
NoSQL Databases and Their Use Cases
KDnuggets
MARCH 16, 2023
Learn about NoSQL Databases and their types like key-value, document, graph and column family with their use cases.

KDnuggets
MARCH 16, 2023
Learn about NoSQL Databases and their types like key-value, document, graph and column family with their use cases.
IBM Data Science in Practice
MAY 19, 2025
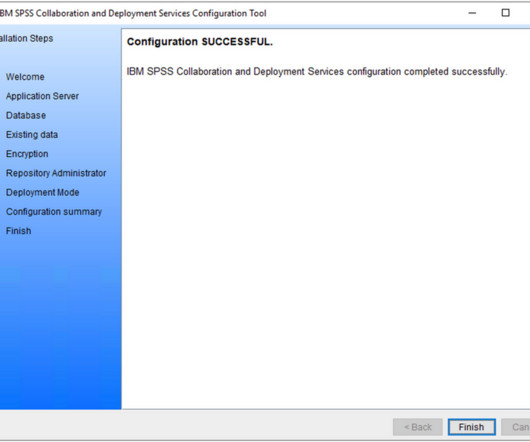
Enabling SSL for Database in IBM SPSS CaDS on Liberty ServerPost-Installation Guide If youve recently installed the SPSS Collaboration and Deployment Services (CaDS) on IBM Liberty and are wondering how to securely connect to your database via SSL, this blog is for you. Why Enable SSL for DB Connections? Microsoft SQL Server).
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Analytics Vidhya
SEPTEMBER 14, 2023
Introduction Large Language Models like langchain and deep lake have come a long way in Document Q&A and information retrieval. However, a […] The post Ask your Documents with Langchain and Deep Lake! These models know a lot about the world, but sometimes, they struggle to know when they don’t know something.
Analytics Vidhya
SEPTEMBER 5, 2024
Enter Multi-Document Agentic RAG – a powerful approach that combines Retrieval-Augmented Generation (RAG) with agent-based systems to create AI that can reason across multiple documents.
Analytics Vidhya
NOVEMBER 5, 2023
One such groundbreaking approach is Retrieval Augmented Generation (RAG), which combines the power of generative models like GPT (Generative Pretrained Transformer) with the efficiency of vector databases and langchain.

Analytics Vidhya
NOVEMBER 21, 2023
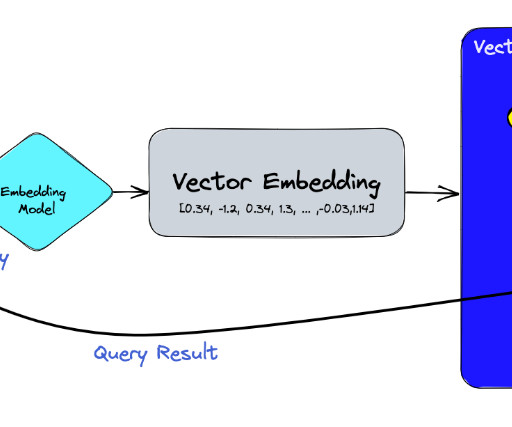
Introduction Vector Databases have become the go-to place for storing and indexing the representations of unstructured and structured data. In the ever-evolving landscape of […] The post A Deep Dive into Qdrant, the Rust-Based Vector Database appeared first on Analytics Vidhya.
AWS Machine Learning Blog
OCTOBER 29, 2024
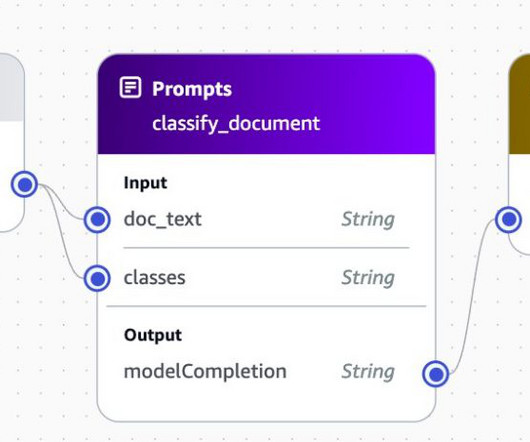
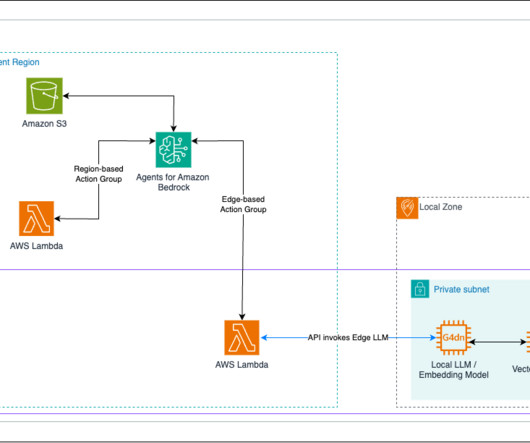
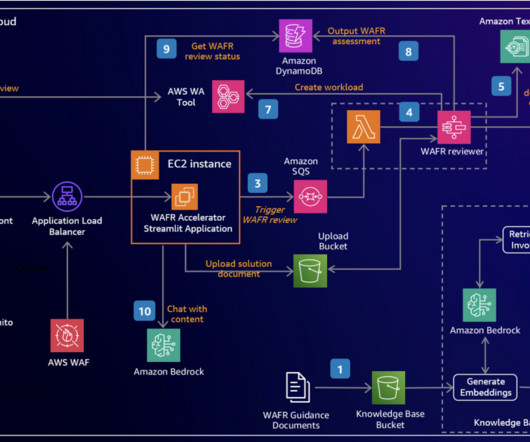
Enterprises in industries like manufacturing, finance, and healthcare are inundated with a constant flow of documents—from financial reports and contracts to patient records and supply chain documents. An AWS Lambda function reads the Amazon Textract response and calls an Amazon Bedrock prompt flow to classify the document.

Expert insights. Personalized for you.



































Let's personalize your content