
Data Lakes and SQL: A Match Made in Data Heaven
KDnuggets
JANUARY 16, 2023
In this article, we will discuss the benefits of using SQL with a data lake and how it can help organizations unlock the full potential of their data.

KDnuggets
JANUARY 16, 2023
In this article, we will discuss the benefits of using SQL with a data lake and how it can help organizations unlock the full potential of their data.
KDnuggets
JUNE 27, 2022
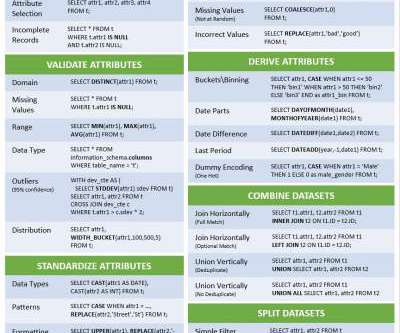
If your raw data is in a SQL-based data lake, why spend the time and money to export the data into a new platform for data prep?
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Dataversity
MARCH 26, 2024
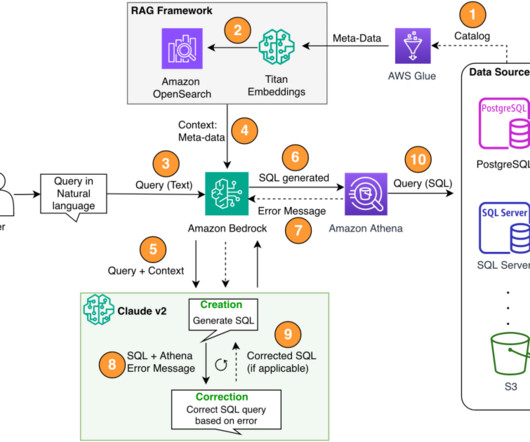
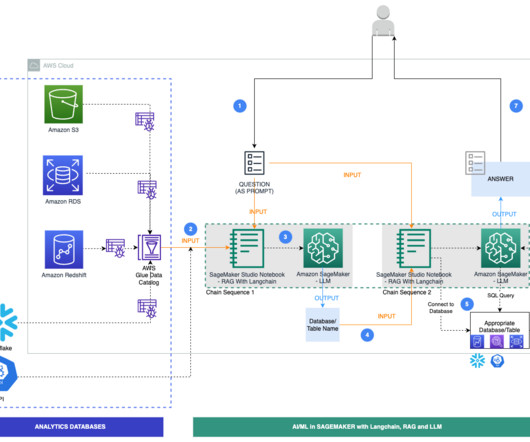
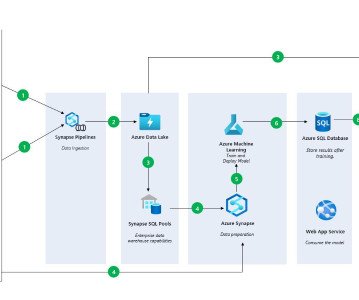
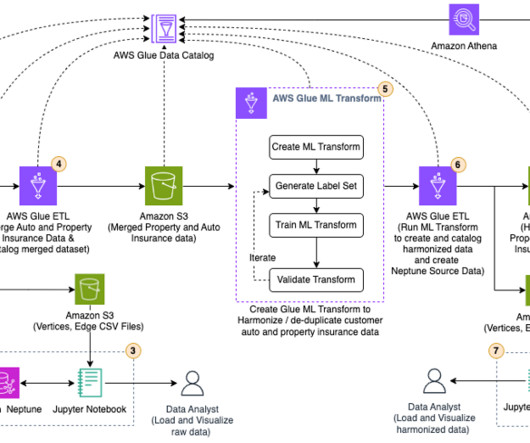
Writing data to an AWS data lake and retrieving it to populate an AWS RDS MS SQL database involves several AWS services and a sequence of steps for data transfer and transformation. This process leverages AWS S3 for the data lake storage, AWS Glue for ETL operations, and AWS Lambda for orchestration.

Hacker News
MARCH 28, 2024
A unified SQL query interface and portable runtime to locally materialize, accelerate, and query data tables sourced from any database, data warehouse, or data lake. spiceai/spiceai

KDnuggets
JANUARY 18, 2023
7 Best Platforms to Practice SQL • Explainable AI: 10 Python Libraries for Demystifying Your Model's Decisions • ChatGPT: Everything You Need to Know • Data Lakes and SQL: A Match Made in Data Heaven • Google Data Analytics Certification Review for 2023

ODSC - Open Data Science
SEPTEMBER 27, 2023
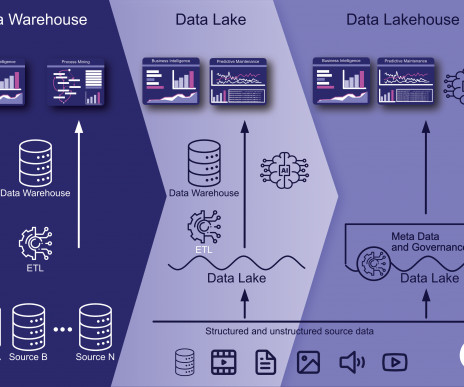
In the ever-evolving world of big data, managing vast amounts of information efficiently has become a critical challenge for businesses across the globe. As data lakes gain prominence as a preferred solution for storing and processing enormous datasets, the need for effective data version control mechanisms becomes increasingly evident.

phData
SEPTEMBER 19, 2023
With the amount of data companies are using growing to unprecedented levels, organizations are grappling with the challenge of efficiently managing and deriving insights from these vast volumes of structured and unstructured data. What is a Data Lake? Consistency of data throughout the data lake.

Expert insights. Personalized for you.




























Let's personalize your content