This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Datagovernance challenges Maintaining consistent datagovernance across different systems is crucial but complex. When needed, the system can access an ODAP data warehouse to retrieve additional information. Xinyi Zhou is a Data Engineer at Omron Europe, bringing her expertise to the ODAP team led by Emrah Kaya.
This past week, I had the pleasure of hosting DataGovernance for Dummies author Jonathan Reichental for a fireside chat , along with Denise Swanson , DataGovernance lead at Alation. Can you have proper data management without establishing a formal datagovernance program?
The financial services industry has been in the process of modernizing its datagovernance for more than a decade. But as we inch closer to global economic downturn, the need for top-notch governance has become increasingly urgent. That’s why datapipeline observability is so important.
It is the practice of monitoring, tracking, and ensuring data quality, reliability, and performance as it moves through an organization’s datapipelines and systems. Data quality tools help maintain high data quality standards. Tools Used in Data Observability?
Securing AI models and their access to data While AI models need flexibility to access data across a hybrid infrastructure, they also need safeguarding from tampering (unintentional or otherwise) and, especially, protected access to data. And that makes sense. This allows for a high degree of transparency and auditability.
User support arrangements Consider the availability and quality of support from the provider or vendor, including documentation, tutorials, forums, customer service, etc. Kubeflow integrates with popular ML frameworks, supports versioning and collaboration, and simplifies the deployment and management of ML pipelines on Kubernetes clusters.
In today’s fast-paced business environment, the significance of Data Observability cannot be overstated. Data Observability enables organizations to detect anomalies, troubleshoot issues, and maintain datapipelines effectively. This involves creating data dictionaries, documentation, and metadata.
Connecting directly to this semantic layer will help give customers access to critical business data in a safe, governed manner. This partnership makes data more accessible and trusted. Our continued investments in connectivity with Google technologies help ensure your data is secure, governed, and scalable.
This section outlines key practices focused on automation, monitoring and optimisation, scalability, documentation, and governance. Automation Automation plays a pivotal role in streamlining ETL processes, reducing the need for manual intervention, and ensuring consistent data availability.
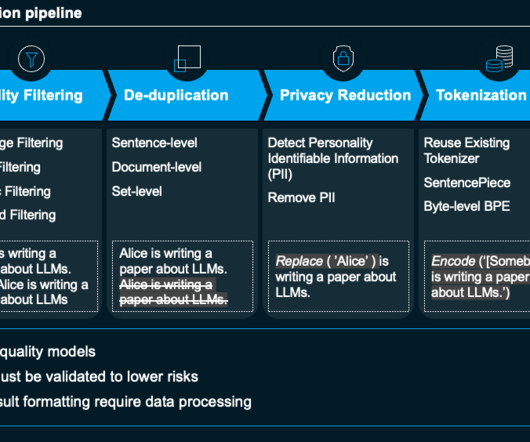
The groundwork of training data in an AI model is comparable to piloting an airplane. The entire generative AI pipeline hinges on the datapipelines that empower it, making it imperative to take the correct precautions. This may also entail working with new data through methods like web scraping or uploading.
Semantics, context, and how data is tracked and used mean even more as you stretch to reach post-migration goals. This is why, when data moves, it’s imperative for organizations to prioritize data discovery. Data discovery is also critical for datagovernance , which, when ineffective, can actually hinder organizational growth.
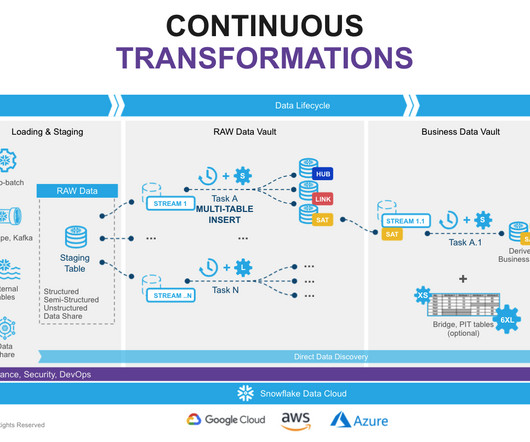
In data vault implementations, critical components encompass the storage layer, ELT technology, integration platforms, data observability tools, Business Intelligence and Analytics tools, DataGovernance , and Metadata Management solutions. The most important reason for using DBT in Data Vault 2.0
This, in turn, helps them to build new datapipelines, solutions, and products, or clean up the data that’s there. It bears mentioning data profiling has evolved tremendously. In summary, data profiling is a critical component of a comprehensive datagovernance strategy.
Data as the foundation of what the business does is great – but how do you support that? What technology or platform can meet the needs of the business, from basic report creation to complex document analysis to machine learning workflows? The Snowflake AI Data Cloud is the platform that will support that and much more!
Connecting directly to this semantic layer will help give customers access to critical business data in a safe, governed manner. This partnership makes data more accessible and trusted. Our continued investments in connectivity with Google technologies help ensure your data is secure, governed, and scalable. .
Snowflake AI Data Cloud is one of the most powerful platforms, including storage services supporting complex data. Integrating Snowflake with dbt adds another layer of automation and control to the datapipeline. Snowflake stored procedures and dbt Hooks are essential to modern data engineering and analytics workflows.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
Unconstrained, long, open-ended generation that may expose harmful or biased content to users, like legal document creation. The required architecture includes a datapipeline, ML pipeline, application pipeline and a multi-stage pipeline. Let’s dive into the data management pipeline.
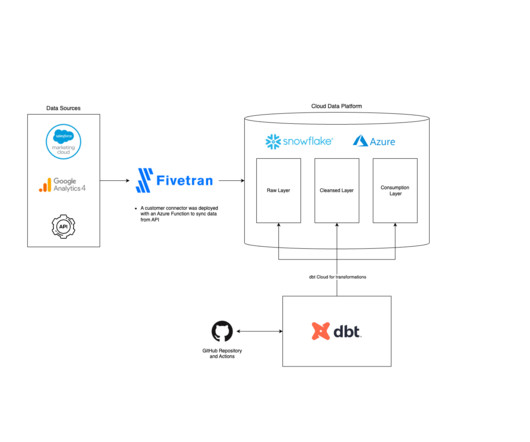
To optimize the use of Fivetran connectors within your finance organization, consider the following insights and best practices: DataGovernance: Implement policies to safeguard sensitive financial information and ensure it complies with industry regulations.
However, in scenarios where dataset versioning solutions are leveraged, there can still be various challenges experienced by ML/AI/Data teams. Data aggregation: Data sources could increase as more data points are required to train ML models. Existing datapipelines will have to be modified to accommodate new data sources.
Understanding Fivetran Fivetran is a popular Software-as-a-Service platform that enables users to automate the movement of data and ETL processes across diverse sources to a target destination. The phData team achieved a major milestone by successfully setting up a secure end-to-end datapipeline for a substantial healthcare enterprise.
It’s common to have terabytes of data in most data warehouses, data quality monitoring is often challenging and cost-intensive due to dependencies on multiple tools and eventually ignored. This results in poor credibility and data consistency after some time, leading businesses to mistrust the datapipelines and processes.
We already know that a data quality framework is basically a set of processes for validating, cleaning, transforming, and monitoring data. DataGovernanceDatagovernance is the foundation of any data quality framework. It primarily caters to large organizations with complex data environments.
Support for Advanced Analytics : Transformed data is ready for use in Advanced Analytics, Machine Learning, and Business Intelligence applications, driving better decision-making. Compliance and Governance : Many tools have built-in features that ensure data adheres to regulatory requirements, maintaining datagovernance across organisations.
Both co-located summits, Generative AI X and Data Engineering will run on Wednesday, offering attendees a chance to delve into specialized topics. At the Data Engineering Summit, experts will cover datapipelines, real-time processing, and best practices for scalable data infrastructures.
Image generated with Midjourney In today’s fast-paced world of data science, building impactful machine learning models relies on much more than selecting the best algorithm for the job. Data scientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust datapipelines.
Business Analyst Though in many respects, quite similar to data analysts, you’ll find that business analysts most often work with a greater focus on industries such as finance, marketing, retail, and consulting. The main aspect of their profession is the building and maintenance of datapipelines, which allow for data to move between sources.
Uniform Language Ensure consistency in language across datasets, especially when data is collected from multiple sources. Document Changes Keep a record of all changes made during the cleaning process for transparency and reproducibility, which is essential for future analyses. To achieve this, a comprehensive approach is essential.
Transformation tools of old often lacked easy orchestration, were difficult to test/verify, required specialized knowledge of the tool, and the documentation of your transformations dependent on the willingness of the developer to document. Even things like data access reviews are typically done manually without automation.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, data lakes , data sharing, and engineering. Data Security and Governance Maintaining data security is crucial for any company.
Programming Languages: Proficiency in programming languages like Python or R is advantageous for performing advanced data analytics, implementing statistical models, and building datapipelines. BI Developers should be familiar with relational databases, data warehousing, datagovernance, and performance optimization techniques.
Datagovernance: Ensure that the data used to train and test the model, as well as any new data used for prediction, is properly governed. For small-scale/low-value deployments, there might not be many items to focus on, but as the scale and reach of deployment go up, datagovernance becomes crucial.
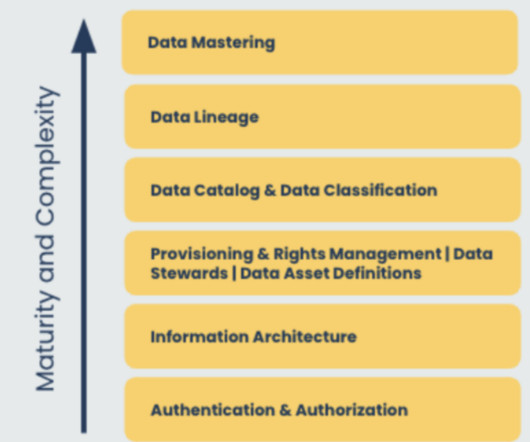
Data literacy — Employees can interpret and analyze data to draw logical conclusions; they can also identify subject matter experts best equipped to educate on specific data assets. Datagovernance is a key use case of the modern data stack. Who Can Adopt the Modern Data Stack?
As Alation worked to create a new category of enterprise data management tool, the data catalog , Aaron wanted to also use this new technology to advance the cause of academic research. Aaron turned his attention from Alation Open to launch the Alation Data Catalog. He even had a name for it: Alation Open.
Datapipeline orchestration tools are designed to automate and manage the execution of datapipelines. These tools help streamline and schedule data movement and processing tasks, ensuring efficient and reliable data flow. What are Orchestration Tools?
In fact, only 59% of organizations trust their AI/ML model inputs and outputs , according to the latest BARC Data Observability Survey: Observability for AI Innovation. If youre a data leader grappling with trust, transparency, and governance in AI datapipelines, youre not alone.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





































Let's personalize your content