This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
In this article we are discussing that HDF5 is one of the most popular and reliable formats for non-tabular, numerical data. But this format is not optimized for deeplearning work. This article suggests what kind of ML native data format should be to truly serve the needs of modern datascientists.
This article was published as a part of the Data Science Blogathon. Image designed by the author – Shanthababu Introduction Every ML Engineer and DataScientist must understand the significance of “Hyperparameter Tuning (HPs-T)” while selecting your right machine/deeplearning model and improving the performance of the model(s).
If you want to stay ahead in the world of big data, AI, and data-driven decision-making, Big Data & AI World 2025 is the perfect event to explore the latest innovations, strategies, and real-world applications. This event offers cutting-edge discussions, hands-on workshops, and deep dives into AI advancements.
For datascientists, this shift has opened up a global market of remote data science jobs, with top employers now prioritizing skills that allow remote professionals to thrive. Here’s everything you need to know to land a remote data science job, from advanced role insights to tips on making yourself an unbeatable candidate.
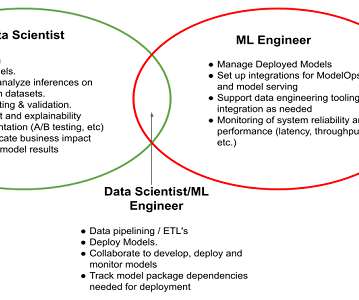
Machine learning engineer vs datascientist: two distinct roles with overlapping expertise, each essential in unlocking the power of data-driven insights. As businesses strive to stay competitive and make data-driven decisions, the roles of machine learning engineers and datascientists have gained prominence.
Drag and drop tools have revolutionized the way we approach machine learning (ML) workflows. Gone are the days of manually coding every step of the process – now, with drag-and-drop interfaces, streamlining your ML pipeline has become more accessible and efficient than ever before. H2O.ai H2O.ai
The new SDK is designed with a tiered user experience in mind, where the new lower-level SDK ( SageMaker Core ) provides access to full breadth of SageMaker features and configurations, allowing for greater flexibility and control for ML engineers. This is usually achieved by providing the right set of parameters when using an Estimator.
A recent survey of datascientists and engineers revealed that over half (53.3%) of today’s machine learning (ML) teams are planning on deploying a large language model (LLM) application of their own into production “within the next 12 months” or “as soon as possible”.
Artificial intelligence (AI), machine learning (ML), and data science have become some of the most significant topics of discussion in today’s technological era. Matul, who has experience working as an AI scientist at amazon, focused on dialogue machines and natural language understanding.
Deeplearning models are typically highly complex. While many traditional machine learning models make do with just a couple of hundreds of parameters, deeplearning models have millions or billions of parameters. This is where visualizations in ML come in.
Amazon SageMaker supports geospatial machine learning (ML) capabilities, allowing datascientists and ML engineers to build, train, and deploy ML models using geospatial data. Identify areas of interest We begin by illustrating how SageMaker can be applied to analyze geospatial data at a global scale.
Deeplearning models built using Maximo Visual Inspection (MVI) are used for a wide range of applications, including image classification and object detection. These models train on large datasets and learn complex patterns that are difficult for humans to recognize. What are the types of image processing ML models?
In an increasingly digital and rapidly changing world, BMW Group’s business and product development strategies rely heavily on data-driven decision-making. With that, the need for datascientists and machine learning (ML) engineers has grown significantly.
Generative AI is powered by advanced machine learning techniques, particularly deeplearning and neural networks, such as Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). Roles like AI Engineer, Machine Learning Engineer, and DataScientist are increasingly requiring expertise in Generative AI.
It is often too much to ask for the datascientist to become a domain expert. However, in all cases the datascientist must develop strong domain empathy to help define and solve the right problems. Nina Zumel and John Mount, Practical Data Science with R, 2nd Ed. But this statement also goes upstream.
ArticleVideo Book Introduction to Artificial Intelligence and Machine Learning Artificial Intelligence (AI) and its sub-field Machine Learning (ML) have taken the world by storm. The post A Comprehensive Step-by-Step Guide to Become an Industry Ready Data Science Professional appeared first on Analytics Vidhya.
Sharing in-house resources with other internal teams, the Ranking team machine learning (ML) scientists often encountered long wait times to access resources for model training and experimentation – challenging their ability to rapidly experiment and innovate. If it shows online improvement, it can be deployed to all the users.
It uses deeplearning to convert audio to text quickly and accurately. Amazon Transcribe offers deeplearning capabilities, which can handle a wide range of speech and acoustic characteristics, in addition to its scalability to process anywhere from a few hundred to over tens of thousands of calls daily, also played a pivotal role.
Women in Data Science (WiDS) – California, United States Women in Data Science (WiDS) is an annual conference held at Stanford University, California, United States and other locations worldwide. The conference is focused on the representation, education, and achievements of women in the field of data science.
In these scenarios, as you start to embrace generative AI, large language models (LLMs) and machine learning (ML) technologies as a core part of your business, you may be looking for options to take advantage of AWS AI and ML capabilities outside of AWS in a multicloud environment.
However, while RPA and ML share some similarities, they differ in functionality, purpose, and the level of human intervention required. In this article, we will explore the similarities and differences between RPA and ML and examine their potential use cases in various industries. What is machine learning (ML)?
Amazon SageMaker is a fully managed service that enables developers and datascientists to quickly and effortlessly build, train, and deploy machine learning (ML) models at any scale. SageMaker makes it straightforward to deploy models into production directly through API calls to the service.
About the Authors Shreyas Subramanian is a Principal DataScientist and helps customers by using generative AI and deeplearning to solve their business challenges using AWS services. Chris Pecora is a Generative AI DataScientist at Amazon Web Services.
Data Science Dojo Large Language Models Bootcamp The Data Science Dojo Large Language Models Bootcamp is a 5-day in-person bootcamp that teaches you everything you need to know about large language models (LLMs) and their real-world applications. Who should attend?
The machine learning systems developed by Machine Learning Engineers are crucial components used across various big data jobs in the data processing pipeline. Additionally, Machine Learning Engineers are proficient in implementing AI or ML algorithms. Is ML engineering a stressful job?
For budding datascientists and data analysts, there are mountains of information about why you should learn R over Python and the other way around. But why is SQL, or Structured Query Language , so important to learn? These are used to extract, transform, and load (ETL) data between different systems.
Amazon SageMaker is a fully managed machine learning (ML) service. With SageMaker, datascientists and developers can quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment. We add this data to Snowflake as a new table.
competition, winning solutions used deeplearning approaches from facial recognition tasks (particularly ArcFace and EfficientNet) to help the Bureau of Ocean and Energy Management and NOAA Fisheries monitor endangered populations of beluga whales by matching overhead photos with known individuals.
It was an exciting cloud data science week. Microsoft DP-100 Certification Updated – The Microsoft DataScientist certification exam has been updated to cover the latest Azure Machine Learning tools. Choosing the Right ML Tools – This video walks thru the Google Machine Learning Decision Pyramid.
Project Jupyter is a multi-stakeholder, open-source project that builds applications, open standards, and tools for data science, machine learning (ML), and computational science. Given the importance of Jupyter to datascientists and ML developers, AWS is an active sponsor and contributor to Project Jupyter.
Introduction to Artificial Intelligence and Machine Learning Artificial Intelligence (AI) and its sub-field Machine Learning (ML) have taken the world by storm. The post A Comprehensive Step-by-Step Guide to Become an Industry-Ready Data Science Professional appeared first on Analytics Vidhya.
Machine learning (ML) projects are inherently complex, involving multiple intricate steps—from data collection and preprocessing to model building, deployment, and maintenance. To start our ML project predicting the probability of readmission for diabetes patients, you need to download the Diabetes 130-US hospitals dataset.
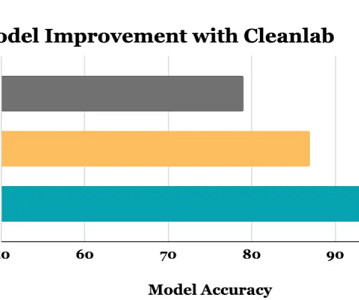
Be sure to check out his session, “ Improving ML Datasets with Cleanlab, a Standard Framework for Data-Centric AI ,” there! Anybody who has worked on a real-world ML project knows how messy data can be. Our goal is to enable all developers to find and fix data issues as effectively as today’s best datascientists.
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML. The next step is to build ML models using features selected from one or multiple feature groups.
While artificial intelligence (AI), machine learning (ML), deeplearning and neural networks are related technologies, the terms are often used interchangeably, which frequently leads to confusion about their differences. Machine learning is a subset of AI. It can ingest unstructured data in its raw form (e.g.,
They investigate the most suitable algorithms, identify the best weights and hyperparameters, and might even collaborate with fellow datascientists in the community to develop an effective strategy. This is where ML CoPilot enters the scene. Vector databases can store them and are designed for search and data mining.
These applications are all enabled by a strong ecosystem of open-source Python packages for working with image data. Packages like rasterio and pydicom make it possible for datascientists to contribute without becoming experts in satellites or medical imagery. Overall, we recommend openSMILE for general ML applications.
ML models have grown significantly in recent years, and businesses increasingly rely on them to automate and optimize their operations. However, managing ML models can be challenging, especially as models become more complex and require more resources to train and deploy. What is MLOps?
Mixed Precision Training with FP8 As shown in figure below, FP8 is a datatype supported by NVIDIA’s H100 and H200 GPUs, enables efficient deeplearning workloads. More details about FP8 can be found at FP8 Formats For DeepLearning. Surya Kari is a Senior Generative AI DataScientist at AWS.
Source: Author Introduction Deeplearning, a branch of machine learning inspired by biological neural networks, has become a key technique in artificial intelligence (AI) applications. Deeplearning methods use multi-layer artificial neural networks to extract intricate patterns from large data sets.
As with many burgeoning fields and disciplines, we don’t yet have a shared canonical infrastructure stack or best practices for developing and deploying data-intensive applications. What does a modern technology stack for streamlined ML processes look like? Why: Data Makes It Different. All ML projects are software projects.
About the authors Ishan Singh is a Generative AI DataScientist at Amazon Web Services, where he helps customers build innovative and responsible generative AI solutions and products. With a strong background in AI/ML, Ishan specializes in building Generative AI solutions that drive business value. Nitin Eusebius is a Sr.
The DJL is a deeplearning framework built from the ground up to support users of Java and JVM languages like Scala, Kotlin, and Clojure. The DJL is a deeplearning framework built from the ground up to support users of Java and JVM languages like Scala, Kotlin, and Clojure. We recently developed four more new models.
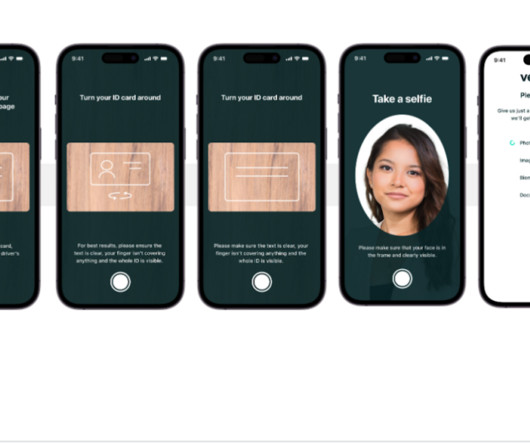
As an AI-powered solution, Veriff needs to create and run dozens of machine learning (ML) models in a cost-effective way. These models range from lightweight tree-based models to deeplearning computer vision models, which need to run on GPUs to achieve low latency and improve the user experience.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content