This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
14, 2025InFlux Technologies (Flux), a decentralized technology company specializing in cloud infrastructure, AI and decentralized cloud computing services, has launched FluxINTEL, an advanced document intelligence engine designed to help businesses analyze critical data with greater speed and insight. CAMBRIDGE, UK Feb.
Current text embedding models, like BERT, are limited to processing only 512 tokens at a time, which hinders their effectiveness with long documents. This limitation often results in loss of context and nuanced understanding.
Digital documents have long presented a dual challenge for both human readers and automated systems: preserving rich structural nuances while converting content into machine-processable formats. appeared first on Analytics Vidhya.
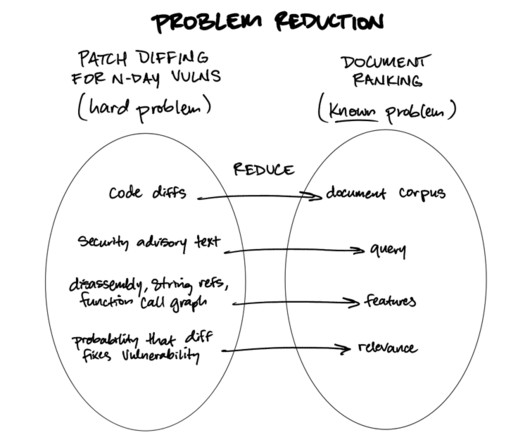
There are two claims I’d like to make: LLMs can be used effectively1 for listwise document ranking. Some complex problems can (surprisingly) be solved by transforming them into document ranking problems.
Documents are the backbone of enterprise operations, but they are also a common source of inefficiency. From buried insights to manual handoffs, document-based workflows can quietly stall decision-making and drain resources. 🛣️ Strategic Roadmapping: Build and execute a realistic AI implementation plan.
And that makes it a powerful tool for generating images of fraudulent documents, as users have found. Beyond faking expenses for lavish meals, OpenAI's increasingly canny ability to generate fake documents could open up the door for everything from phony tax forms and bank cheques to fake IDs and birth certificates.
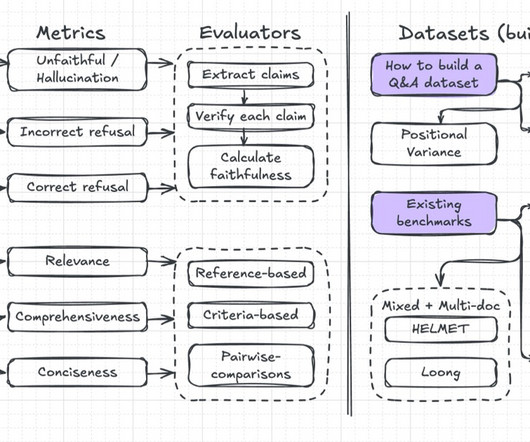
eugeneyan Start Here Writing Speaking Prototyping About Evaluating Long-Context Question & Answer Systems [ llm eval survey ] · 28 min read While evaluating Q&A systems is straightforward with short paragraphs, complexity increases as documents grow larger. Helpfulness: How relevant, comprehensive, and useful the response is for the user.
It will be used to extract the text from PDF files LangChain: A framework to build context-aware applications with language models (we’ll use it to process and chain document tasks). Tools Required(requirements.txt) The necessary libraries required are: PyPDF : A pure Python library to read and write PDF files.
You can use an AI chatbot to answer all your questions about the content of documents on your PC. This is completely free and local. Ideally, however, it requires a fast PC.
models include: A new vision language model (VLM) for document understanding tasks that IBM said demonstrates performance that matches or exceeds that of significantly larger models IBM (NYSE: IBM) today announced additions to its Granite portfolio of large language models intended to deliver small, efficient enterprise AI.
If youre Apple, this is the kind of internal document that you knew existed, but still hits hard. Especially in the middle of a global antitrust reckoning and internal whatever the heck is going on in there. A recently unsealed OpenAI file outlines the companys ambitions for ChatGPT. In short?
We introduce SmolDocling, an ultra-compact vision-language model targeting end-to-end document conversion. Our model comprehensively processes entire pages by generating DocTags, a new universal markup format that captures all page elements in their full context with location.
Instead of generating answers from parameters, the RAG can collect relevant information from the document. A retriever is used to collect relevant information from the document. Thanks to this retriever, instead of looking at the entire document, RAG will only search the relevant part. What is a retriever? Let’s consider this.
With building conversational agents over documents, for example, we measured quality average across several Q&A benchmarks. Figure 1 Figure 2 For document understanding, Agent Bricks builds higher quality and lower cost systems, compared to prompt optimized proprietary LLMs (Figure 2). Agent Bricks is now available in beta.
In the mortgage servicing industry, efficient document processing can mean the difference between business growth and missed opportunities. Onity processes millions of pages across hundreds of document types annually, including legal documents such as deeds of trust where critical information is often contained within dense text.
Figure 3: Document intelligence arrives at Databricks with the introduction of ai_parse in SQL. New functions like ai_parse_document make it effortless to extract structured information from complex documents, unlocking insights from previously hard-to-process enterprise content. To learn more, see our documentation.
the billions of documents, images, or videos on the Web). While this multi-vector approach boosts accuracy and enables retrieving more relevant documents, it introduces substantial computational challenges. Given a query from a user (e.g., “How This problem necessitates more complex and computationally intensive retrieval methods.
Imagine trying to navigate through hundreds of pages in a dense document filled with tables, charts, and paragraphs. Finding a specific figure or analyzing a trend would be challenging enough for a human; now imagine building a system to do it.
Stay ahead in 2025 with the latest OCR models optimized for speed, accuracy, and versatility in handling everything from scanned documents to complex layouts.
More on AI: New York Times Encourages Staff to Create Headlines Using AI The post Large Law Firm Sends Panicked Email as It Realizes Its Attorneys Have Been Using AI to Prepare Court Documents appeared first on Futurism.
Most enterprises sit on a massive amount of unstructured data—documents, images, audio, video—yet only a fraction ever turns into actionable insight. AI-powered apps such as
Federal Trade Commission (FTC) on Monday released new documentation detailing its new "Rule on Unfair or Deceptive Fees."The Federal Trade Commission released a FAQ document clarifying its rule hidden fees for live events, hotels, and short-term rentals. "The rule, set to take The U.S.
This blog post walks you through an exciting project that harnesses the power of Google’s Gemini AI to create an intelligent English Educator Application that analyzes text documents and provides […] The post Building an English Educator App API with Google Gemini and FastAPI appeared first on Analytics Vidhya.
Available within the Postman platform, Agent Mode understands developer intent and executes real tasks designing, testing, documenting, and monitoring APIs based on simple natural language […]
Have you ever been curious about what powers some of the best Search Applications such as Elasticsearch and Solr across use cases such e-commerce and several other document retrieval systems that are highly performant? Apache Lucene is a powerful search library in Java and performs super-fast searches on large volumes of data.
Midway through the document was the statement to Ella Stapleton noticed in February that the lecture notes for her organizational behavior class at Northeastern University appeared to have been generated by ChatGPT.
It is one thing to detect text on images on documents and another thing when the text is in an image on a person’s T-shirt. Scene text recognition (STR) continues challenging researchers due to the diversity of text appearances in natural environments.
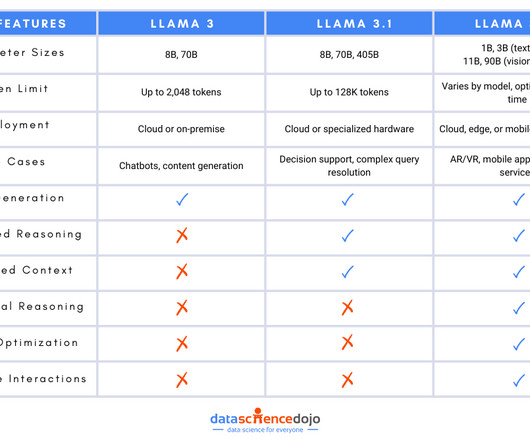
Document Summarization LLaMA 3.1 Also learn about AI-powered document search Language Translation Services Translation services can use Llama 3.1 to translate complex legal documents, ensuring that the translated text maintains its original meaning and legal accuracy. For instance, a healthcare provider can use a LLaMA 3.1-powered
For those of you wondering if AI agents can truly replace human workers, do yourself a favor and read the blog post that documents Anthropic’s “Project Vend.” Researchers at Anthropic and AI safety company Andon Labs put an instance of Claude Sonnet 3.7 in charge of an office vending machine, with a …
RAG combines the power of document retrieval with the […] The post Top 13 Advanced RAG Techniques for Your Next Project appeared first on Analytics Vidhya. And how do we keep it from confidently spitting out incorrect facts? These are the kinds of challenges that modern AI systems face, especially those built using RAG.
Handling long text sequences efficiently is crucial for document summarization, retrieval-augmented question answering, and multi-turn dialogues […] The post Optimizing LLM for Long Text Inputs and Chat Applications appeared first on Analytics Vidhya.
Victims choose one: Documented loss payment, up to $10,000. Cash fund payment, prorated with no documentation. Documented loss payment This option reimburses verifiable outofpocket expenses connected to the breach, capped at $10,000 per person. Select Documented Loss or Cash Fund. Choose your payment type.
Handling documents is no longer just about opening files in your AI projects, its about transforming chaos into clarity. Retrieving structured content from these documents has become a big task today. Docs such as PDFs, PowerPoints, and Word flood our workflows in every shape and size.
The solution ensures that AI models are developed using secure, compliant, and well-documented data. Alation Inc., the data intelligence company, launched its AI Governance solution to help organizations realize value from their data and AI initiatives.
For years, businesses, governments, and researchers have struggled with a persistent problem: How to extract usable data from Portable Document Format (PDF) files.
Step 4: Leverage NotebookLM’s Tools Audio Overview This feature converts your document, slides, or PDFs into a dynamic, podcast-style conversation with two AI hosts that summarize and connect key points. Study Guides & Briefing Docs In the “Studio” panel, you can generate structured outputs such as study guides or briefing documents.
Imagine an AI that can write poetry, draft legal documents, or summarize complex research papersbut how do we truly measure its effectiveness? As Large Language Models (LLMs) blur the lines between human and machine-generated content, the quest for reliable evaluation metrics has become more critical than ever.
The document is realistic enough to bypass automated Know Your Customer (KYC) checks, the expert states. Experts are calling for stronger defenses, including broader use of NFC-based verification and electronic identity documents (eIDs), which offer more resilient, hardware-level authentication. ” Musielak wrote on X.
Service planners are moving to establish a new enlisted military occupational specialty focused on artificial intelligence and machine learning, designated 49B, according to internal service documents.
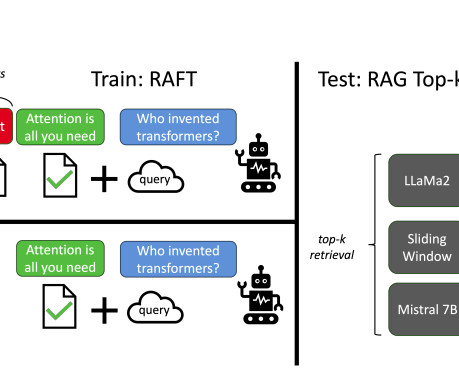
Retrieval-Augmented Generation, or RAG, has been hailed as a way to make large language models more reliable by grounding their answers in real documents. Even the safest models, paired with safe documents, became noticeably more dangerous when using RAG. Adding more retrieved documents only worsened the problem.
They can act as a signature for the printer that law enforcement uses as document forensic evidence (like in. The layout of the dots are different between printer brands and some dont leave any at all. Information like serial number and sometime the print time is encoded in these dots.
This new Audio Overview feature can turn documents, slides, charts and more into engaging two-party discussions with one click. Here is a an example of a wild new experimental feature from Google called NotebookLM. Two AI hosts start up a lively “deep dive” discussion based on your sources.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content