
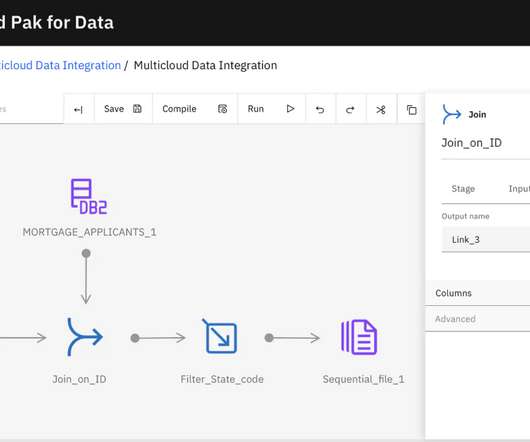
Data Threads: Address Verification Interface
IBM Data Science in Practice
DECEMBER 7, 2022
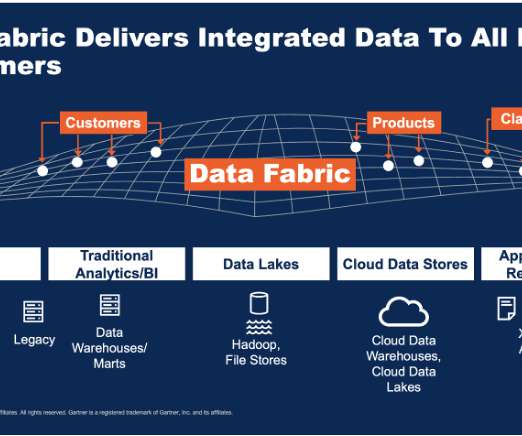
One of the key elements that builds a data fabric architecture is to weave integrated data from many different sources, transform and enrich data, and deliver it to downstream data consumers. Studies have shown that 80% of time is spent on data preparation and cleansing, leaving only 20% of time for data analytics.









Let's personalize your content