This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
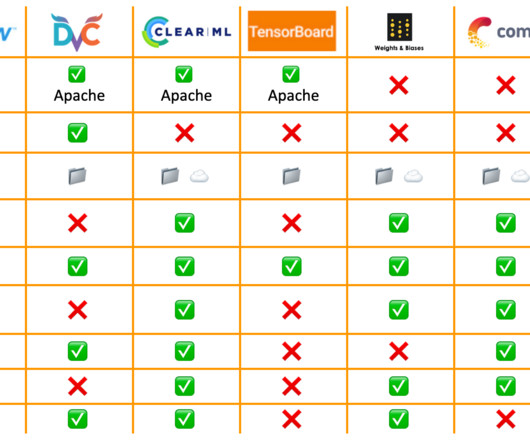
Model versioning, lineage, and packaging : Can you version and reproduce models and experiments? Can you see the complete model lineage with data/models/experiments used downstream? It could help you detect and prevent datapipeline failures, data drift, and anomalies.
Zeta’s AI innovations over the past few years span 30 pending and issued patents, primarily related to the application of deeplearning and generative AI to marketing technology. It simplifies feature access for model training and inference, significantly reducing the time and complexity involved in managing datapipelines.
In today’s landscape, AI is becoming a major focus in developing and deploying machine learningmodels. It isn’t just about writing code or creating algorithms — it requires robust pipelines that handle data, model training, deployment, and maintenance. Model Training: Running computations to learn from the data.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Data Visualization: Matplotlib, Seaborn, Tableau, etc.
Many mistakenly equate tabular data with business intelligence rather than AI, leading to a dismissive attitude toward its sophistication. Standard data science practices could also be contributing to this issue. Feature engineering activities frequently focus on single-table data transformations, leading to the infamous “yawn factor.”
Machine Learning projects evolve rapidly, frequently introducing new data , models, and hyperparameters. Use Cases in ML Workflows Hydra excels in scenarios requiring frequent parameter tuning, such as hyperparameter optimisation, multi-environment testing, and orchestrating pipelines.
Definitions: Foundation Models, Gen AI, and LLMs Before diving into the practice of productizing LLMs, let’s review the basic definitions of GenAI elements: Foundation Models (FMs) - Large deeplearningmodels that are pre-trained with attention mechanisms on massive datasets. This helps cleanse the data.
It also can minimize the risks of miscommunication in the process since the analyst and customer can align on the prototype before proceeding to the build phase Design: DALL-E, another deeplearningmodel developed by OpenAI to generate digital images from natural language descriptions, can contribute to the design of applications.
MLflow is language- and framework-agnostic, and it offers convenient integration with the most popular machine learning and deeplearning frameworks. MLflow offers automatic logging for the most popular machine learning and deeplearning libraries. It also has APIs for R and Java, and it supports REST APIs.
Once an organization has identified its AI use cases , data scientists informally explore methodologies and solutions relevant to the business’s needs in the hunt for proofs of concept. These might include—but are not limited to—deeplearning, image recognition and natural language processing.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
LLMOps focuses specifically on the operational aspects of large language models (LLMs). LLM models are large deeplearningmodels that are trained on vast datasets, are adaptable to various tasks and specialize in NLP tasks. DataPipeline - Manages and processes various data sources.
By understanding the role of each tool within the MLOps ecosystem, you'll be better equipped to design and deploy robust ML pipelines that drive business impact and foster innovation. TensorFlow TensorFlow is a popular machine learning framework developed by Google that offers the implementation of a wide range of neural network models.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



















Let's personalize your content