This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Summary: Hydra simplifies process configuration in MachineLearning by dynamically managing parameters, organising configurations hierarchically, and enabling runtime overrides. As the global MachineLearning market, valued at USD 35.80 These issues can hinder experimentation, reproducibility, and workflow efficiency.
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. It integrates well with other Google Cloud services and supports advanced analytics and machinelearning features.
The following points illustrates some of the main reasons why data versioning is crucial to the success of any data science and machinelearning project: Storage space One of the reasons of versioning data is to be able to keep track of multiple versions of the same data which obviously need to be stored as well.
Data quality is ownership of the consuming applications or data producers. Governance The two key areas of governance are model and data: Model governance Monitor model for performance, robustness, and fairness. Model versions should be managed centrally in a model registry.
How to evaluate MLOps tools and platforms Like every software solution, evaluating MLOps (MachineLearning Operations) tools and platforms can be a complex task as it requires consideration of varying factors. An integrated model factory to develop, deploy, and monitor models in one place using your preferred tools and languages.
Join us for a month-long celebration of open-source contributions to MachineLearning and AI projects. Gain hands-on experience building datasets, models, pipelines, and more! How to participate in DagsHub's MachineLearning Challenge during Hacktoberfest? Image by Hacktoberfest What is DagsHub?
In addition to its groundbreaking AI innovations, Zeta Global has harnessed Amazon Elastic Container Service (Amazon ECS) with AWS Fargate to deploy a multitude of smaller models efficiently. Zeta’s AI innovation is powered by a proprietary machinelearning operations (MLOps) system, developed in-house.
Building machinelearningmodels is a highly iterative process. After building a simple MVP for our project, we will most likely carry out a series of experiments in which we try out different models (along with their hyperparameters), create or add various features, or utilize data preprocessing techniques.
Summary: Data engineering tools streamline data collection, storage, and processing. Learning these tools is crucial for building scalable datapipelines. offers Data Science courses covering these tools with a job guarantee for career growth. Below are 20 essential tools every data engineer should know.
Unstructured data makes up 80% of the world's data and is growing. Managing unstructured data is essential for the success of machinelearning (ML) projects. Without structure, data is difficult to analyze and extracting meaningful insights and patterns is challenging.
Overview: Data science vs data analytics Think of data science as the overarching umbrella that covers a wide range of tasks performed to find patterns in large datasets, structure data for use, train machinelearningmodels and develop artificial intelligence (AI) applications.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Read more to know.
Leveraging Looker’s semantic layer will provide Tableau customers with trusted, governed data at every stage of their analytics journey. With its LookML modeling language, Looker provides a unique, modern approach to define governed and reusable datamodels to build a trusted foundation for analytics.
Institute of Analytics The Institute of Analytics is a non-profit organization that provides data science and analytics courses, workshops, certifications, research, and development. The courses and workshops cover a wide range of topics, from basic data science concepts to advanced machinelearning techniques.
Summary: The fundamentals of Data Engineering encompass essential practices like datamodelling, warehousing, pipelines, and integration. Understanding these concepts enables professionals to build robust systems that facilitate effective data management and insightful analysis. What is Data Engineering?
In today’s landscape, AI is becoming a major focus in developing and deploying machinelearningmodels. It isn’t just about writing code or creating algorithms — it requires robust pipelines that handle data, model training, deployment, and maintenance.
If you will ask data professionals about what is the most challenging part of their day to day work, you will likely discover their concerns around managing different aspects of data before they get to graduate to the datamodeling stage. This ensures that the data is accurate, consistent, and reliable.
Leveraging Looker’s semantic layer will provide Tableau customers with trusted, governed data at every stage of their analytics journey. With its LookML modeling language, Looker provides a unique, modern approach to define governed and reusable datamodels to build a trusted foundation for analytics.
Source: [link] Similarly, while building any machinelearning-based product or service, training and evaluating the model on a few real-world samples does not necessarily mean the end of your responsibilities. You need to make that model available to the end users, monitor it, and retrain it for better performance if needed.
In order to fully leverage this vast quantity of collected data, companies need a robust and scalable data infrastructure to manage it. This is where Fivetran and the Modern Data Stack come in. Datamodeling, data cleanup, etc. Click on the link above to learn more! What is Fivetran?
It includes processes that trace and document the origin of data, models and associated metadata and pipelines for audits. An AI governance framework ensures the ethical, responsible and transparent use of AI and machinelearning (ML).
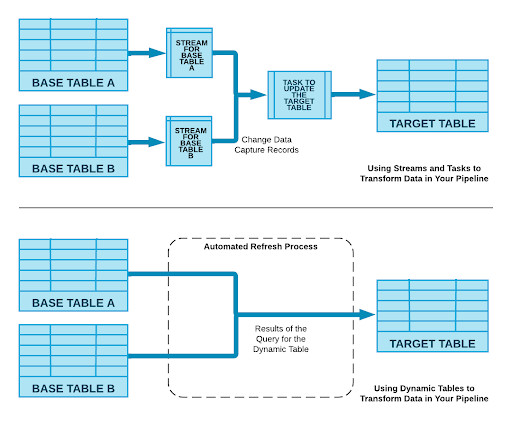
Managing datapipelines efficiently is paramount for any organization. The Snowflake Data Cloud has introduced a groundbreaking feature that promises to simplify and supercharge this process: Snowflake Dynamic Tables. If you’re looking to leverage the full power of the Snowflake Data Cloud, let phData be your guide.
Building ML team Following the surge in ML use cases that have the potential to transform business, the leaders are making a significant investment in ML collaboration, building teams that can deliver the promise of machinelearning. Team composition The team comprises domain experts, data engineers, data scientists, and ML engineers.
For example, a data scientist would be a good fit for a team that is in charge of handling large swaths of data and creating actionable insights from them. In another industry what matters is being able to predict behaviors in the medium and short terms, and this is where a machinelearning engineer might come to play.
It is the process of converting raw data into relevant and practical knowledge to help evaluate the performance of businesses, discover trends, and make well-informed choices. Data gathering, data integration, datamodelling, analysis of information, and data visualization are all part of intelligence for businesses.
The future of business depends on artificial intelligence and machinelearning. According to IDC , 83% of CEOs want their organizations to be more data-driven. Data scientists could be your key to unlocking the potential of the Information Revolution—but what do data scientists do? What Do Data Scientists Do?
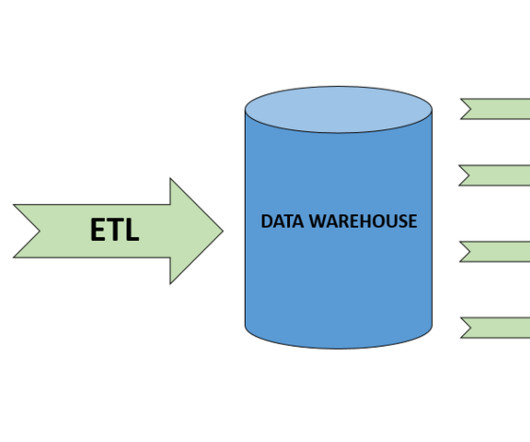
By maintaining historical data from disparate locations, a data warehouse creates a foundation for trend analysis and strategic decision-making. Integrating seamlessly with other Google Cloud services, BigQuery is a powerful solution for organizations seeking efficient and cost-effective large-scale data analysis.
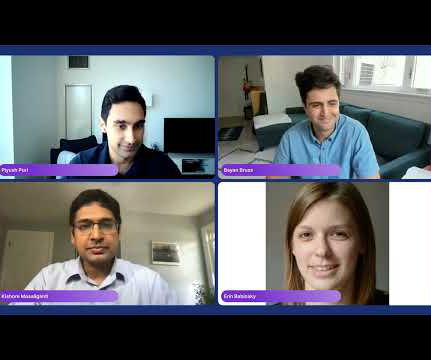
Three experts from Capital One ’s data science team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of Data Science, Erin Babinski; and Head of Data and MachineLearning, Kishore Mosaliganti.
Three experts from Capital One ’s data science team spoke as a panel at our Future of Data-Centric AI conference in 2022. Please welcome to the stage, Senior Director of Applied ML and Research, Bayan Bruss; Director of Data Science, Erin Babinski; and Head of Data and MachineLearning, Kishore Mosaliganti.
LLMOps (Large Language Model Operations), is a specialized domain within the broader field of machinelearning operations (MLOps). LLMOps focuses specifically on the operational aspects of large language models (LLMs). DataPipeline - Manages and processes various data sources. What is LLMOps?
Generative AI can be used to automate the datamodeling process by generating entity-relationship diagrams or other types of datamodels and assist in UI design process by generating wireframes or high-fidelity mockups. GPT-4 DataPipelines: Transform JSON to SQL Schema Instantly Blockstream’s public Bitcoin API.
Security is Paramount Implement robust security measures to protect sensitive time series data. Integration with DataPipelines and Analytics TSDBs often work in tandem with other data tools to create a comprehensive data ecosystem for analysis and insights generation.
By leveraging version control, testing, and documentation features, dbt Core enables teams to ensure data quality and consistency across their pipelines while integrating seamlessly with modern data warehouses. Aside from migrations, Data Source is also great for data quality checks and can generate datapipelines.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, data lakes , data sharing, and engineering. MachineLearning Integration Opportunities Organizations harness machinelearning (ML) algorithms to make forecasts on the data.
Many mistakenly equate tabular data with business intelligence rather than AI, leading to a dismissive attitude toward its sophistication. Standard data science practices could also be contributing to this issue. One might say that tabular datamodeling is the original data-centric AI!
How can we build up toward our vision in terms of solvable data problems and specific data products? data sources or simpler datamodels) of the data products we want to build? Data science — The discipline within the organization that makes data products. What are we working towards?
IBM Infosphere DataStage IBM Infosphere DataStage is an enterprise-level ETL tool that enables users to design, develop, and run datapipelines. Key Features: Graphical Framework: Allows users to design datapipelines with ease using a graphical user interface. Read Further: Azure Data Engineer Jobs.
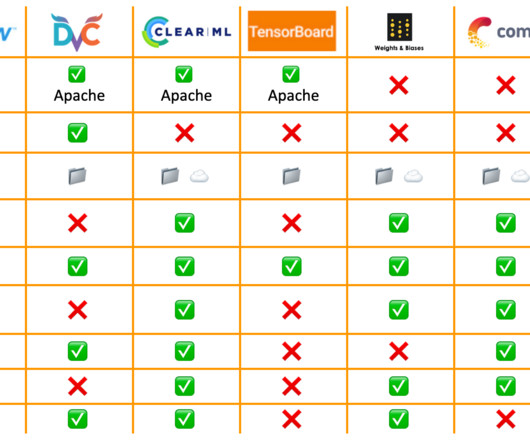
Source: Author Introduction Machinelearning (ML) models, like other software, are constantly changing and evolving. Version control systems (VCS) play a key role in this area by offering a structured method to track changes made to models and handle versions of data and code used in these ML projects.
Advanced Analytics: Snowflake’s platform is purposefully engineered to cater to the demands of machinelearning and AI-driven data science applications in a cost-effective manner. Efficient Sharing: Sigma provides several easy but secure ways to share data and analytics internally and externally.
Introduction: The Customer DataModeling Dilemma You know, that thing we’ve been doing for years, trying to capture the essence of our customers in neat little profile boxes? For years, we’ve been obsessed with creating these grand, top-down customer datamodels. Yeah, that one.
They run scripts manually to preprocess their training data, rerun the deployment scripts, manually tune their models, and spend their working hours keeping previously developed models up to date. Building end-to-end machinelearningpipelines lets ML engineers build once, rerun, and reuse many times.
Simply put, focusing solely on data analysis, coding or modeling will no longer cuts it for most corporate jobs. These two languages cover most data science workflows. Additionally, languages like DAX can be helpful for specific use cases involving datamodels and dashboards.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content