
Testing and Monitoring Data Pipelines: Part Two
Dataversity
JUNE 19, 2023
In part one of this article, we discussed how data testing can specifically test a data object (e.g., table, column, metadata) at one particular point in the data pipeline.

Dataversity
JUNE 19, 2023
In part one of this article, we discussed how data testing can specifically test a data object (e.g., table, column, metadata) at one particular point in the data pipeline.

Data Science Dojo
JULY 6, 2023
Data engineering tools are software applications or frameworks specifically designed to facilitate the process of managing, processing, and transforming large volumes of data. Spark offers a rich set of libraries for data processing, machine learning, graph processing, and stream processing.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Data Science Connect
JANUARY 27, 2023
Data engineering is a crucial field that plays a vital role in the data pipeline of any organization. It is the process of collecting, storing, managing, and analyzing large amounts of data, and data engineers are responsible for designing and implementing the systems and infrastructure that make this possible.

The MLOps Blog
MARCH 15, 2023
If you will ask data professionals about what is the most challenging part of their day to day work, you will likely discover their concerns around managing different aspects of data before they get to graduate to the data modeling stage. This ensures that the data is accurate, consistent, and reliable.

Pickl AI
JULY 25, 2023
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create data pipelines, ETL processes, and databases to facilitate smooth data flow and storage. Big Data Processing: Apache Hadoop, Apache Spark, etc.

ODSC - Open Data Science
OCTOBER 15, 2023
Elementl / Dagster Labs Elementl and Dagster Labs are both companies that provide platforms for building and managing data pipelines. Elementl’s platform is designed for data engineers, while Dagster Labs’ platform is designed for data scientists. However, there are some critical differences between the two companies.
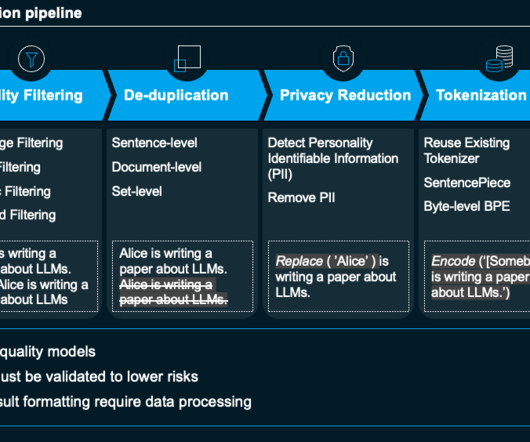
Iguazio
FEBRUARY 20, 2024
This includes management vision and strategy, resource commitment, data and tech and operating model alignment, robust risk management and change management. The required architecture includes a data pipeline, ML pipeline, application pipeline and a multi-stage pipeline. Read more here.

Expert insights. Personalized for you.



































Let's personalize your content