This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machinelearning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machinelearning (ML) or generative AI. And if you can’t wait to try it yourself, check out the Tecton interactive demo and observe a fraud detection use case in action. You can also find Tecton at AWS re:Invent.
We are excited to announce the launch of Amazon DocumentDB (with MongoDB compatibility) integration with Amazon SageMaker Canvas , allowing Amazon DocumentDB customers to build and use generative AI and machinelearning (ML) solutions without writing code. Analyze data using generative AI. Prepare data for machinelearning.
But again, stick around for a surprise demo at the end. ? From healthcare and education to finance and arts, the demos covered a wide spectrum of industries and use cases. It was a chance for participants to learn from each other and explore potential collaborations.
Savvy data scientists are already applying artificial intelligence and machinelearning to accelerate the scope and scale of data-driven decisions in strategic organizations. Set up a datapipeline that delivers predictions to HubSpot and automatically initiate offers within the business rules you set.
Capabilities of Groq AI With its state-of-the-art demonstrations, Groq AI has shown that it can churn out detailed, factual responses comprising hundreds of words in just a fraction of a second, complete with source citations, as seen in a recent demo shared on X. The first public demo using Groq: a lightning-fast AI Answers Engine.
Boost productivity – Empowers knowledge workers with the ability to automatically and reliably summarize reports and articles, quickly find answers, and extract valuable insights from unstructured data. The following demo shows Agent Creator in action. Dhawal Patel is a Principal MachineLearning Architect at AWS.
Best practices for building ETLs for ML Best practices for building ETLs for ML | Source: Author The significance of ETLs in machinelearning projects Exploring a pivotal facet of every machinelearning endeavor: ETLs. These insights are specifically curated for machinelearning applications.
Moving across the typical machinelearning lifecycle can be a nightmare. From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. How to understand your users (data scientists, ML engineers, etc.).
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. Pay-as-you-go pricing makes it easy to scale when needed.
Machinelearning, particularly its subsets, deep learning, and generative ML, is currently in the spotlight. We are all still trying to figure out how to test machinelearning models. What is MachineLearning Model Testing? Evaluation Vs. Testing: Are They Different?
Machinelearning, particularly its subsets, deep learning, and generative ML, is currently in the spotlight. We are all still trying to figure out how to test machinelearning models. What is MachineLearning Model Testing? Evaluation Vs. Testing: Are They Different?
As AI continues to advance at such an aggressive pace, solutions built on machinelearning are quickly becoming the new norm. Data scientists and data engineers want full control over every aspect of their machinelearning solutions and want coding interfaces so that they can use their favorite libraries and languages.
We frequently see this with LLM users, where a good LLM creates a compelling but frustratingly unreliable first demo, and engineering teams then go on to systematically raise quality. Machinelearning models are inherently limited because they are trained on static datasets, so their “knowledge” is fixed. Systems can be dynamic.
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. AWS Glue is a serverless data integration service that makes it easy to discover, prepare, and combine data for analytics, ML, and application development. yaml locally.
This day will have a strong focus on intermediate content, as well as several sessions appropriate for data practitioners at all levels. Tuesday is the first day of the AI Expo and Demo Hall , where you can connect with our conference partners and check out the latest developments and research from leading tech companies. What’s next?
Thirdly, there are improvements to demos and the extension for Spark. Follow our GitHub repo , demo repository , Slack channel , and Twitter for more documentation and examples of the DJL! He works to enable the development, training, and production inference of deep learning.
We’ll cover how to get the data via the Snowflake Marketplace, how to apply machinelearning with Snowpark , and then bring it all together to create an automated ML model to forecast energy prices. Python has long been the favorite programming language of data scientists.
Iris was designed to use machinelearning (ML) algorithms to predict the next steps in building a datapipeline. Conclusion To get started today with SnapGPT, request a free trial of SnapLogic or request a demo of the product. He currently is working on Generative AI for data integration.
An optional CloudFormation stack to deploy a datapipeline to enable a conversation analytics dashboard. This is where the content for the demo solution will be stored. For the demo solution, choose the default ( Claude V3 Sonnet ). For the hotel-bot demo, try the default of 4. Do not specify an S3 prefix.
For this architecture, we propose an implementation on GitHub , with loosely coupled components where the backend (5), datapipelines (1, 2, 3) and front end (4) can evolve separately. Choose the link with the following format to open the demo: [link]. Inside the frontend/streamlit-ui folder, run bash run-streamlit-ui.sh.
[link] Ahmad Khan, head of artificial intelligence and machinelearning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022.
[link] Ahmad Khan, head of artificial intelligence and machinelearning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022.
Many announcements at Strata centered on product integrations, with vendors closing the loop and turning tools into solutions, most notably: A Paxata-HDInsight solution demo, where Paxata showcased the general availability of its Adaptive Information Platform for Microsoft Azure. 3) Data professionals come in all shapes and forms.
The future of business depends on artificial intelligence and machinelearning. According to IDC , 83% of CEOs want their organizations to be more data-driven. Data scientists could be your key to unlocking the potential of the Information Revolution—but what do data scientists do? What Do Data Scientists Do?
Our partnership with Snorkel AI can help make scalable data science on Snowflake more accessible across an organization to help drive business outcomes. But – the value of rich textual data centralized within Snowflake can’t be realized by training machinelearning models until this raw data is curated and labeled.
Our partnership with Snorkel AI can help make scalable data science on Snowflake more accessible across an organization to help drive business outcomes. But – the value of rich textual data centralized within Snowflake can’t be realized by training machinelearning models until this raw data is curated and labeled.
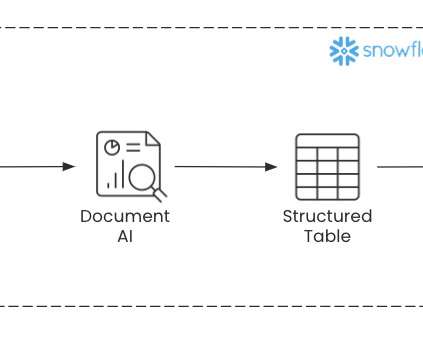
Datapipelines can be set up in Snowflake using stages , streams, and tasks to automate the continuous process of uploading documents, extracting information, and loading them into destination tables. Before we dive into the demo, the next section covers a couple of the key technologies that enable Document AI. Still curious?
Artificial intelligence (AI) can help improve the response rate on your coupon offers by letting you consider the unique characteristics and wide array of data collected online and offline of each customer and presenting them with the most attractive offers. All of this can be integrated with your marketing automation application of choice.
As data scientists or machine-learning engineers, one of the routine tasks we tackle involves rapid experimentation and training multiple models under different settings to identify the most effective ones. We need a well-optimized datapipeline to achieve this goal. The pipeline involves several steps.
Request a demo to see how watsonx can put AI to work There’s no AI, without IA AI is only as good as the data that informs it, and the need for the right data foundation has never been greater. Data lakehouses improve the efficiency of deploying AI and the generation of datapipelines.
The rise of data lakes, IOT analytics, and big datapipelines has introduced a new world of fast, big data. With TrustCheck, an information steward can guide and recommend the correct data assets for Tableau users to use all within the natural flow of their analysis. Conclusion. Subscribe to Alation's Blog.
So, what exactly is AI-ready data? Simply put, AI-ready data is structured, high-quality information that can be easily used to train machinelearning models and run AI applications with minimal engineering effort . Ready to explore the possibilities of agentic AI for your organization?
LLMOps (Large Language Model Operations), is a specialized domain within the broader field of machinelearning operations (MLOps). Continuous monitoring of resources, data, and metrics. DataPipeline - Manages and processes various data sources. ML Pipeline - Focuses on training, validation and deployment.
Modern AI, on the other hand, is built on machinelearning and artificial neural networks – algorithms that can learn their behavior from examples in data. As computational power increased and data became more abundant, AI evolved to encompass machinelearning and data analytics.
We frequently see this with LLM users, where a good LLM creates a compelling but frustratingly unreliable first demo, and engineering teams then go on to systematically raise quality. Machinelearning models are inherently limited because they are trained on static datasets, so their “knowledge” is fixed. Systems can be dynamic.
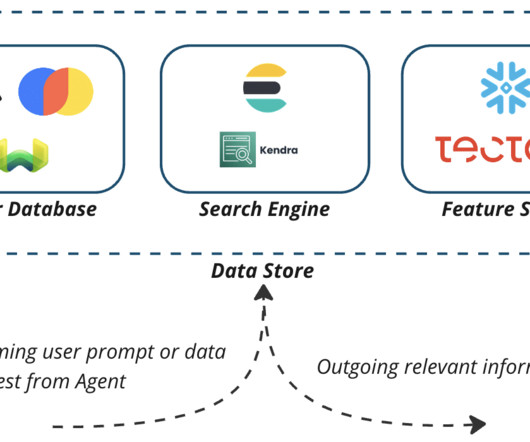
This approach incorporates relevant data from a data store into prompts, providing large language models with additional context to help answer queries. Our data engineering blog in this series explores the concept of data engineering and data stores for Gen AI applications in more detail.
GPT-4 DataPipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API. The data would be interesting to analyze. From Data Engineering to Prompt Engineering Prompt to do data analysis BI report generation/data analysis In BI/data analysis world, people usually need to query data (small/large).
They run scripts manually to preprocess their training data, rerun the deployment scripts, manually tune their models, and spend their working hours keeping previously developed models up to date. Building end-to-end machinelearningpipelines lets ML engineers build once, rerun, and reuse many times.
Most modern artificial intelligence systems are powered by machinelearning algorithms , which learn by example. Data scientists train the algorithms using datasets that contain curated learning examples. Request a demo. The post Humans and AI: Data Scientists Are Human Too appeared first on DataRobot.
From May 13th to 15th, ODSC East 2025 will bring together the brightest minds and most innovative companies in AI for three days of cutting-edge insights, hands-on demos, and one-on-one conversations. Get access to the AI Expo & Demo Hall and meet with dozens of innovative companies changing the AI landscape.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





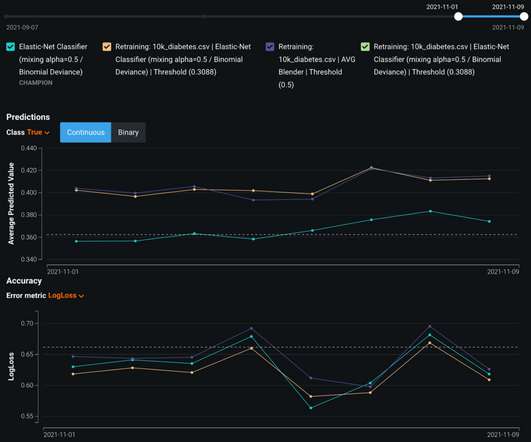










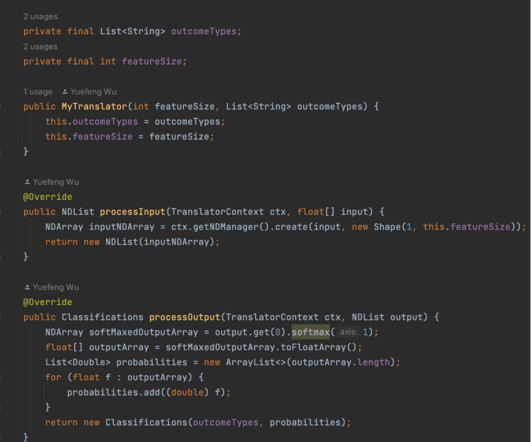
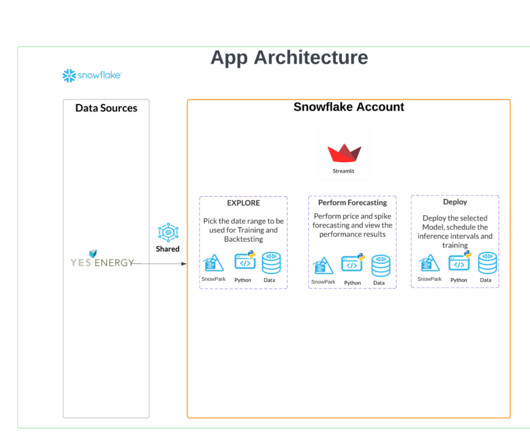

























Let's personalize your content