

Top vector databases in market
Data Science Dojo
AUGUST 3, 2023
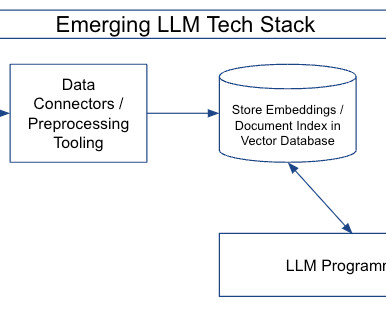
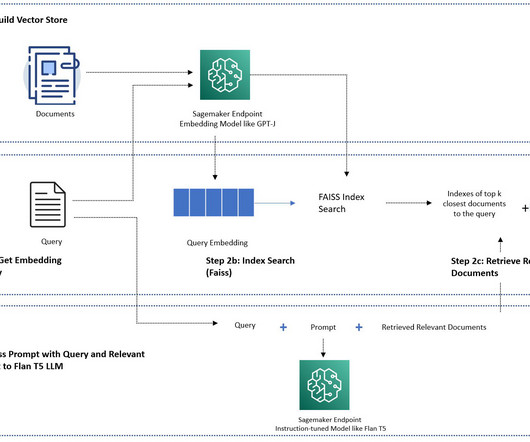
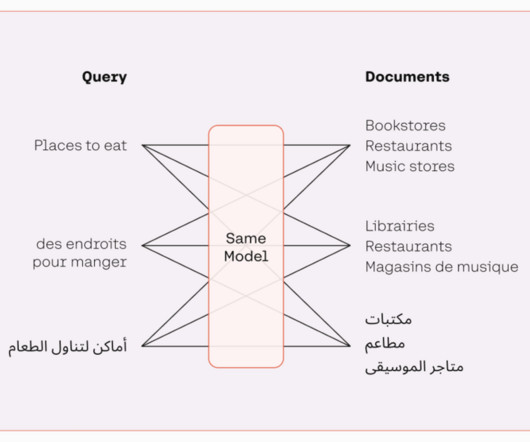
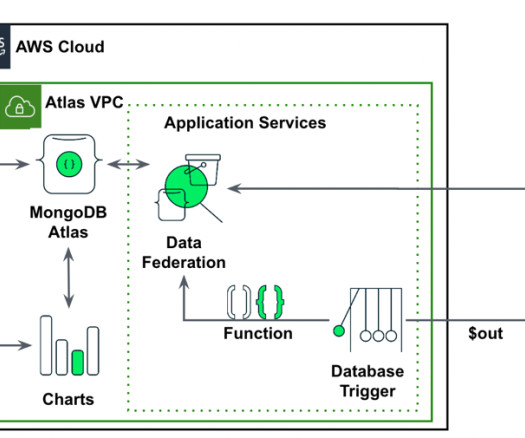
A vector database is a type of database that stores data as high-dimensional vectors. One way to think about a vector database is as a way of storing and organizing data that is similar to how the human brain stores and organizes memories. Pinecone is a vector database that is designed for machine learning applications.































Let's personalize your content