
Data Preparation with SQL Cheatsheet
KDnuggets
JUNE 27, 2022
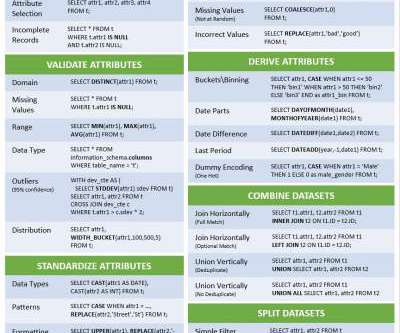
If your raw data is in a SQL-based data lake, why spend the time and money to export the data into a new platform for data prep?
KDnuggets
JUNE 27, 2022
If your raw data is in a SQL-based data lake, why spend the time and money to export the data into a new platform for data prep?

Data Science Dojo
JANUARY 12, 2023
When it comes to data, there are two main types: data lakes and data warehouses. What is a data lake? An enormous amount of raw data is stored in its original format in a data lake until it is required for analytics applications. Which one is right for your business?
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

ODSC - Open Data Science
JUNE 12, 2023
Power BI Datamarts provide no-code/low-code datamart capabilities using Azure SQL Database technology in the background. The Power BI Datamarts support sensitivity labels, endorsement, discovery, and Row-Level Security ( RLS ), which help protect and manage the data according to the business requirements and compliance needs.
phData
SEPTEMBER 28, 2023
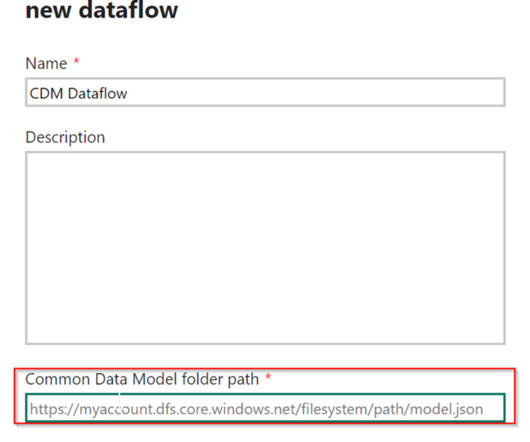
Dataflows represent a cloud-based technology designed for data preparation and transformation purposes. Dataflows have different connectors to retrieve data, including databases, Excel files, APIs, and other similar sources, along with data manipulations that are performed using Online Power Query Editor.

Pickl AI
AUGUST 1, 2023
Key Components of Data Engineering Data Ingestion : Gathering data from various sources, such as databases, APIs, files, and streaming platforms, and bringing it into the data infrastructure. Data Processing: Performing computations, aggregations, and other data operations to generate valuable insights from the data.
AWS Machine Learning Blog
AUGUST 4, 2023
Train a recommendation model in SageMaker Studio using training data that was prepared using SageMaker Data Wrangler. The real-time inference call data is first passed to the SageMaker Data Wrangler container in the inference pipeline, where it is preprocessed and passed to the trained model for product recommendation.

Snorkel AI
MAY 26, 2023
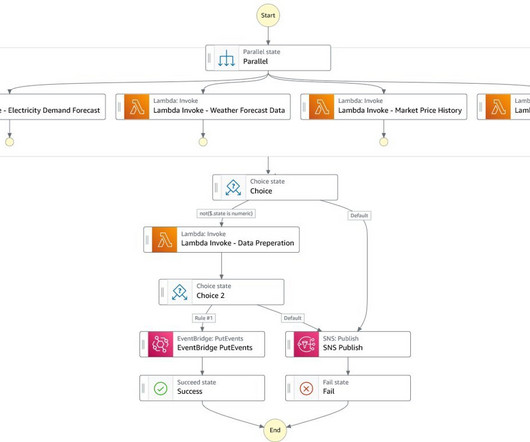
[link] Ahmad Khan, head of artificial intelligence and machine learning strategy at Snowflake gave a presentation entitled “Scalable SQL + Python ML Pipelines in the Cloud” about his company’s Snowpark service at Snorkel AI’s Future of Data-Centric AI virtual conference in August 2022. Welcome everybody.

Expert insights. Personalized for you.














Let's personalize your content