This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
There are also plenty of data visualization libraries available that can handle exploration like Plotly, matplotlib, D3, Apache ECharts, Bokeh, etc. In this article, we’re going to cover 11 data exploration tools that are specifically designed for exploration and analysis. Output is a fully self-contained HTML application.
Summary: Data preprocessing in Python is essential for transforming raw data into a clean, structured format suitable for analysis. It involves steps like handling missing values, normalizing data, and managing categorical features, ultimately enhancing model performance and ensuring dataquality.
Moreover, ignoring the problem statement may lead to wastage of time on irrelevant data. Overlooking DataQuality The quality of the data you are working on also plays a significant role. Dataquality is critical for successful dataanalysis.
Overview of Typical Tasks and Responsibilities in Data Science As a Data Scientist, your daily tasks and responsibilities will encompass many activities. You will collect and clean data from multiple sources, ensuring it is suitable for analysis. Data Cleaning Data cleaning is crucial for data integrity.
The ultimate objective is to enhance the performance and accuracy of the sentiment analysis model. Noise refers to random errors or irrelevant data points that can adversely affect the modeling process. Integration also helps avoid duplication and redundancy of data, providing a comprehensive view of the information.
In the following sections, we demonstrate how to create, explore, and transform a sample dataset, use natural language to query the data, check for dataquality, create additional steps for the data flow, and build, test, and deploy an ML model. For Analysis type , choose DataQuality and Insights Report.
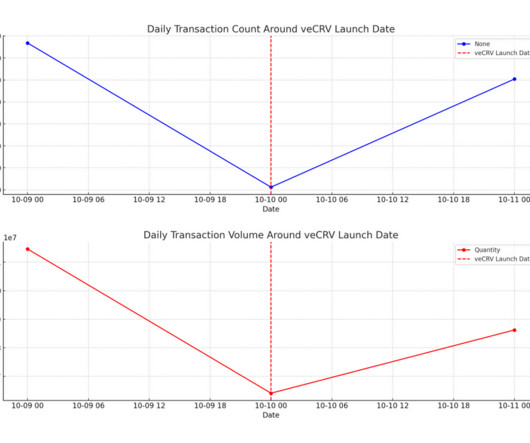
Abstract This research report encapsulates the findings from the Curve Finance Data Challenge , a competition that engaged 34 participants in a comprehensive analysis of the decentralized finance protocol. Part 1: ExploratoryDataAnalysis (EDA) MEV Over 25,000 MEV-related transactions have been executed through Curve.
Real-World Example: Healthcare systems manage a huge variety of data: structured patient demographics, semi-structured lab reports, and unstructured doctor’s notes, medical images (X-rays, MRIs), and even data from wearable health monitors. Ensuring dataquality and accuracy is a major challenge.
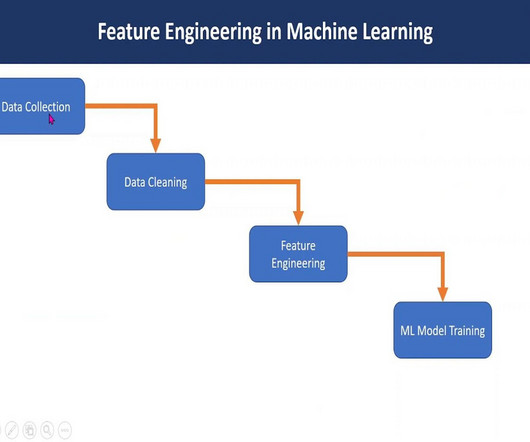
Feature engineering in machine learning is a pivotal process that transforms raw data into a format comprehensible to algorithms. Through ExploratoryDataAnalysis , imputation, and outlier handling, robust models are crafted. What is Feature Engineering? Steps of Feature Engineering 1.
ExploratoryDataAnalysis (EDA) ExploratoryDataAnalysis (EDA) is an approach to analyse datasets to uncover patterns, anomalies, or relationships. The primary purpose of EDA is to explore the data without any preconceived notions or hypotheses.
Their primary responsibilities include: Data Collection and Preparation Data Scientists start by gathering relevant data from various sources, including databases, APIs, and online platforms. They clean and preprocess the data to remove inconsistencies and ensure its quality.
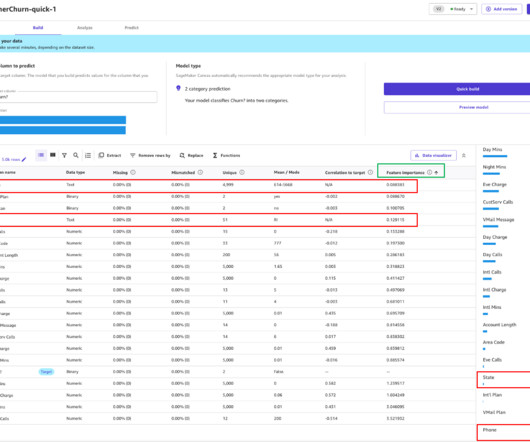
We use the model preview functionality to perform an initial EDA. This provides us a baseline that we can use to perform data augmentation, generating a new baseline, and finally getting the best model with a model-centric approach using the standard build functionality.
This section explores the essential steps in preparing data for AI applications, emphasising dataquality’s active role in achieving successful AI models. Importance of Data in AI Qualitydata is the lifeblood of AI models, directly influencing their performance and reliability.
This step includes: Identifying Data Sources: Determine where data will be sourced from (e.g., Ensuring Time Consistency: Ensure that the data is organized chronologically, as time order is crucial for time series analysis. Making Data Stationary: Many forecasting models assume stationarity.
It is a data integration process that involves extracting data from various sources, transforming it into a consistent format, and loading it into a target system. ETL ensures dataquality and enables analysis and reporting. Figure 3: Car Brand search ETL diagram 2.1.
Key Components of Data Science Data Science consists of several key components that work together to extract meaningful insights from data: Data Collection: This involves gathering relevant data from various sources, such as databases, APIs, and web scraping.
It is therefore important to carefully plan and execute data preparation tasks to ensure the best possible performance of the machine learning model. It is also essential to evaluate the quality of the dataset by conducting exploratorydataanalysis (EDA), which involves analyzing the dataset’s distribution, frequency, and diversity of text.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





















Let's personalize your content