
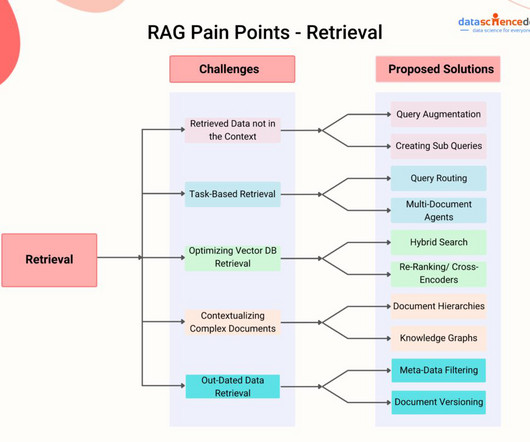
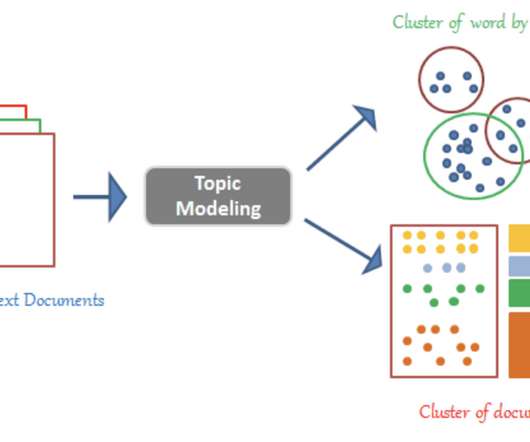
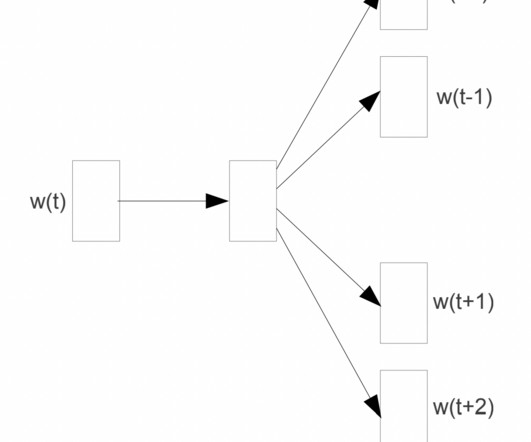
Convert Text Documents to a TF-IDF Matrix with tfidfvectorizer
KDnuggets
SEPTEMBER 7, 2022
Convert text documents to vectors using TF-IDF vectorizer for topic extraction, clustering, and classification.

KDnuggets
SEPTEMBER 7, 2022
Convert text documents to vectors using TF-IDF vectorizer for topic extraction, clustering, and classification.
IBM Data Science in Practice
AUGUST 23, 2023
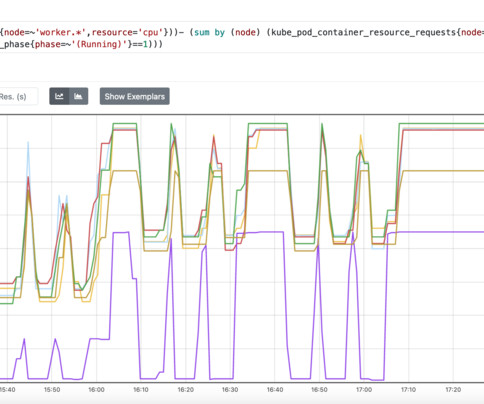
Improve Cluster Balance with the CPD Scheduler — Part 1 The default Kubernetes (“k8s”) scheduler can be thought of as a sort of “greedy” scheduler, in that it always tries to place pods on the nodes that have the most free resources. This frequently exacerbates cluster imbalance. This can lead to performance problems and even outages.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

AWS Machine Learning Blog
APRIL 22, 2024
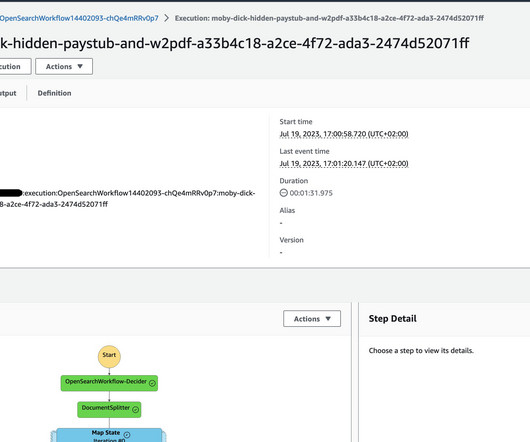
Amazon SageMaker HyperPod is purpose-built to accelerate foundation model (FM) training, removing the undifferentiated heavy lifting involved in managing and optimizing a large training compute cluster. In this solution, HyperPod cluster instances use the LDAPS protocol to connect to the AWS Managed Microsoft AD via an NLB.
AWS Machine Learning Blog
SEPTEMBER 8, 2023
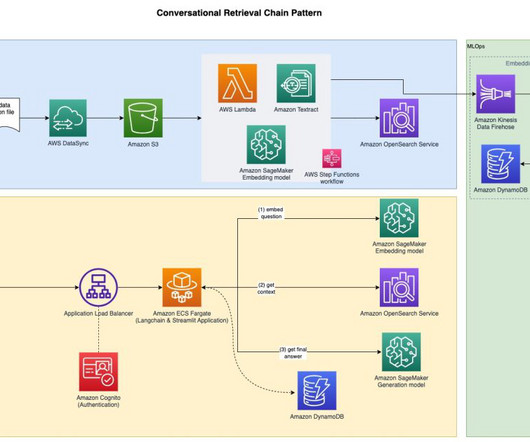
For modern companies that deal with enormous volumes of documents such as contracts, invoices, resumes, and reports, efficiently processing and retrieving pertinent data is critical to maintaining a competitive edge. What if there was a way to process documents intelligently and make them searchable in with high accuracy?

Mlearning.ai
JULY 17, 2023
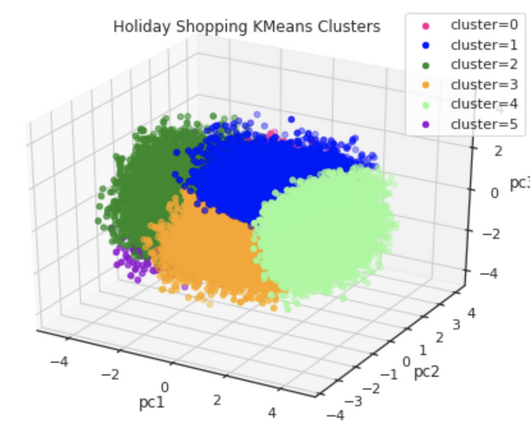
Clustering — Beyonds KMeans+PCA… Perhaps the most popular way of clustering is K-Means. It is also very common as well to combine K-Means with PCA for visualizing the clustering results, and many clustering applications follow that path (e.g. this link ).

IBM Journey to AI blog
SEPTEMBER 5, 2023
In the second blog of the series, we’re discussing best practices for upgrading your clusters to newer versions. You are responsible for applying these updates to the cluster master and worker nodes. Patch updates are automatically applied to cluster masters, but you are responsible for updating your cluster’s worker nodes.
ODSC - Open Data Science
FEBRUARY 23, 2023
Tesla’s Automated Driving Documents Have Been Requested by The U.S. Create Audience Segments Using K-Means Clustering, Churn Prevention with Reinforcement Learning… was originally published in ODSCJournal on Medium, where people are continuing the conversation by highlighting and responding to this story.

Expert insights. Personalized for you.



























Let's personalize your content