This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Let’s explore each of these components and its application in the sales domain: Synapse Data Engineering: Synapse Data Engineering provides a powerful Spark platform designed for large-scale data transformations through Lakehouse. Here, we changed the data types of columns and dealt with missing values.
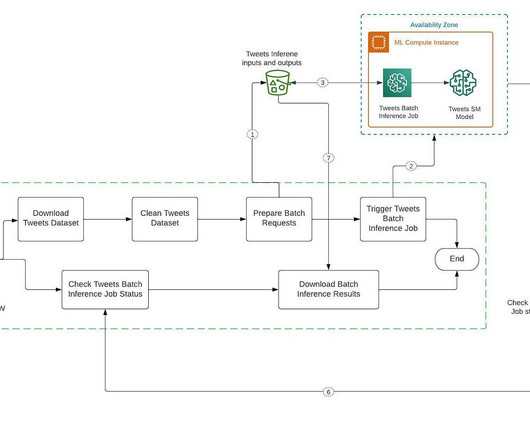
Automate and streamline our ML inference pipeline with SageMaker and Airflow Building an inference datapipeline on large datasets is a challenge many companies face. Check Tweets Batch Inference Job Status: Create an SQS listener that reads a message from the queue when the event rule publishes it.
The result of these events can be evaluated afterwards so that they make better decisions in the future. With this proactive approach, Kakao Games can launch the right events at the right time. Kakao Games can then create a promotional event not to leave the game. However, this approach is reactive.
Introduction The Formula 1 Prediction Challenge: 2024 Mexican Grand Prix brought together data scientists to tackle one of the most dynamic aspects of racing — pit stop strategies. With every second on the track critical, the challenge showcased how data can shape decisions that define race outcomes.
MLOps aims to bridge the gap between data science and operational teams so they can reliably and efficiently transition ML models from development to production environments, all while maintaining high model performance and accuracy. AIOps integrates these models into existing IT systems to enhance their functions and performance.
The solution focuses on the fundamental principles of developing an AI/ML application workflow of datapreparation, model training, model evaluation, and model monitoring. Tayo Olajide is a seasoned Cloud Data Engineering generalist with over a decade of experience in architecting and implementing data solutions in cloud environments.
That means feeding them streams of high-quality information about user actions, events, and context in real time. So, what exactly is AI-ready data? Simply put, AI-ready data is structured, high-quality information that can be easily used to train machine learning models and run AI applications with minimal engineering effort .
Enterprise data architects, data engineers, and business leaders from around the globe gathered in New York last week for the 3-day Strata Data Conference , which featured new technologies, innovations, and many collaborative ideas. We look at data as an asset, regardless of whether the use case is AML/fraud or new revenue.
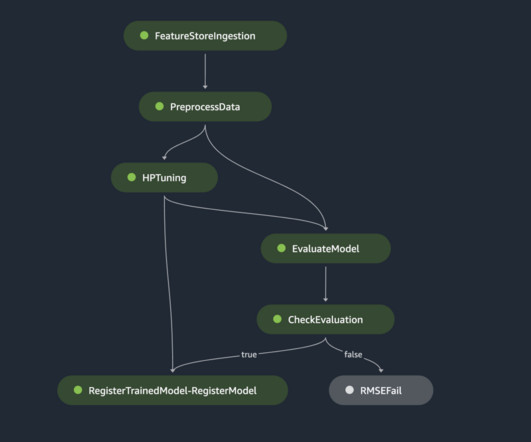
Amazon SageMaker Pipelines allows orchestrating the end-to-end ML lifecycle from datapreparation and training to model deployment as automated workflows. We set up an end-to-end Ray-based ML workflow, orchestrated using SageMaker Pipelines. Ingest the prepareddata into the feature group by using the Boto3 SDK.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. They are crucial in ensuring data is readily available for analysis and reporting.
See also Thoughtworks’s guide to Evaluating MLOps Platforms End-to-end MLOps platforms End-to-end MLOps platforms provide a unified ecosystem that streamlines the entire ML workflow, from datapreparation and model development to deployment and monitoring. Flyte Flyte is a platform for orchestrating ML pipelines at scale.
DataRobot now delivers both visual and code-centric datapreparation and datapipelines, along with automated machine learning that is composable, and can be driven by hosted notebooks or a graphical user experience. Virtual Event. Learn More About DataRobot’s Vision and Roadmap for AI Cloud. September 23.
Many mistakenly equate tabular data with business intelligence rather than AI, leading to a dismissive attitude toward its sophistication. Standard data science practices could also be contributing to this issue. One might say that tabular data modeling is the original data-centric AI!
Continuous monitoring of resources, data, and metrics. DataPipeline - Manages and processes various data sources. ML Pipeline - Focuses on training, validation and deployment. Application Pipeline - Manages requests and data/model validations. Collecting feedback for further tuning.
Datapreparation, train and tune, deploy and monitor. We have datapipelines and datapreparation. In the datapipeline phase—I’m just going to call out things that I think are more important than the obvious. So the basic ones: you collect and validate and preparedata.
Datapreparation, train and tune, deploy and monitor. We have datapipelines and datapreparation. In the datapipeline phase—I’m just going to call out things that I think are more important than the obvious. So the basic ones: you collect and validate and preparedata.
Socio-political events have also caused delays and issues, such as a COVID backlog, and with inert gases for manufacturing coming from Russia. For a given LOB, some events might be applicable to individual price levels independently. An important part of the datapipeline is the production of features, both online and offline.
DataPreparation: Cleaning, transforming, and preparingdata for analysis and modelling. Data Scientists can use Azure Data Factory to preparedata for analysis by creating datapipelines that ingest data from multiple sources, clean and transform it, and load it into Azure data stores.
Amazon SageMaker Catalog serves as a central repository hub to store both technical and business catalog information of the data product. To establish trust between the data producers and data consumers, SageMaker Catalog also integrates the data quality metrics and data lineage events to track and drive transparency in datapipelines.
David: My technical background is in ETL, data extraction, data engineering and data analytics. I spent over a decade of my career developing large-scale datapipelines to transform both structured and unstructured data into formats that can be utilized in downstream systems.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.























Let's personalize your content