This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Using Azure ML to Train a Serengeti DataModel, Fast Option Pricing with DL, and How To Connect a GPU to a Container Using Azure ML to Train a Serengeti DataModel for Animal Identification In this article, we will cover how you can train a model using Notebooks in Azure Machine Learning Studio.
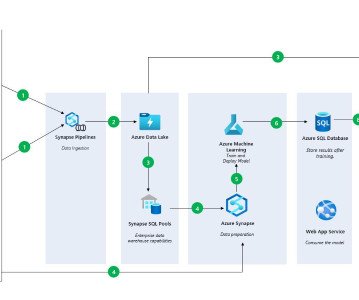
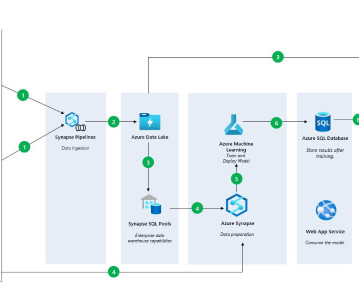
To get the data, you will need to follow the instructions in the article: Create a Data Solution on Azure Synapse Analytics with Snapshot Serengeti — Part 1 — Microsoft Community Hub, where you will load data into Azure DataLake via Azure Synapse. Lastly, upload the data from Azure Subscription.
We first highlight how we use AWS Glue for highly parallel data processing. We then discuss how Amazon SageMaker helps us with feature engineering and building a scalable supervised deeplearningmodel. Dan Volk is a Data Scientist at the AWS Generative AI Innovation Center. Kexin Ding is a fifth-year Ph.D.
This blog highlights some of the most impactful AI slides from the world’s best data science instructors, focusing on cutting-edge advancements in AI, datamodeling, and deployment strategies. Here’s a breakdown of ten top sessions from this year’s conference that data professionals should consider.
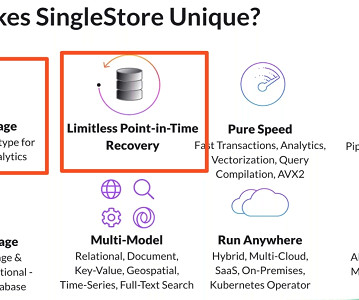
Real-time Analytics & Built-in Machine LearningModels with a Single Database Akmal Chaudhri, Senior Technical Evangelist at SingleStore, explores the importance of delivering real-time experiences in today’s big data industry and how datamodels and algorithms rely on powerful and versatile data infrastructure.
Model versioning, lineage, and packaging : Can you version and reproduce models and experiments? Can you see the complete model lineage with data/models/experiments used downstream? LakeFS LakeFS is an open-source platform that provides datalake versioning and management capabilities.
Reinforcement Learning with Human Feedback Luis Serrano, PhD | Author of Grokking Machine Learning and Creator of Serrano Academy In this session, you’ll explore the widely used LLM fine-tuning method of Reinforcement Learning with Human Feedback (RLHF).
Not only is data larger, but models—deeplearningmodels in particular—are much larger than before. We need robust versioning for data, models, code, and preferably even the internal state of applications—think Git on steroids to answer inevitable questions: What changed? Compute.
In this article, we’ll explore how AI can transform unstructured data into actionable intelligence, empowering you to make informed decisions, enhance customer experiences, and stay ahead of the competition. What is Unstructured Data? These processes are essential in AI-based big data analytics and decision-making.
To combine the collected data, you can integrate different data producers into a datalake as a repository. A central repository for unstructured data is beneficial for tasks like analytics and data virtualization. Data Cleaning The next step is to clean the data after ingesting it into the datalake.
In LnW Connect, an encryption process was designed to provide a secure and reliable mechanism for the data to be brought into an AWS datalake for predictive modeling. Our model surpassed the AutoGluon baseline model by 121% in recall at 80% precision.
By using the flexible document datamodel of MongoDB Atlas, organizations can represent and query complex knowledge entities and their relationships within Amazon Bedrock. She assists customers by architecting enterprise datalake and ML solutions to scale their data analytics in the cloud. Satish Sarapuri is a Sr.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















Let's personalize your content