This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
However, the success of ML projects is heavily dependent on the quality of data used to train models. Poor dataquality can lead to inaccurate predictions and poor model performance. Understanding the importance of data […] The post What is DataQuality in Machine Learning?
In the data-driven world […] The post Monitoring DataQuality for Your Big Data Pipelines Made Easy appeared first on Analytics Vidhya. Determine success by the precision of your charts, the equipment’s dependability, and your crew’s expertise. A single mistake, glitch, or slip-up could endanger the trip.
Poor data results in poor judgments. Running unit tests in data science and data engineering projects assures dataquality. The post Unit Test framework and Test Driven Development (TDD) in Python appeared first on Analytics Vidhya. You know your code does what you want it to do.
Decomposing time series components like a trend, seasonality & cyclical component and getting rid of their impacts become explicitly important to ensure adequate dataquality of the time-series data we are working on and feeding into the model […] The post Various Techniques to Detect and Isolate Time Series Components Using Python appeared (..)
Implementing DBSCAN in Python • How to Avoid Overfitting • Simplify Data Processing with Pandas Pipeline • How to Use Data Visualization to Add Impact to Your Work Reports and Presentations • The DataQuality Hierarchy of Needs.
Introduction In the realm of machine learning, the veracity of data holds utmost significance in the triumph of models. Inadequate dataquality can give rise to erroneous predictions, unreliable insights, and overall performance.
and FiftyOne’s versatile computer vision query language, VoxelGPT empowers computer vision engineers, researchers, and organizations to curate high-quality datasets, develop high-performing models, and expedite the transition of AI projects from proof-of-concept to production. Leveraging the power of GPT-3.5
Specialized in Python coding, it has a significantly smaller size compared to competing models. In the study, the team also investigates the impact of high-qualitydata on enhancing the performance of SOTA LLMS while reducing dataset size and training computation. The paper also dives into the enhancement of dataquality.
Data preparation for LLM fine-tuning Proper data preparation is key to achieving high-quality results when fine-tuning LLMs for specific purposes. Importance of qualitydata in fine-tuning Dataquality is paramount in the fine-tuning process.
As such, the quality of their data can make or break the success of the company. This article will guide you through the concept of a dataquality framework, its essential components, and how to implement it effectively within your organization. What is a dataquality framework?
How to Use CatBoost in Python Let’s look at how to get started with CatBoost in Python. pip install catboost Dataset Overview The heatmap visualizes missing data across various columns in the dataset. This structure speeds up calculations and makes the model more interpretable. First, install the library using: !pip
These tools provide data engineers with the necessary capabilities to efficiently extract, transform, and load (ETL) data, build data pipelines, and prepare data for analysis and consumption by other applications. Essential data engineering tools for 2023 Top 10 data engineering tools to watch out for in 2023 1.
In quality control, an outlier could indicate a defect in a manufacturing process. By understanding and identifying outliers, we can improve dataquality, make better decisions, and gain deeper insights into the underlying patterns of the data. Note: We need to use statistical tables ( Table 1 ) or software (e.g.,
TensorFlow There are three main types of TensorFlow frameworks for testing: TensorFlow Extended (TFX): This is designed for production pipeline testing, offering tools for data validation, model analysis, and deployment. TensorFlow Data Validation: Useful for testing dataquality in ML pipelines.
Summary: Data preprocessing in Python is essential for transforming raw data into a clean, structured format suitable for analysis. It involves steps like handling missing values, normalizing data, and managing categorical features, ultimately enhancing model performance and ensuring dataquality.
Summary: This guide explores Artificial Intelligence Using Python, from essential libraries like NumPy and Pandas to advanced techniques in machine learning and deep learning. Python’s simplicity, versatility, and extensive library support make it the go-to language for AI development.
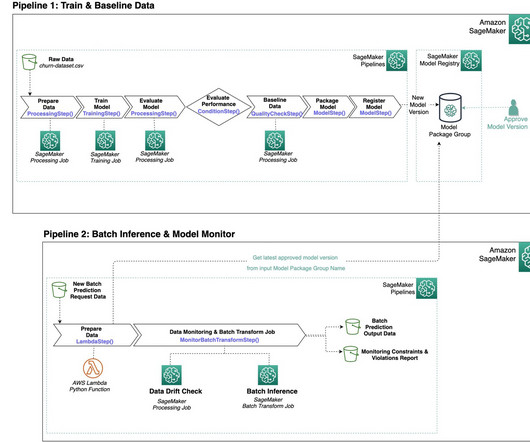
GitLab CI/CD serves as the macro-orchestrator, orchestrating model build and model deploy pipelines, which include sourcing, building, and provisioning Amazon SageMaker Pipelines and supporting resources using the SageMaker Python SDK and Terraform.
For example, if your team is proficient in Python and R, you may want an MLOps tool that supports open data formats like Parquet, JSON, CSV, etc., Your data team can manage large-scale, structured, and unstructured data with high performance and durability. Data monitoring tools help monitor the quality of the data.
introduced the SWE-bench dataset, which comprises 2,294 real-world GitHub issues and their corresponding pull requests, collected from 12 widely used Python repositories. However, a systematic evaluation of the quality of SWE-bench remains missing. To facilitate a rigorous evaluation of LLMs in practical coding contexts, Carlos et al.
Looking for an effective and handy Python code repository in the form of Importing Data in Python Cheat Sheet? Your journey ends here where you will learn the essential handy tips quickly and efficiently with proper explanations which will make any type of data importing journey into the Python platform super easy.
Languages like Python, JavaScript, Ruby, and PHP can interface with Claude API. Tools such as Postman or Python’s ‘requests’ library can be beneficial for testing. Prompt formatting notes Direct questions like “Why is the sky blue? The estimated cost is around $11.02 per million tokens for the completion phase.
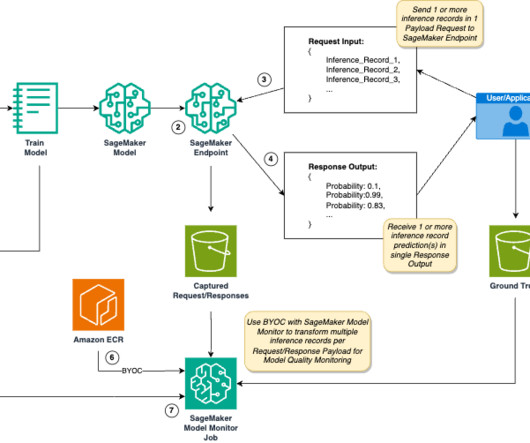
The DataQuality Check part of the pipeline creates baseline statistics for the monitoring task in the inference pipeline. Within this pipeline, SageMaker on-demand DataQuality Monitor steps are incorporated to detect any drift when compared to the input data.
The pretraining data predominantly comprises publicly available data, with some contributions from research papers and social media conversations. Significance of Falcon AI The performance of Large Language Models is intrinsically linked to the data they are trained on, making dataquality crucial.
These tools will help make your initial data exploration process easy. ydata-profiling GitHub | Website The primary goal of ydata-profiling is to provide a one-line Exploratory Data Analysis (EDA) experience in a consistent and fast solution. Output is a fully self-contained HTML application.
Some of the issues make perfect sense as they relate to dataquality, with common issues being bad/unclean data and data bias. What are the biggest challenges in machine learning? select all that apply) Related to the previous question, these are a few issues faced in machine learning.
Descriptive analytics is a fundamental method that summarizes past data using tools like Excel or SQL to generate reports. Techniques such as data cleansing, aggregation, and trend analysis play a critical role in ensuring dataquality and relevance. Data Scientists require a robust technical foundation.
A generalized, unbundled workflow A more accountable approach to GraphRAG is to unbundle the process of knowledge graph construction, paying special attention to dataquality. This shows how structured and unstructured data sources can be blended within a knowledge graph based on domain context.
MLOps facilitates automated testing mechanisms for ML models, which detects problems related to model accuracy, model drift, and dataquality. Data collection and preprocessing The first stage of the ML lifecycle involves the collection and preprocessing of data.
You can use this notebook job step to easily run notebooks as jobs with just a few lines of code using the Amazon SageMaker Python SDK. Data scientists currently use SageMaker Studio to interactively develop their Jupyter notebooks and then use SageMaker notebook jobs to run these notebooks as scheduled jobs.
Early and proactive detection of deviations in model quality enables you to take corrective actions, such as retraining models, auditing upstream systems, or fixing quality issues without having to monitor models manually or build additional tooling. docker/Dockerfile --repository sm-mm-mqm-byoc:1.0
Explore your Snowflake tables in SageMaker Data Wrangler, create a ML dataset, and perform feature engineering. Train and test the models using SageMaker Data Wrangler and SageMaker Autopilot. Use a Python notebook to invoke the launched real-time inference endpoint. Basic knowledge of Python, Jupyter notebooks, and ML.
However, there are also challenges that businesses must address to maximise the various benefits of data-driven and AI-driven approaches. Dataquality : Both approaches’ success depends on the data’s accuracy and completeness. What are the Three Biggest Challenges of These Approaches?
The repository also includes additional Python source code with helper functions, used in the setup notebook, to set up required permissions. See the following code: # Configure the DataQuality Baseline Job # Configure the transient compute environment check_job_config = CheckJobConfig( role=role_arn, instance_count=1, instance_type="ml.c5.xlarge",
Address common challenges in managing SAP master data by using AI tools to automate SAP processes and ensure dataquality. Create an AI-driven data and process improvement loop to continuously enhance your business operations. Think about material master data, for example. Data creation and management processes.
To facilitate this, an automated data engineering pipeline is built using AWS Step Functions. The Step Functions state machine is configured with an AWS Lambda function to retrieve data from the Splunk index using the Splunk Enterprise SDK for Python. For Analysis type , choose DataQuality and Insights Report.
Key Takeaways Big Data focuses on collecting, storing, and managing massive datasets. Data Science extracts insights and builds predictive models from processed data. Big Data technologies include Hadoop, Spark, and NoSQL databases. Data Science uses Python, R, and machine learning frameworks.
This setup uses the AWS SDK for Python (Boto3) to interact with AWS services. Rajesh Nedunuri is a Senior Data Engineer within the Amazon Worldwide Returns and ReCommerce Data Services team. He specializes in designing, building, and optimizing large-scale data solutions.
Proper data preparation leads to better model performance and more accurate predictions. SageMaker Canvas allows interactive data exploration, transformation, and preparation without writing any SQL or Python code. Choose Amazon S3 as the data source and connect it to the dataset. On the Create menu, choose Document.
Key components of data warehousing include: ETL Processes: ETL stands for Extract, Transform, Load. This process involves extracting data from multiple sources, transforming it into a consistent format, and loading it into the data warehouse. ETL is vital for ensuring dataquality and integrity.
These professionals encounter a range of issues when attempting to source the data they need, including: Data accessibility issues: The inability to locate and access specific data due to its location in siloed systems or the need for multiple permissions, resulting in bottlenecks and delays.
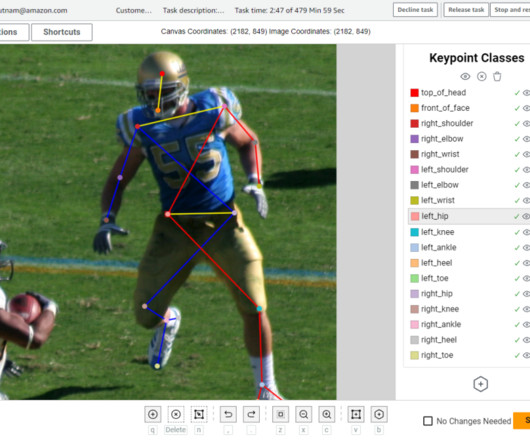
Labeling mistakes are important to identify and prevent because model performance for pose estimation models is heavily influenced by labeled dataquality and data volume. This custom workflow helps streamline the labeling process and minimize labeling errors, thereby reducing the cost of obtaining high-quality pose labels.
Python = Powerful AI Research Agent By Gao Dalie () This article details building a powerful AI research agent using Pydantic AI, a web scraper (Tavily), and Llama 3.3. Finally, it offers best practices for fine-tuning, emphasizing dataquality, parameter optimization, and leveraging transfer learning techniques.
This monitoring requires robust data management and processing infrastructure. Data Velocity: High-velocity data streams can quickly overwhelm monitoring systems, leading to latency and performance issues. To monitor your model in production, you need to instrument it to log relevant metrics and events.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content