

Analyze security findings faster with no-code data preparation using generative AI and Amazon SageMaker Canvas
AWS Machine Learning Blog
FEBRUARY 1, 2024
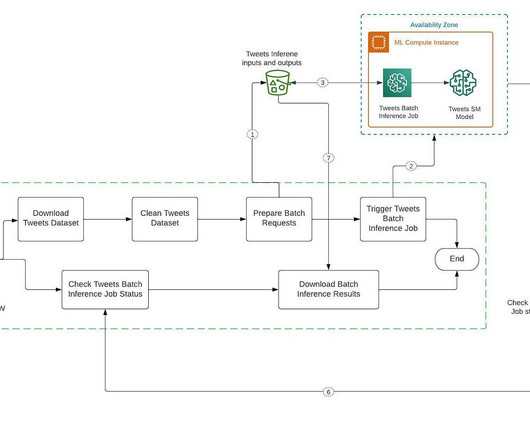
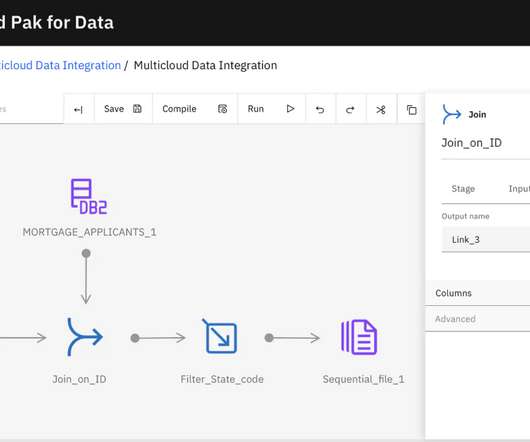
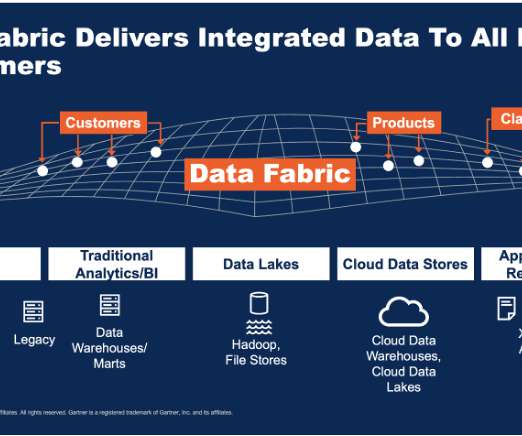
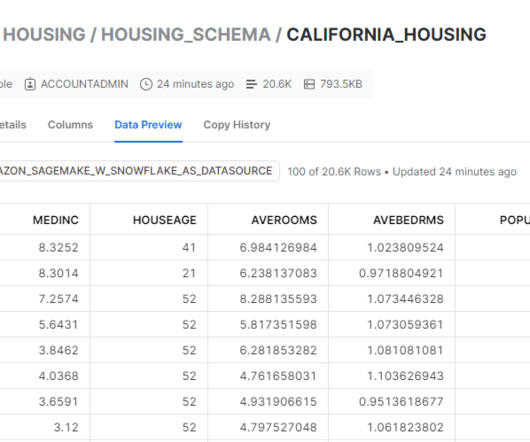
To unlock the potential of generative AI technologies, however, there’s a key prerequisite: your data needs to be appropriately prepared. In this post, we describe how use generative AI to update and scale your data pipeline using Amazon SageMaker Canvas for data prep.
































Let's personalize your content