This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
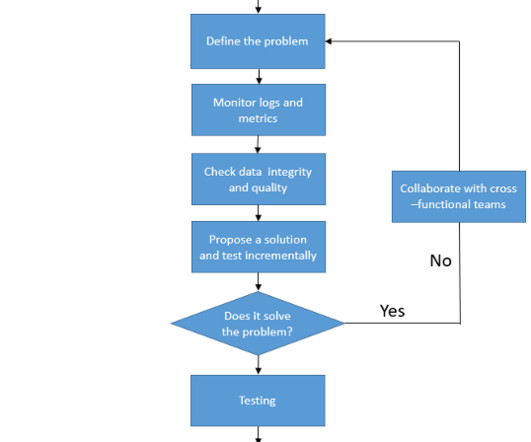
Big datapipelines are the backbone of modern data processing, enabling organizations to collect, process, and analyze vast amounts of data in real-time. Issues such as data inconsistencies, performance bottlenecks, and failures are inevitable.In Validate data format and schema compatibility.
Follow five essential steps for success in making your data AI ready with data integration. Define clear goals, assess your data landscape, choose the right tools, ensure dataquality and governance, and continuously optimize your integration processes.
Summary: Dataquality is a fundamental aspect of Machine Learning. Poor-qualitydata leads to biased and unreliable models, while high-qualitydata enables accurate predictions and insights. What is DataQuality in Machine Learning? Bias in data can result in unfair and discriminatory outcomes.
As such, the quality of their data can make or break the success of the company. This article will guide you through the concept of a dataquality framework, its essential components, and how to implement it effectively within your organization. What is a dataquality framework?
It seems straightforward at first for batch data, but the engineering gets even more complicated when you need to go from batch data to incorporating real-time and streaming data sources, and from batch inference to real-time serving. Without the capabilities of Tecton , the architecture might look like the following diagram.
In this blog, we are going to unfold the two key aspects of data management that is Data Observability and DataQuality. Data is the lifeblood of the digital age. Today, every organization tries to explore the significant aspects of data and its applications.
When needed, the system can access an ODAP data warehouse to retrieve additional information. Document management Documents are securely stored in Amazon S3, and when new documents are added, a Lambda function processes them into chunks. Emel Mendoza is a Senior Solutions Architect at AWS based in the Netherlands.
“Quality over Quantity” is a phrase we hear regularly in life, but when it comes to the world of data, we often fail to adhere to this rule. DataQuality Monitoring implements quality checks in operational data processes to ensure that the data meets pre-defined standards and business rules.
The raw data can be fed into a database or data warehouse. An analyst can examine the data using business intelligence tools to derive useful information. . To arrange your data and keep it raw, you need to: Make sure the datapipeline is simple so you can easily move data from point A to point B.
User support arrangements Consider the availability and quality of support from the provider or vendor, including documentation, tutorials, forums, customer service, etc. Check out the Kubeflow documentation. Metaflow Metaflow helps data scientists and machine learning engineers build, manage, and deploy data science projects.
Data Observability and DataQuality are two key aspects of data management. The focus of this blog is going to be on Data Observability tools and their key framework. The growing landscape of technology has motivated organizations to adopt newer ways to harness the power of data. What is Data Observability?
The agent knowledge base stores Amazon Bedrock service documentation, while the cache knowledge base contains curated and verified question-answer pairs. For this example, you will ingest Amazon Bedrock documentation in the form of the User Guide PDF into the Amazon Bedrock knowledge base. This will be the primary dataset.
With data catalogs, you won’t have to waste time looking for information you think you have. Once your information is organized, a data observability tool can take your dataquality efforts to the next level by managing data drift or schema drift before they break your datapipelines or affect any downstream analytics applications.
Amazon DocumentDB is a fully managed native JSON document database that makes it straightforward and cost-effective to operate critical document workloads at virtually any scale without managing infrastructure. On the Analyses tab, choose DataQuality and Insights Report. Choose Predictive analysis , then choose Create.
The entire generative AI pipeline hinges on the datapipelines that empower it, making it imperative to take the correct precautions. 4 key components to ensure reliable data ingestion Dataquality and governance: Dataquality means ensuring the security of data sources, maintaining holistic data and providing clear metadata.
Best Practices for ETL Efficiency Maximising efficiency in ETL (Extract, Transform, Load) processes is crucial for organisations seeking to harness the power of data. Implementing best practices can improve performance, reduce costs, and improve dataquality.
For any data user in an enterprise today, data profiling is a key tool for resolving dataquality issues and building new data solutions. In this blog, we’ll cover the definition of data profiling, top use cases, and share important techniques and best practices for data profiling today.
DataQuality Now that you’ve learned more about your data and cleaned it up, it’s time to ensure the quality of your data is up to par. With these data exploration tools, you can determine if your data is accurate, consistent, and reliable. You can watch it on demand here.
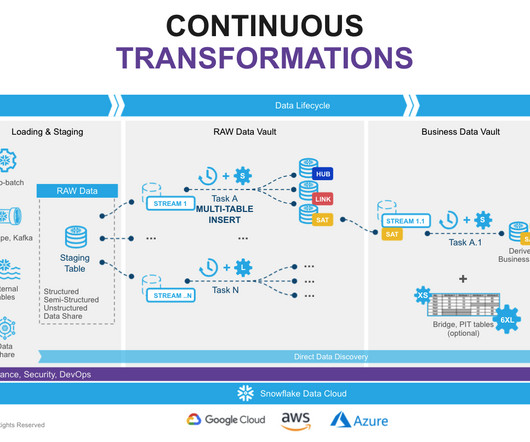
That said, dbt provides the ability to generate data vault models and also allows you to write your data transformations using SQL and code-reusable macros powered by Jinja2 to run your datapipelines in a clean and efficient way. The most important reason for using DBT in Data Vault 2.0
As a Data Analyst, you’ve honed your skills in data wrangling, analysis, and communication. But the allure of tackling large-scale projects, building robust models for complex problems, and orchestrating datapipelines might be pushing you to transition into Data Science architecture.
It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing datapipelines. Additionally, Feast promotes feature reuse, so the time spent on data preparation is reduced greatly.
Although data scientists rightfully capture the spotlight, future-focused teams also include engineers building datapipelines, visualization experts, and project managers who integrate efforts across groups. Usability Do interfaces and documentation enable business analysts and data scientists to leverage systems?
Systems and data sources are more interconnected than ever before. A broken datapipeline might bring operational systems to a halt, or it could cause executive dashboards to fail, reporting inaccurate KPIs to top management. Old-school methods of managing dataquality are no longer sufficient.
Top contenders like Apache Airflow and AWS Glue offer unique features, empowering businesses with efficient workflows, high dataquality, and informed decision-making capabilities. Introduction In today’s business landscape, data integration is vital. It is part of IBM’s Infosphere Information Server ecosystem.
Elementl / Dagster Labs Elementl and Dagster Labs are both companies that provide platforms for building and managing datapipelines. Elementl’s platform is designed for data engineers, while Dagster Labs’ platform is designed for data scientists. However, there are some critical differences between the two companies.
Summary: Data transformation tools streamline data processing by automating the conversion of raw data into usable formats. These tools enhance efficiency, improve dataquality, and support Advanced Analytics like Machine Learning. The right tool can significantly enhance efficiency, scalability, and dataquality.
Precisely conducted a study that found that within enterprises, data scientists spend 80% of their time cleaning, integrating and preparing data , dealing with many formats, including documents, images, and videos. Overall placing emphasis on establishing a trusted and integrated data platform for AI.
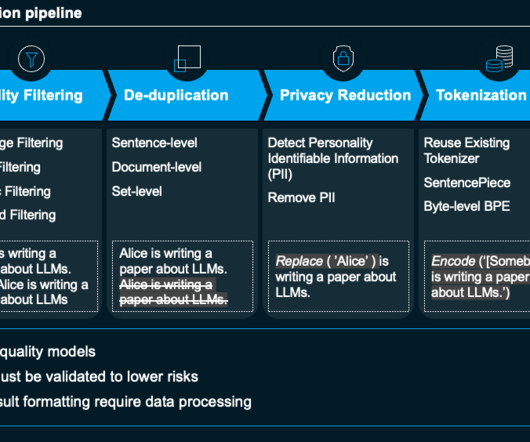
Sources of Data in the Pile The Pile draws from a variety of sources to ensure richness and reliability. Open-access books, encyclopedias, and government documents offer well-structured, factual content. It also features data from novels, legal documents, and medical texts.
Unconstrained, long, open-ended generation that may expose harmful or biased content to users, like legal document creation. The required architecture includes a datapipeline, ML pipeline, application pipeline and a multi-stage pipeline. Let’s dive into the data management pipeline.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
Semi-Structured Data: Data that has some organizational properties but doesn’t fit a rigid database structure (like emails, XML files, or JSON data used by websites). Unstructured Data: Data with no predefined format (like text documents, social media posts, images, audio files, videos).
How do you get executives to understand the value of data governance? First, document your successes of good data, and how it happened. Share stories of data in good times and in bad (pictures help!). Some data seems more analytical, while other is operational (external facing). Seeing is believing!
Securing AI models and their access to data While AI models need flexibility to access data across a hybrid infrastructure, they also need safeguarding from tampering (unintentional or otherwise) and, especially, protected access to data. This allows for a high degree of transparency and auditability.
Homogeneity, Completeness, and V-measure - Measures different aspects of cluster quality, such as the extent to which each cluster contains only samples from a single class (homogeneity), the extent to which all samples from the same class are assigned to the same cluster (completeness), and their harmonic mean (V-measure).
dbt offers a SQL-first transformation workflow that lets teams build data transformation pipelines while following software engineering best practices like CI/CD, modularity, and documentation. Aside from migrations, Data Source is also great for dataquality checks and can generate datapipelines.
Monitoring and Alerts: Set up monitoring and alert systems that quickly notify teams of any data integration issues. Regular Audits: Conduct periodic audits of your datapipelines to identify and address inefficiencies or dataquality concerns.
Data as the foundation of what the business does is great – but how do you support that? What technology or platform can meet the needs of the business, from basic report creation to complex document analysis to machine learning workflows? The Snowflake AI Data Cloud is the platform that will support that and much more!
Data science and machine learning teams use Snorkel Flow’s programmatic labeling to intelligently capture knowledge from various sources such as previously labeled data (even when imperfect), heuristics from subject matter experts, business logic, and even the latest foundation models, then scale this knowledge to label large quantities of data.
Data science and machine learning teams use Snorkel Flow’s programmatic labeling to intelligently capture knowledge from various sources such as previously labeled data (even when imperfect), heuristics from subject matter experts, business logic, and even the latest foundation models, then scale this knowledge to label large quantities of data.
Real-time processing is essential for applications requiring immediate data insights. Support : Are there resources available for troubleshooting, such as documentation, forums, or customer support? Security : Does the tool ensure data privacy and security during the ETL process?
This includes ML experts who can develop, train and deploy models, DevOps engineers for the operational aspects, including CI/CD pipelines, monitoring, and ML infrastructure management, developers to build the platform's UI, APIs, and other software components, and data engineers for managing datapipelines, storage, and ensuring dataquality.
“You need to find a place to park your data. It needs to be optimized for the type of data and the format of the data you have,” he said. By optimizing every part of the datapipeline, he said, “You will, as a result, get your models to market faster.”
“You need to find a place to park your data. It needs to be optimized for the type of data and the format of the data you have,” he said. By optimizing every part of the datapipeline, he said, “You will, as a result, get your models to market faster.”
Documenting Objectives: Create a comprehensive document outlining the project scope, goals, and success criteria to ensure all parties are aligned. This step includes: Identifying Data Sources: Determine where data will be sourced from (e.g., accuracy, precision). databases, APIs, CSV files).
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content