This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Machine learning engineer vs datascientist: two distinct roles with overlapping expertise, each essential in unlocking the power of data-driven insights. As businesses strive to stay competitive and make data-driven decisions, the roles of machine learning engineers and datascientists have gained prominence.
Savvy datascientists are already applying artificial intelligence and machine learning to accelerate the scope and scale of data-driven decisions in strategic organizations. Datascientists are in demand: the U.S. Explore these 10 popular blogs that help datascientists drive better data decisions.
Machine learning (ML) helps organizations to increase revenue, drive business growth, and reduce costs by optimizing core business functions such as supply and demand forecasting, customer churn prediction, credit risk scoring, pricing, predicting late shipments, and many others. Let’s learn about the services we will use to make this happen.
In an increasingly digital and rapidly changing world, BMW Group’s business and product development strategies rely heavily on data-driven decision-making. With that, the need for datascientists and machine learning (ML) engineers has grown significantly.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
AI credits from Confluent can be used to implement real-time datapipelines, monitor data flows, and run stream-based ML applications. Amazon Web Services(AWS) AWS offers one of the most extensive AI and ML infrastructures in the world. Modal Modal offers serverless compute tailored for data-intensive workloads.
From data processing to quick insights, robust pipelines are a must for any ML system. Often the Data Team, comprising Data and ML Engineers , needs to build this infrastructure, and this experience can be painful. However, efficient use of ETL pipelines in ML can help make their life much easier.
The growth of the AI and Machine Learning (ML) industry has continued to grow at a rapid rate over recent years. Hidden Technical Debt in Machine Learning Systems More money, more problems — Rise of too many ML tools 2012 vs 2023 — Source: Matt Turck People often believe that money is the solution to a problem.
Machine learning (ML) is the technology that automates tasks and provides insights. It allows datascientists to build models that can automate specific tasks. It comes in many forms, with a range of tools and platforms designed to make working with ML more efficient. It also has ML algorithms built into the platform.
Instead, organizations are increasingly looking to take advantage of transformative technologies like machine learning (ML) and artificial intelligence (AI) to deliver innovative products, improve outcomes, and gain operational efficiencies at scale. Data is presented to the personas that need access using a unified interface.
Amazon SageMaker is a fully managed machine learning (ML) service. With SageMaker, datascientists and developers can quickly and easily build and train ML models, and then directly deploy them into a production-ready hosted environment. We add this data to Snowflake as a new table.
Machine learning (ML) has become a critical component of many organizations’ digital transformation strategy. From predicting customer behavior to optimizing business processes, ML algorithms are increasingly being used to make decisions that impact business outcomes.
The onset of the pandemic has triggered a rapid increase in the demand and adoption of ML technology. Building ML team Following the surge in ML use cases that have the potential to transform business, the leaders are making a significant investment in ML collaboration, building teams that can deliver the promise of machine learning.
Automation Automating datapipelines and models ➡️ 6. Team Building the right data science team is complex. With a range of role types available, how do you find the perfect balance of DataScientists , Data Engineers and Data Analysts to include in your team? Big Ideas What to look out for in 2022 1.
Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. SageMaker Studio is the first fully integrated development environment (IDE) for ML. Solution overview The following diagram illustrates the solution architecture for each option.
For instance, a Data Science team analysing terabytes of data can instantly provision additional processing power or storage as required, avoiding bottlenecks and delays. This scalability ensures DataScientists can experiment with large datasets without worrying about infrastructure constraints.
Alignment to other tools in the organization’s tech stack Consider how well the MLOps tool integrates with your existing tools and workflows, such as data sources, data engineering platforms, code repositories, CI/CD pipelines, monitoring systems, etc. and Pandas or Apache Spark DataFrames.
As today’s world keeps progressing towards data-driven decisions, organizations must have quality data created from efficient and effective datapipelines. For customers in Snowflake, Snowpark is a powerful tool for building these effective and scalable datapipelines.
With all this packaged into a well-governed platform, Snowflake continues to set the standard for data warehousing and beyond. Snowflake supports data sharing and collaboration across organizations without the need for complex datapipelines. One of the standout features of Dataiku is its focus on collaboration.
Machine learning (ML) engineer Potential pay range – US$82,000 to 160,000/yr Machine learning engineers are the bridge between data science and engineering. Integrating the knowledge of data science with engineering skills, they can design, build, and deploy machine learning (ML) models.
The ZMP analyzes billions of structured and unstructured data points to predict consumer intent by using sophisticated artificial intelligence (AI) to personalize experiences at scale. Hosted on Amazon ECS with tasks run on Fargate, this platform streamlines the end-to-end ML workflow, from data ingestion to model deployment.
According to IDC , 83% of CEOs want their organizations to be more data-driven. Datascientists could be your key to unlocking the potential of the Information Revolution—but what do datascientists do? What Do DataScientists Do? Datascientists drive business outcomes. Download Now.
This makes managing and deploying these updates across a large-scale deployment pipeline while providing consistency and minimizing downtime a significant undertaking. Generative AI applications require continuous ingestion, preprocessing, and formatting of vast amounts of data from various sources.
Statistical methods and machine learning (ML) methods are actively developed and adopted to maximize the LTV. In this post, we share how Kakao Games and the Amazon Machine Learning Solutions Lab teamed up to build a scalable and reliable LTV prediction solution by using AWS data and ML services such as AWS Glue and Amazon SageMaker.
The role of a datascientist is in demand and 2023 will be no exception. To get a better grip on those changes we reviewed over 25,000 datascientist job descriptions from that past year to find out what employers are looking for in 2023. Data Science Of course, a datascientist should know data science!
Since 2018, our team has been developing a variety of ML models to enable betting products for NFL and NCAA football. Our datascientists train the model in Python using tools like PyTorch and save the model as PyTorch scripts. Business requirements We are the US squad of the Sportradar AI department.
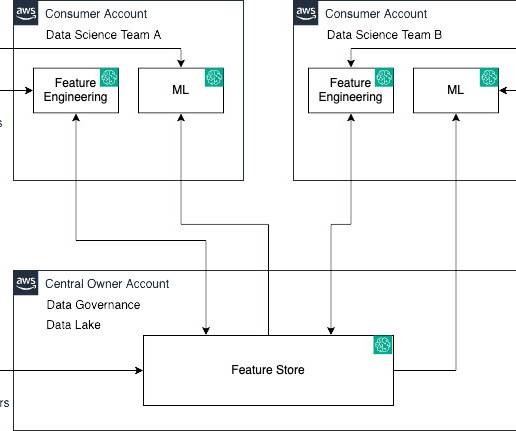
Amazon SageMaker Feature Store is a fully managed, purpose-built repository to store, share, and manage features for machine learning (ML) models. Features are inputs to ML models used during training and inference. Their task is to construct and oversee efficient datapipelines.
Instead, businesses tend to rely on advanced tools and strategies—namely artificial intelligence for IT operations (AIOps) and machine learning operations (MLOps)—to turn vast quantities of data into actionable insights that can improve IT decision-making and ultimately, the bottom line.
Since AI is a central pillar of their value offering, Sense has invested heavily in a robust engineering organization including a large number of data and AI professionals. This includes a data team, an analytics team, DevOps, AI/ML, and a data science team. Gennaro Frazzingaro, Head of AI/ML at Sense.
The following diagram illustrates the datapipeline for indexing and query in the foundational search architecture. Ingest Pipeline With ingest pipelines, you can process, transform, and route data efficiently, maintaining smooth data flows and real-time accessibility for search.
This includes a data team, an analytics team, DevOps, AI/ML, and a data science team. The AI/Ml team is made up of ML engineers, datascientists and backend product engineers. With Iguazio, Sense’s data professionals can pull data, analyze it, train and run experiments.
As companies continue to adopt machine learning (ML) in their workflows, the demand for scalable and efficient tools has increased. In this blog post, we will explore the performance benefits of Snowpark for ML workloads and how it can help businesses make better use of their data. Want to learn more? Can’t wait?
Unleashing Innovation and Success: Comet — The Trusted ML Platform for Enterprise Environments Machine learning (ML) is a rapidly developing field, and businesses are increasingly depending on ML platforms to fuel innovation, improve efficiency, and mine data for insights.
Building generative AI applications presents significant challenges for organizations: they require specialized ML expertise, complex infrastructure management, and careful orchestration of multiple services. An expert in AI/ML and generative AI, Ameer helps customers unlock the potential of these cutting-edge technologies.
SageMaker geospatial capabilities make it straightforward for datascientists and machine learning (ML) engineers to build, train, and deploy models using geospatial data. Janosch Woschitz is a Senior Solutions Architect at AWS, specializing in AI/ML. Outside work, he is a travel enthusiast.
This guide unlocks the path from Data Analyst to DataScientist Architect. So if you are looking forward to a Data Science career , this blog will work as a guiding light. The Insights This comprehensive guide, updated for 2024, delves into the challenges and strategies associated with scaling Data Science careers.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
Heres what we noticed from analyzing this data, highlighting whats remained the same over the years, and what additions help make the modern datascientist in2025. Data Science Of course, a datascientist should know data science! Joking aside, this does infer particular skills.
From gathering and processing data to building models through experiments, deploying the best ones, and managing them at scale for continuous value in production—it’s a lot. As the number of ML-powered apps and services grows, it gets overwhelming for datascientists and ML engineers to build and deploy models at scale.
Machine learning (ML) is becoming increasingly complex as customers try to solve more and more challenging problems. This complexity often leads to the need for distributed ML, where multiple machines are used to train a single model. SageMaker is a fully managed service for building, training, and deploying ML models.
Long-term ML project involves developing and sustaining applications or systems that leverage machine learning models, algorithms, and techniques. An example of a long-term ML project will be a bank fraud detection system powered by ML models and algorithms for pattern recognition. 2 Ensuring and maintaining high-quality data.
MLOps accelerates the ML model deployment process to make it more efficient and scalable. In this blog post, we detail the steps you need to take to build and run a successful MLOps pipeline. An extension of DevOps, MLOps streamlines and monitors ML workflows. MLOps pipelines support a production-first approach.
Its goal is to help with a quick analysis of target characteristics, training vs testing data, and other such data characterization tasks. Apache Superset GitHub | Website Apache Superset is a must-try project for any ML engineer, datascientist, or data analyst. You can watch it on demand here.
Every organization needs data to make many decisions. The data is ever-increasing, and getting the deepest analytics about their business activities requires technical tools, analysts, and datascientists to explore and gain insight from large data sets. That is very cheap compared to traditional data warehouses.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
























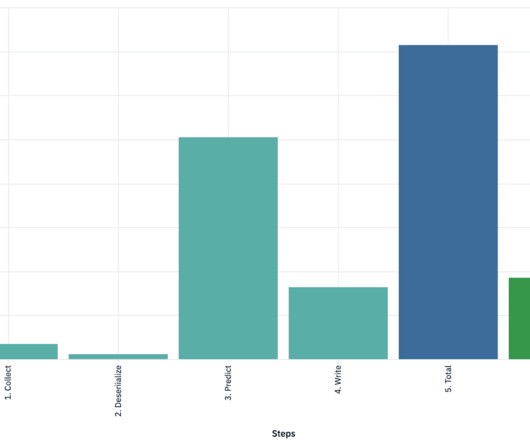


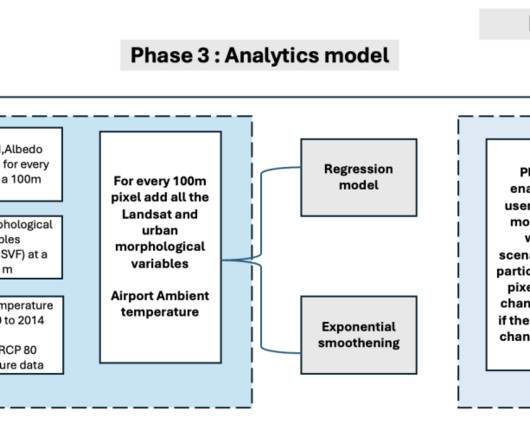




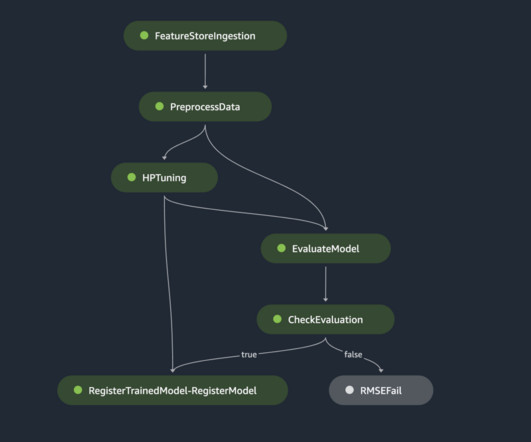










Let's personalize your content