This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Data, undoubtedly, is one of the most significant components making up a machine learning (ML) workflow, and due to this, data management is one of the most important factors in sustaining ML pipelines.
How fresh or real-time does the data need to be? What tools and datamodels best fit our requirements? Recommended actions: Clarify the business questions your pipeline will help answer Sketch a high-level architecture diagram to align technical and business stakeholders Choose tools and design datamodels accordingly (e.g.,
Entity relationship diagrams (ERDs) are not just tools for developers; they serve as blueprints that help organizations visualize how different data elements relate to one another. Understanding ERDs can provide valuable insights into effective database design and data structure management. What is an entity relationship diagram (ERD)?
Nonrandom sampling Nonrandom sampling may be employed to prioritize more recent data for testing purposes, which is especially critical in applications involving time-series data. Applications of data splitting Data splitting lays the foundation for various applications in model development and evaluation across multiple domains.
Industry expert Jesse Simms, VP at Giant Partners, will share real-life case studies and best practices from client direct mail and digital campaigns where datamodeling strategies pinpointed audience members, increasing their propensity to respond – and buy. 📆 September 25th, 2024 at 9:30 AM PT, 12:30 PM ET, 5:30 PM BST
Data science platforms are innovative software solutions designed to integrate various technologies for machine learning and advanced analytics. They provide an environment that enables teams to collaborate effectively, manage datamodels, and derive actionable insights from large datasets.
Key Skills Proficiency in SQL is essential, along with experience in data visualization tools such as Tableau or Power BI. Strong analytical skills and the ability to work with large datasets are critical, as is familiarity with datamodeling and ETL processes.
Mechanics of data virtualization Understanding how data virtualization works reveals its benefits in organizations. Middleware role Data virtualization often functions as middleware that bridges various datamodels and repositories, including cloud data lakes and on-premise warehouses.
Ideal for data scientists and engineers working with databases and complex datamodels. Awesome SQLAlchemy: Tools for Python’s Leading ORM Link: dahlia/awesome-sqlalchemy It is a list of tools, extensions, and resources for SQLAlchemy, Python’s most popular ORM.
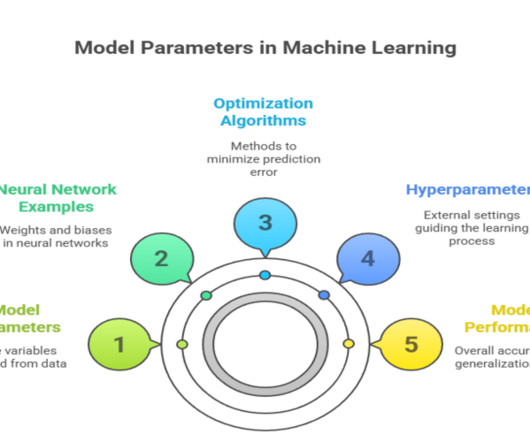
The values of these parameters are optimized iteratively to minimize prediction error, allowing the model to capture complex patterns in data. Model parameters are distinct from hyperparameters, which are set externally before training and guide the learning process itself.
LLMs — the datamodels powering your favorite AI chatbots — don't just have social and racial biases, a new report finds, but inherent biases against democratic institutions.
Sources of Hallucinations: Generalized Training Data: Models trained on non-specialized data may lack depth in healthcare-specific contexts.Probabilistic Generation: LLMs generate text based on probability, which sometimes leads them to select… Read the full blog for free on Medium.
Allen Downey (Principal Data Scientist, PyMC Labs) — Time Series and Bayesian Statistics Allen conducted workshops on time series analysis and Bayesian statistics using PyMC. From pragmatic agent-building to sophisticated evaluations and cutting-edge ethical data practices, these minisodes captured the pulse of AI innovation.
How structured data works Understanding how structured data operates involves recognizing the role of datamodels and repositories. These frameworks facilitate the organization and integrity of data across various applications. They represent the structure and constraints that govern how data is stored.
By Nate Rosidi , KDnuggets Market Trends & SQL Content Specialist on June 11, 2025 in Language Models Image by Author | Canva If you work in a data-related field, you should update yourself regularly. Data scientists use different tools for tasks like data visualization, datamodeling, and even warehouse systems.
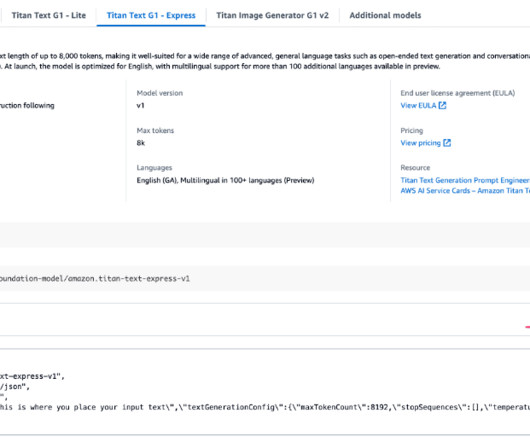
First, we define Pydantic datamodels to structure the FM output: class QTopicQuestionPair(BaseModel): """A question related to a Q topic.""" topic_id: str = Field(., First, we define Pydantic datamodels to structure the FM output: class QTopicQuestionPair(BaseModel): """A question related to a Q topic.""" topic_id: str = Field(.,
Purpose and significance of dimensions Dimensions serve multiple purposes in data warehousing, making them invaluable: Facilitating analytical queries: Dimensions allow for meaningful exploration of data, enabling complex questions to be answered efficiently.
Applications of UMAP Modern machine learning workloads demand high performance where repetitive training and hyper-parameter optimization cycles are essential for exploring high-dimensional data, model tuning, and improving model accuracy.
Essential skills of a data steward To fulfill their responsibilities effectively, data stewards should possess a blend of technical and interpersonal skills: Technical expertise: Knowledge of programming and datamodeling is crucial. Effective communication: The ability to collaborate across departments is essential.
Make sure you’re updating the datamodel ( updateTrackListData function) to handle your custom fields. . // Example: Adding a custom dropdown for speaker identification var speakerDropdown = $(' ').attr({ val(option).text(option)); text(option)); }); // Example: Adding a checkbox for quality issues var qualityCheck = $(' ').attr({
Model Development and Validation: Building machine learning models tailored to business problems such as customer churn prediction, fraud detection, or demand forecasting. Validation techniques ensure models perform well on unseen data.
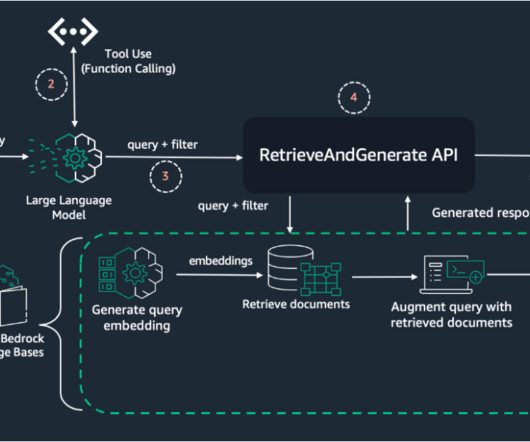
By combining the capabilities of LLM function calling and Pydantic datamodels, you can dynamically extract metadata from user queries. In this post, we explore an innovative approach that uses LLMs on Amazon Bedrock to intelligently extract metadata filters from natural language queries.
Familiar query languages: Most analytics databases support SQL and other familiar query languages, making it easier for users to query data without extensive training. Supported query languages: In addition to SQL, various query languages like MDX, GraphQL, SPARQL, and NoSQL are supported to accommodate diverse analytical needs.
Segmentation for better accuracy Dividing data into training, testing, and validation sets improves model accuracy and helps identify potential issues early in the analysis process. Setting success criteria Establishing methodologies to evaluate datamodel effectiveness is vital.
This time, well be going over DataModels for Banking, Finance, and Insurance by Claire L. This book arms the reader with a set of best practices and datamodels to help implement solutions in the banking, finance, and insurance industries. Welcome to the first Book of the Month for 2025.This
For the past 20 years, he has been helping customers build enterprise data strategies, advising them on Generative AI, cloud implementations, migrations, reference architecture creation, datamodeling best practices, and data lake/warehouse architectures.
Key Features Associative DataModel : Users can explore data freely without being confined to predefined queries. Use Cases Best for developers who need to build custom visualizations tailored specifically to their needs or those of their clients. In-Memory Processing Engine : Provides fast performance even with large datasets.
Although QLoRA reduces computational requirements and memory footprint, FSDP, a data/model parallelism technique, will help shard the model across all eight GPUs (one ml.p4d.24xlarge 24xlarge ), enabling training the model even more efficiently.
In turn, the same will happen in data engineering. Autonomous agents will re-architect the data lifecycle, from datamodelling and infrastructure-as-code to platform migrations, CI/CD, governance, and ETL pipelines. However, the greatest opportunities lie in the application layer.
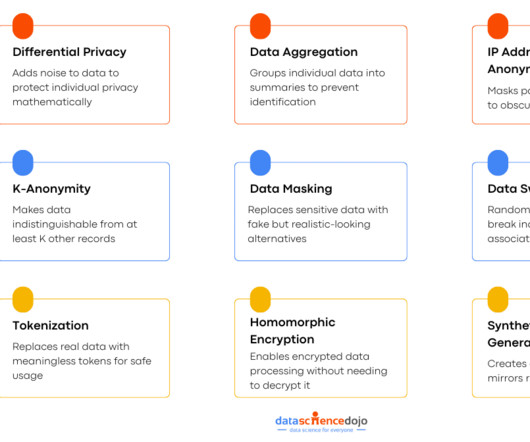
Similarly, synthetic data keeps the realism of your dataset intact while ensuring that no real individual can be traced. Data Generation : Based on what it learned, the system creates entirely new, fake records that mimic the original data without representing real individuals.
Also, you can update the model’s deploy status. Lineage ML lineage is crucial for tracking the origin, evolution, and dependencies of data, models, and code used in ML workflows, providing transparency and traceability. You can track the different statuses and activity as well.
Here’s how: ETL Pipelines : Describe your data flow in natural language, and let AI generate the code to extract, transform, and load data. Analytics Automation : Automate reporting, dashboard creation, and data validation with prompt-driven workflows. See how Context Engineering shapes reliable, context-aware LLM outputs.
And important call out not to forget the datamodeling. She shared how DeepL ’s approach to performance marketing measurement — starting small, engaging business stakeholders early, and building up to executive excitement — led to increased budgets and real business impact. And yes… we also had a lot of fun.
It is essential for creating new insights from existing datamodels in Power BI. Familiarity with Excel formulas can help, but DAX syntax is unique in its application to datamodel. Calculated Columns: New columns added to your datamodel based on DAX formulas, useful for deriving new data points from existing ones.
Machine Learning projects evolve rapidly, frequently introducing new data , models, and hyperparameters. Static and Scattered Configurations Static configurations often lead to rigid workflows that lack adaptability.
With tools like statistical modelling, businesses refine their approaches over time. As companies learn from datamodelling insights, they shape their business strategies based on real-world patterns in consumer behaviour. This constant optimisation leads to higher conversion rates and better engagement.
Day 2: Thursday, July 17th Agentic Workflows for Graph RAG: Designing for Production Amy Hodler, Executive Director of GraphGeeks.org Amy Hodler explores the fusion of graph technology with Retrieval-Augmented Generation (RAG), focusing on how graph-based datamodeling enhances context and accuracy in agentic workflows.
Paprika trains models on synthetic environments requiring different exploration behaviors, encouraging them to learn flexible strategies rather than memorizing solutions. To improve efficiency, it uses a curriculum learning-based approach that prioritizes tasks with high learning value, making the most of limited interaction data.
There are CIS graduates who just need to add machine learning and datamodeling to their toolkit. Learning AI Fundamentals Through a CIS Lens You are already ahead if you’ve worked with systems design, databases, and networking in school or on the job. You can then move on to supervised and unsupervised learning techniques.
Keep the momentum going by exploring more of our Sigma Computing articles: Table Groupings & Table Summary in Sigma Computing This But Not That Filtering in Sigma Computing DataModeling in Sigma Computing: What is the Difference Between Lookups vs. Joins? FAQs Can I use the same segmented control across multiple visuals?
Good data is the main factor in AI prediction. Overfitting: Overfitting is when the AI learns the training data too fast, with noise and outliers. That will make your data do bad on new unvisible data. Model training has to be proportionate so as not to fall into this bind.
You should have at least Contributor access to the workspace Download SQL Server Management Studio Step-by-Step Guide for Refreshing a Single Table in Power BI Semantic Model Using a demo datamodel, let’s walk through how to refresh a single table in a Power BI semantic model.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content