This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Naïve Bayes algorithms include decisiontrees , which can actually accommodate both regression and classification algorithms. Random forest algorithms —predict a value or category by combining the results from a number of decisiontrees.
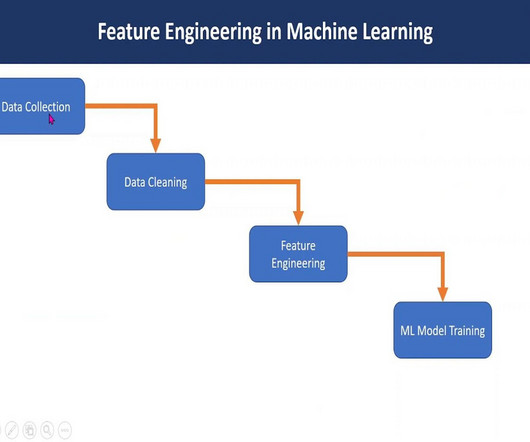
Feature engineering in machine learning is a pivotal process that transforms raw data into a format comprehensible to algorithms. Through ExploratoryDataAnalysis , imputation, and outlier handling, robust models are crafted. Text feature extraction Objective: Transforming textual data into numerical representations.
Jupyter notebooks allow you to create and share live code, equations, visualisations, and narrative text documents. Jupyter notebooks are widely used in AI for prototyping, data visualisation, and collaborative work. Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data.
These packages allow for text preprocessing, sentiment analysis, topic modeling, and document classification. It allows data scientists to combine code, documentation, and visualizations in a single document, making it easier to share and reproduce analyses.
Data Wrangling: The cleaning, transforming, and structuring of raw data into a format suitable for analysis. DecisionTrees: A supervised learning algorithm that creates a tree-like model of decisions and their possible consequences, used for both classification and regression tasks.
It is therefore important to carefully plan and execute data preparation tasks to ensure the best possible performance of the machine learning model. It is also essential to evaluate the quality of the dataset by conducting exploratorydataanalysis (EDA), which involves analyzing the dataset’s distribution, frequency, and diversity of text.
Additionally, specialized visualizations for specific domains, such as network graphs for social media analysis or geographical maps for spatial data, can be valuable. Good documentation ensures that users can easily understand the tool's functionalities and learn how to use them effectively.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












Let's personalize your content