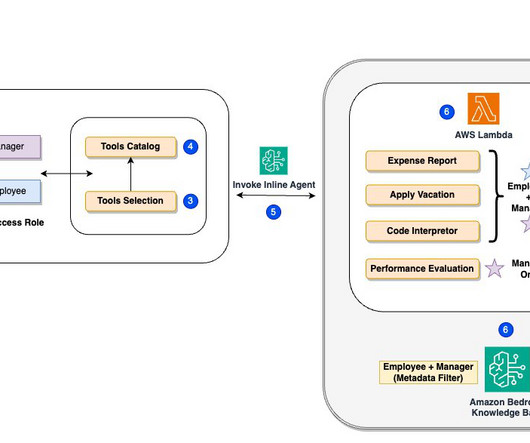
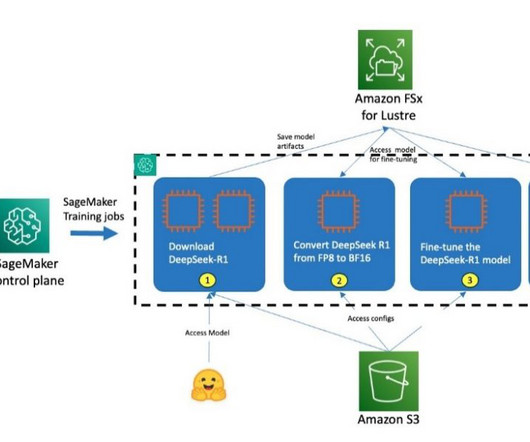
For this demo, weve implemented metadata filtering to retrieve only the appropriate level of documents based on the users access level, further enhancing efficiency and security. To understand how this dynamic role-based functionality works under the hood, lets examine the following systemarchitecture diagram.
To empower our enterprise customers to adopt foundation models and large language models, we completely redesigned the machinelearningsystems behind Snorkel Flow to make sure we were meeting customer needs. In this article, we share our journey and hope that it helps you design better machinelearningsystems.
To empower our enterprise customers to adopt foundation models and large language models, we completely redesigned the machinelearningsystems behind Snorkel Flow to make sure we were meeting customer needs. In this article, we share our journey and hope that it helps you design better machinelearningsystems.
I’ll start with a simple task: classify if an image is a real paper document, or it’s an image of a screen with some document on it. Real document Screen And this one is pretty straightforward. Not a document Here is the structure of our dataset: dataset/├── documents/│ ├── img_1.jpgU+007C.│ jpg│.│ └── img_100.jpg├──
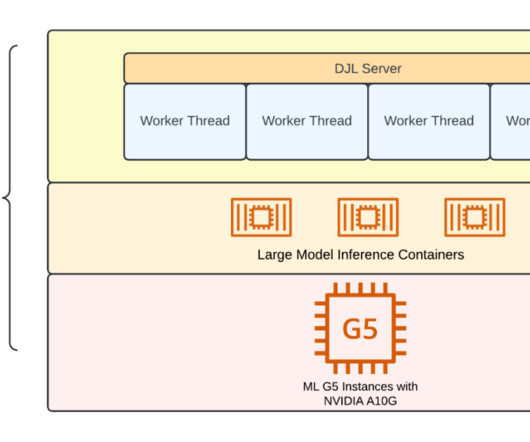
These steps are encapsulated in a prologue script and are documented step-by-step under the Fine-tuning section. To start using SageMaker HyperPod recipes, visit our sagemaker-hyperpod-recipes GitHub repository for comprehensive documentation and example implementations.
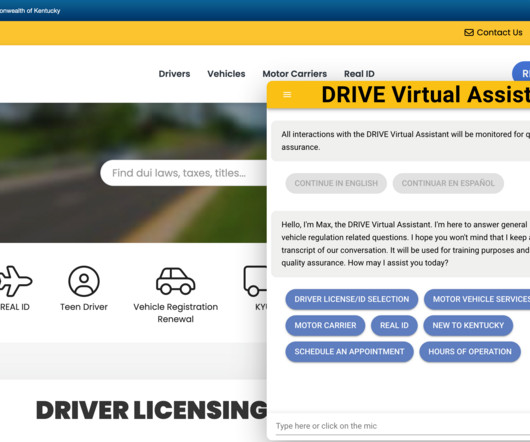
You configure curated answers to frequently asked questions using an integrated content management system that supports rich text and rich voice responses optimized for each channel. You can expand the solution’s knowledge base to include searching existing documents and webpage content using Amazon Kendra.
Flash to build a RAG system that understands both text and images enabling accurate answers from charts, tables, and visuals inside PDFs. 📉The Problem: Traditional RAGs Visual Blindspot Traditional Retrieval-Augmented Generation (RAG) systems rely on text embeddings to retrieve information from documents.
To empower our enterprise customers to adopt foundation models and large language models, we completely redesigned the machinelearningsystems behind Snorkel Flow to make sure we were meeting customer needs. In this article, we share our journey and hope that it helps you design better machinelearningsystems.
MachineLearning Operations (MLOps) vs Large Language Model Operations (LLMOps) LLMOps fall under MLOps (MachineLearning Operations). The following table provides a more detailed comparison: Task MLOps LLMOps Primary focus Developing and deploying machine-learning models. Specifically focused on LLMs.
For example, GDPR requires your organization to collect and keep track of metadata about the datasets and to document and report how the resulting model(s) from experiments work. Of course, this would be helpful for them to build robust and high-performing machinelearning models. Some will only track the post-training phase.
Despite the rapid growth of machinelearning research, corresponding code implementations are often unavailable, making it slow and labor-intensive for researchers to reproduce results and build upon prior work. Our results demonstrate the effectiveness of PaperCoder in creating high-quality, faithful implementations.
To use Automated Reasoning checks, you first create an Automated Reasoning policy by encoding a set of logical rules and variables from available source documentation. Automated Reasoning checks deliver deterministic verification of model outputs against documented rules, complete with audit trails and mathematical proof of policy adherence.
Ray promotes the same coding patterns for both a simple machinelearning (ML) experiment and a scalable, resilient production application. The following diagram illustrates the complete architecture you have built after completing these steps. To learn more about the aws-do-ray framework, refer to the GitHub repo.
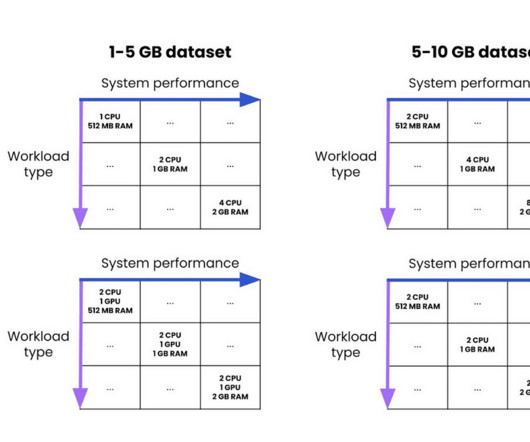
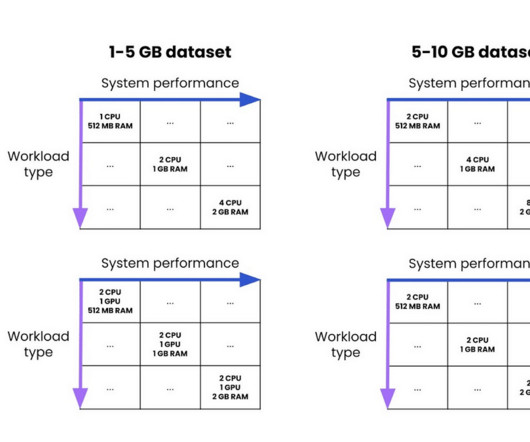
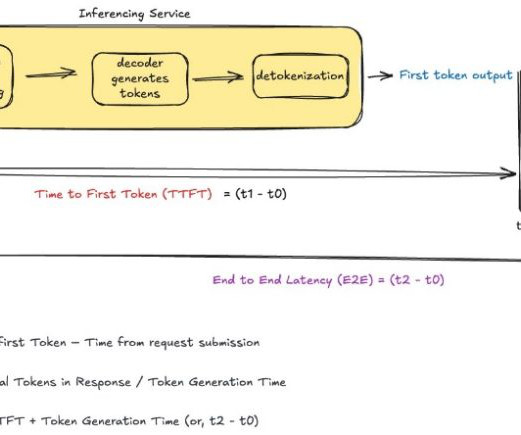
In this section, we explore how different system components and architectural decisions impact overall application responsiveness. Systemarchitecture and end-to-end latency considerations In production environments, overall system latency extends far beyond model inference time.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content