
Build an ML Inference Data Pipeline using SageMaker and Apache Airflow
Mlearning.ai
APRIL 6, 2023
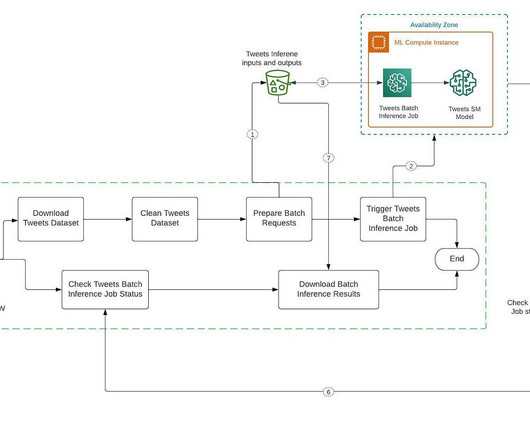
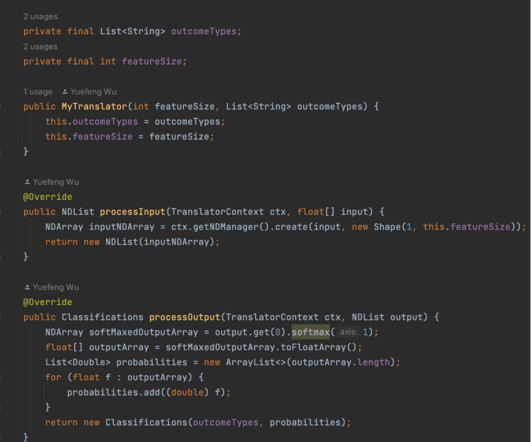
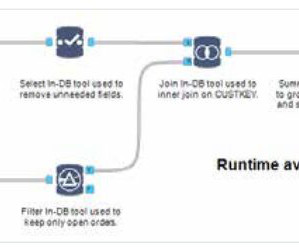
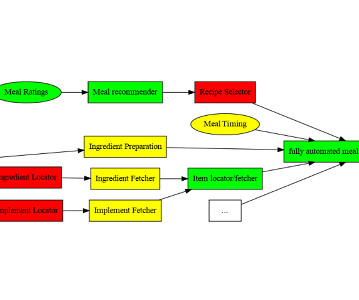
Automate and streamline our ML inference pipeline with SageMaker and Airflow Building an inference data pipeline on large datasets is a challenge many companies face. Download Batch Inference Results: Download batch inference results after completing the batch inference job and message received by SQS. ?Create






































Let's personalize your content