

Serverless High Volume ETL data processing on Code Engine
IBM Data Science in Practice
JANUARY 13, 2025
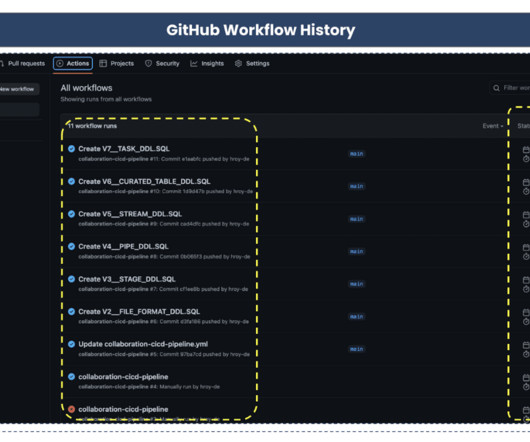
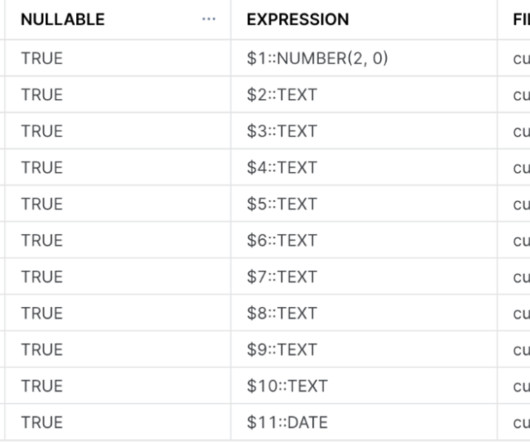
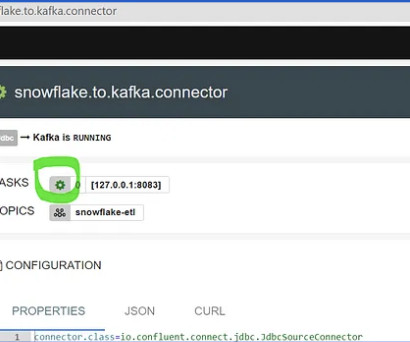
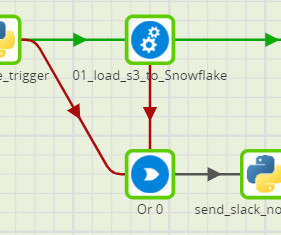
By Santhosh Kumar Neerumalla , Niels Korschinsky & Christian Hoeboer Introduction This blogpost describes how to manage and orchestrate high volume Extract-Transform-Load (ETL) loads using a serverless process based on Code Engine. The source data is unstructured JSON, while the target is a structured, relational database.



















Let's personalize your content