This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
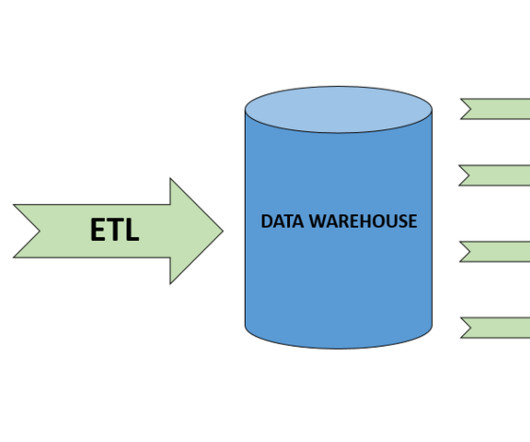
When it comes to data, there are two main types: datalakes and data warehouses. What is a datalake? An enormous amount of raw data is stored in its original format in a datalake until it is required for analytics applications. Which one is right for your business?
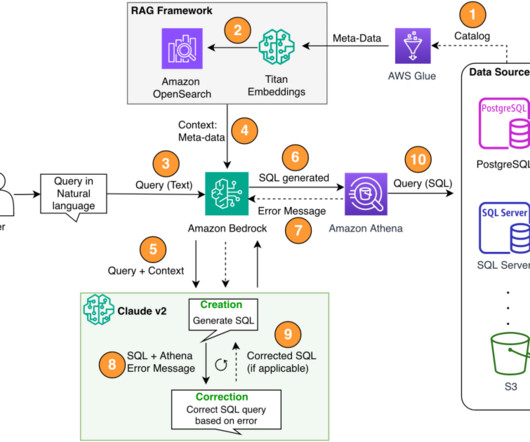
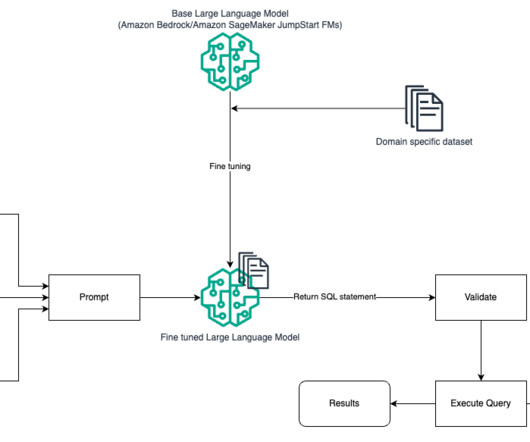
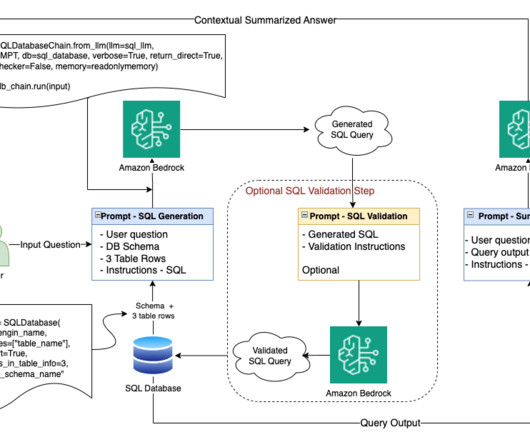
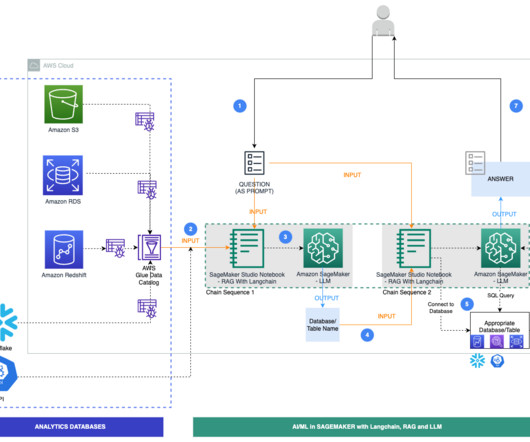
Managing and retrieving the right information can be complex, especially for data analysts working with large datalakes and complex SQL queries. This post highlights how Twilio enabled natural language-driven data exploration of business intelligence (BI) data with RAG and Amazon Bedrock.
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. Understanding DataLakes A datalake is a centralized repository that stores structured, semi-structured, and unstructured data in its raw format.
The following is an example of a financial information dataset for exchange-traded funds (ETFs) from Kaggle in a structured tabular format that we used to test our solution. NOTE : Since we used an SQL query engine to query the dataset for this demonstration, the prompts and generated outputs mention SQL below.
Writing data to an AWS datalake and retrieving it to populate an AWS RDS MS SQL database involves several AWS services and a sequence of steps for data transfer and transformation. This process leverages AWS S3 for the datalake storage, AWS Glue for ETL operations, and AWS Lambda for orchestration.
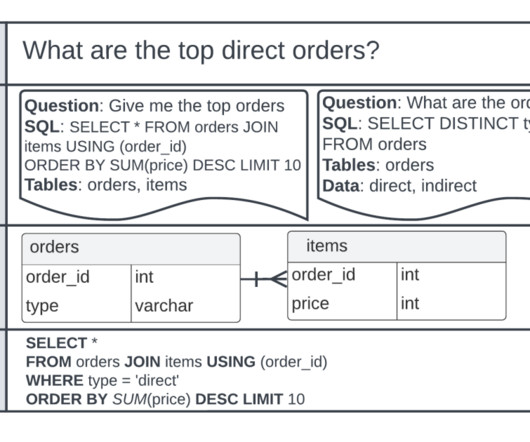
Our goal was to improve the user experience of an existing application used to explore the counters and insights data. The data is stored in a datalake and retrieved by SQL using Amazon Athena. The following figure shows a search query that was translated to SQL and run. The challenge is to assure quality.
Structured Query Language (SQL) is a complex language that requires an understanding of databases and metadata. Today, generative AI can enable people without SQL knowledge. This generative AI task is called text-to-SQL, which generates SQL queries from natural language processing (NLP) and converts text into semantically correct SQL.
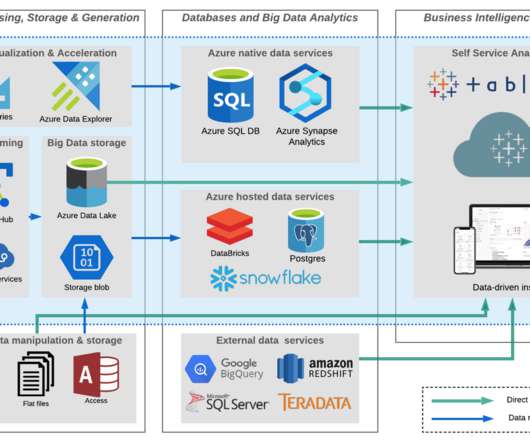
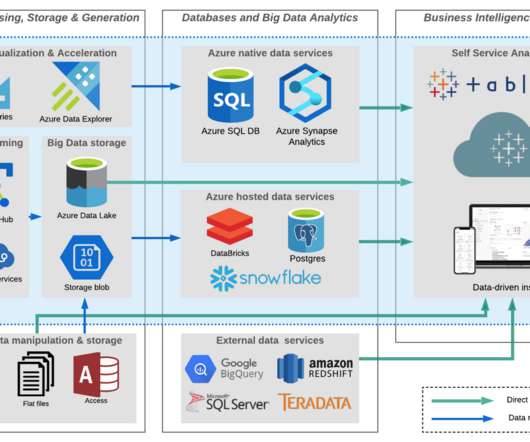
Unified data storage : Fabric’s centralized datalake, Microsoft OneLake, eliminates data silos and provides a unified storage system, simplifying data access and retrieval. OneLake is designed to store a single copy of data in a unified location, leveraging the open-source Apache Parquet format.
we’ve added new connectors to help our customers access more data in Azure than ever before: an Azure SQL Database connector and an Azure DataLake Storage Gen2 connector. As our customers increasingly adopt the cloud, we continue to make investments that ensure they can access their data anywhere. March 30, 2021.
Data is one of the most critical assets of many organizations. Theyre constantly seeking ways to use their vast amounts of information to gain competitive advantages. Amazon AppFlow was used to facilitate the smooth and secure transfer of data from various sources into ODAP.
With this full-fledged solution, you don’t have to spend all your time and effort combining different services or duplicating data. Overview of One Lake Fabric features a lake-centric architecture, with a central repository known as OneLake. Now, we can save the data as delta tables to use later for sales analytics.
Heres a sampling of what some of our more active users had to say about their experience with Field Advisor: I use Field Advisor to review executive briefing documents, summarize meetings and outline actions, as well analyze dense information into key points with prompts. Field Advisor continues to enable me to work smarter, not harder.
Discover the nuanced dissimilarities between DataLakes and Data Warehouses. Data management in the digital age has become a crucial aspect of businesses, and two prominent concepts in this realm are DataLakes and Data Warehouses. It acts as a repository for storing all the data.
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a DataLake? Consistency of data throughout the datalake.
One such area that is evolving is using natural language processing (NLP) to unlock new opportunities for accessing data through intuitive SQL queries. Instead of dealing with complex technical code, business users and data analysts can ask questions related to data and insights in plain language.
In this post, we discuss a Q&A bot use case that Q4 has implemented, the challenges that numerical and structured datasets presented, and how Q4 concluded that using SQL may be a viable solution. Providing incorrect or outdated information can impact investors’ and shareholders’ trust, in addition to other possible data privacy risks.
For many enterprises, a hybrid cloud datalake is no longer a trend, but becoming reality. Due to these needs, hybrid cloud datalakes emerged as a logical middle ground between the two consumption models. earthquake, flood, or fire), where the data collected does not need to be as tightly controlled.
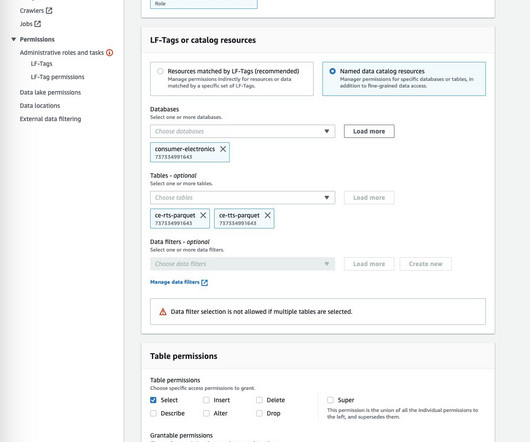
When defining your tagging strategy, you need to determine the right tags that will gather all the necessary information in your environment. Avoid personally identifiable information (PII) when labeling resources because tags remain unencrypted and visible. This identifies teams or cost centers responsible for those resources.
Data auditing and compliance Almost each company face data protection regulations such as GDPR, forcing them to store certain information in order to demonstrate compliance and history of data sources. In this scenario, data versioning can help companies in both internal and external audits process.
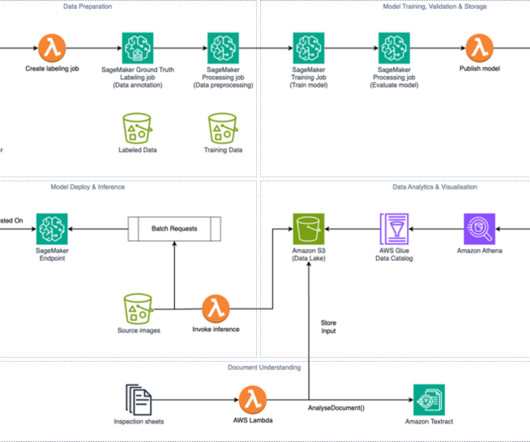
Amazon Simple Storage Service (Amazon S3) stores the model artifacts and creates a datalake to host the inference output, document analysis output, and other datasets in CSV format. The model is then trained using a fully managed infrastructure, validated, and published to the Amazon SageMaker Model Registry.
Every day, millions of riders use the Uber app, unwittingly contributing to a complex web of data-driven decisions. This blog takes you on a journey into the world of Uber’s analytics and the critical role that Presto, the open source SQL query engine, plays in driving their success. What is Presto?
we’ve added new connectors to help our customers access more data in Azure than ever before: an Azure SQL Database connector and an Azure DataLake Storage Gen2 connector. As our customers increasingly adopt the cloud, we continue to make investments that ensure they can access their data anywhere. March 30, 2021.
Why data warehousing is critical to a company’s success Data warehousing is the secure electronic information storage by a company or organization. A data lakehouse contains an organization’s data in a unstructured, structured, semi-structured form, which can be stored indefinitely for immediate or future use.
Many teams are turning to Athena to enable interactive querying and analyze their data in the respective data stores without creating multiple data copies. Athena allows applications to use standard SQL to query massive amounts of data on an S3 datalake. Create a datalake with Lake Formation.
blog series, we experiment with the most interesting blends of data and tools. Whether it’s mixing traditional sources with modern datalakes, open-source devops on the cloud with protected internal legacy tools, SQL with noSQL, web-wisdom-of-the-crowd with in-house handwritten notes, or IoT […].
The natural language capabilities allow non-technical users to query data through conversational English rather than complex SQL. The AI and language models must identify the appropriate data sources, generate effective SQL queries, and produce coherent responses with embedded results at scale.
You can streamline the process of feature engineering and data preparation with SageMaker Data Wrangler and finish each stage of the data preparation workflow (including data selection, purification, exploration, visualization, and processing at scale) within a single visual interface.
blog series, we experiment with the most interesting blends of data and tools. Whether it’s mixing traditional sources with modern datalakes, open-source DevOps on the cloud with protected internal legacy tools, SQL with noSQL, web-wisdom-of-the-crowd with in-house handwritten notes, or IoT […].
blog series, we experiment with the most interesting blends of data and tools. Whether it’s mixing traditional sources with modern datalakes, open-source DevOps on the cloud with protected internal legacy tools, SQL with NoSQL, web-wisdom-of-the-crowd with in-house handwritten notes, or IoT […].
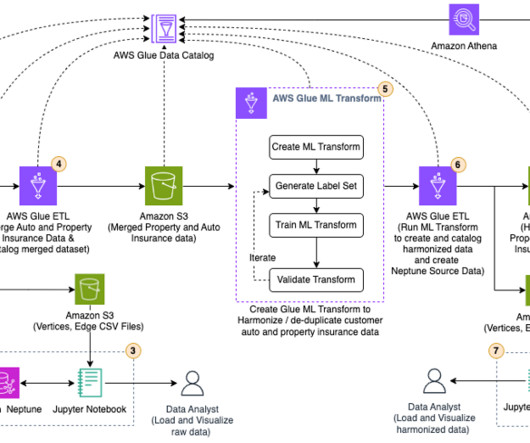
Thats why we use advanced technology and data analytics to streamline every step of the homeownership experience, from application to closing. Data exploration and model development were conducted using well-known machine learning (ML) tools such as Jupyter or Apache Zeppelin notebooks.
Summary: Big Data refers to the vast volumes of structured and unstructured data generated at high speed, requiring specialized tools for storage and processing. Data Science, on the other hand, uses scientific methods and algorithms to analyses this data, extract insights, and inform decisions.
Data Quality Now that you’ve learned more about your data and cleaned it up, it’s time to ensure the quality of your data is up to par. With these data exploration tools, you can determine if your data is accurate, consistent, and reliable.
By viewing data spatially, inferences can be made, and the imagination can be sparked. But in a world where so much data has a location, it’s essential to think spatially. From an ancient lake to a datalake: A paleo perspective. I’ve been getting my hands dirty with data for a long time now.
The General Data Protection Regulation (GDPR) right to be forgotten, also known as the right to erasure, gives individuals the right to request the deletion of their personally identifiable information (PII) data held by organizations. Example: customer information pertaining to the email address art@venere.org.
Amazon Redshift uses SQL to analyze structured and semi-structured data across data warehouses, operational databases, and datalakes, using AWS-designed hardware and ML to deliver the best price-performance at any scale. You can use query_string to filter your dataset by SQL and unload it to Amazon S3.
Computer Science and Computer Engineering Similar to knowing statistics and math, a data scientist should know the fundamentals of computer science as well. While knowing Python, R, and SQL are expected, you’ll need to go beyond that. Big Data As datasets become larger and more complex, knowing how to work with them will be key.
Introduction to Big Data Tools In todays data-driven world, organisations are inundated with vast amounts of information generated from various sources, including social media, IoT devices, transactions, and more. Big Data tools are essential for effectively managing and analysing this wealth of information.
Optimized for analytical processing, it uses specialized data models to enhance query performance and is often integrated with business intelligence tools, allowing users to create reports and visualizations that inform organizational strategies. Its PostgreSQL foundation ensures compatibility with most SQL clients.
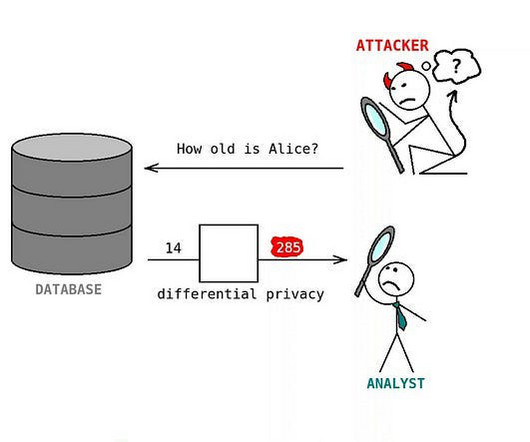
How you now anonymize Data more easily Photo by Dušan veverkolog on Unsplash Google has just announced the public preview of BigQuery differential privacy with SQL building blocks. You can use these functions to anonymize their data. Hence, with this feature you can also ensure that data is shared there securely.
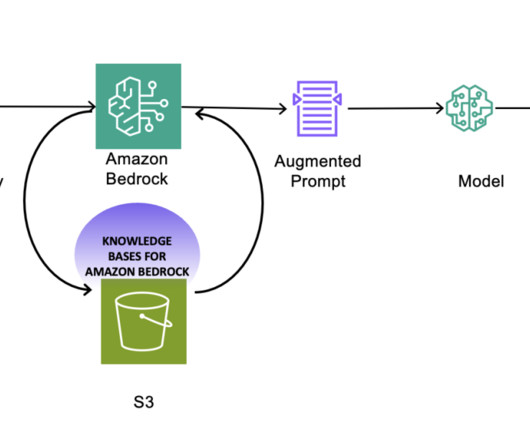
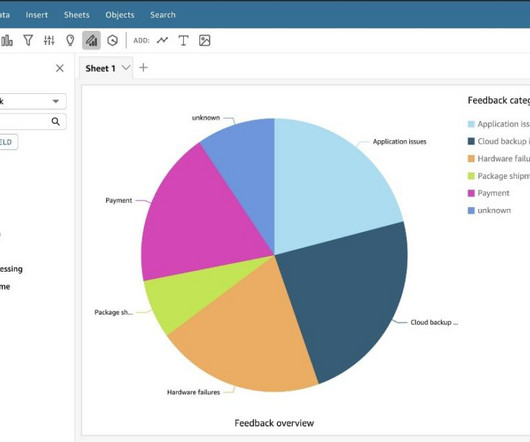
In addition, the generative business intelligence (BI) capabilities of QuickSight allow you to ask questions about customer feedback using natural language, without the need to write SQL queries or learn a BI tool. For more information, see Customize models in Amazon Bedrock with your own data using fine-tuning and continued pre-training.
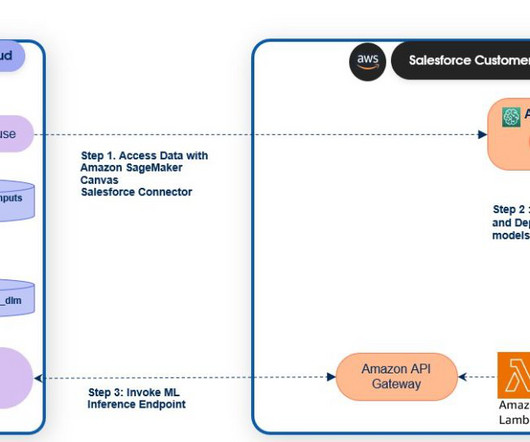
Configure the following scopes on your connected app: Manage user data via APIs ( api ). Perform ANSI SQL queries on Salesforce Data Cloud data (Data Cloud_query_api ). Manage Data Cloud profile data ( Data Cloud_profile_api ). Drag and drop the file, then choose Edit in SQL.
Companies are faced with the daunting task of ingesting all this data, cleansing it, and using it to provide outstanding customer experience. Typically, companies ingest data from multiple sources into their datalake to derive valuable insights from the data.
In another decade, the internet and mobile started the generate data of unforeseen volume, variety and velocity. It required a different data platform solution. Hence, DataLake emerged, which handles unstructured and structured data with huge volume. All phases of the data-information lifecycle.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.



































Let's personalize your content