This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Establishing the foundation for scalable datapipelines Initiating the process of creating scalable datapipelines requires addressing common challenges such as data fragmentation, inconsistent quality and siloed team operations.
Where exactly within an organization does the primary responsibility lie for ensuring that a datapipeline project generates data of high quality, and who exactly holds that responsibility? Who is accountable for ensuring that the data is accurate? Is it the data engineers? The datascientists?
The financial services industry has been in the process of modernizing its datagovernance for more than a decade. But as we inch closer to global economic downturn, the need for top-notch governance has become increasingly urgent. That’s why datapipeline observability is so important.
This will become more important as the volume of this data grows in scale. DataGovernanceDatagovernance is the process of managing data to ensure its quality, accuracy, and security. Datagovernance is becoming increasingly important as organizations become more reliant on data.
Some popular end-to-end MLOps platforms in 2023 Amazon SageMaker Amazon SageMaker provides a unified interface for data preprocessing, model training, and experimentation, allowing datascientists to collaborate and share code easily. Check out the Kubeflow documentation.
Connecting AI models to a myriad of data sources across cloud and on-premises environments AI models rely on vast amounts of data for training. Once trained and deployed, models also need reliable access to historical and real-time data to generate content, make recommendations, detect errors, send proactive alerts, etc.
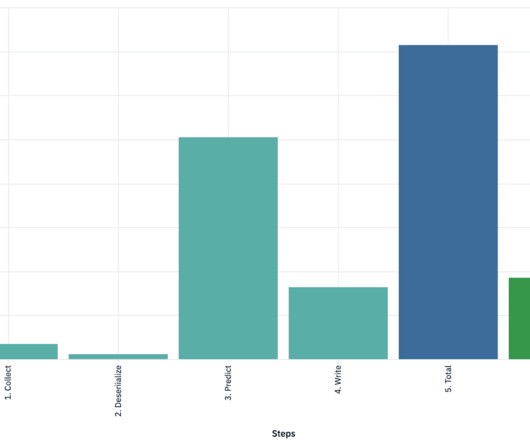
All data generation and processing steps were run in parallel directly on the SageMaker HyperPod cluster nodes, using a unique working environment and highlighting the clusters versatility for various tasks beyond just training models. She specializes in AI operations, datagovernance, and cloud architecture on AWS.
They are responsible for designing, building, and maintaining the infrastructure and tools needed to manage and process large volumes of data effectively. This involves working closely with data analysts and datascientists to ensure that data is stored, processed, and analyzed efficiently to derive insights that inform decision-making.
Unfolding the difference between data engineer, datascientist, and data analyst. Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. Role of DataScientistsDataScientists are the architects of data analysis.
A potential option is to use an ELT system — extract, load, and transform — to interact with the data on an as-needed basis. It may conflict with your datagovernance policy (more on that below), but it may be valuable in establishing a broader view of the data and directing you toward better data sets for your main models.
Key components include data modelling, warehousing, pipelines, and integration. Effective datagovernance enhances quality and security throughout the data lifecycle. What is Data Engineering? They are crucial in ensuring data is readily available for analysis and reporting. from 2025 to 2030.
The audience grew to include datascientists (who were even more scarce and expensive) and their supporting resources (e.g., After that came datagovernance , privacy, and compliance staff. Power business users and other non-purely-analytic data citizens came after that. datapipelines) to support.
What is Data Observability? It is the practice of monitoring, tracking, and ensuring data quality, reliability, and performance as it moves through an organization’s datapipelines and systems. Data quality tools help maintain high data quality standards. Tools Used in Data Observability?
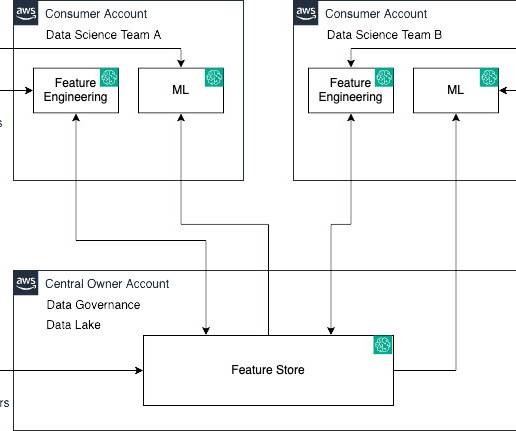
Let’s demystify this using the following personas and a real-world analogy: Data and ML engineers (owners and producers) – They lay the groundwork by feeding data into the feature store Datascientists (consumers) – They extract and utilize this data to craft their models Data engineers serve as architects sketching the initial blueprint.
Data domain teams have a better understanding of the data and their unique use cases, making them better positioned to enhance the value of their data and make it available for data teams. With this approach, demands on each team are more manageable, and analysts can quickly get the data they need.
The data tells a compelling storyone that every datascientist, IT lead, and executive stakeholder should pay attention to. Itneeds: Scalable cloud infrastructure Clean, structured datapipelines Skilled professionals who can fine-tune and monitormodels Cutting corners leads to short-term projects that fizzle out.
It helps companies streamline and automate the end-to-end ML lifecycle, which includes data collection, model creation (built on data sources from the software development lifecycle), model deployment, model orchestration, health monitoring and datagovernance processes.
Data engineering is a rapidly growing field, and there is a high demand for skilled data engineers. If you are a datascientist, you may be wondering if you can transition into data engineering. The good news is that there are many skills that datascientists already have that are transferable to data engineering.
Do we have end-to-end datapipeline control? What can we learn about our data quality issues? How can we improve and deliver trusted data to the organization? One major obstacle presented to data quality is data silos , as they obstruct transparency and make collaboration tough. Unified Teams.
Datagovernance Apply fine-grained access control to data managed by the system, including training data, vector stores, evaluation data, prompt templates, workflow, and agent definitions. Bharathi Srinivasan is a Generative AI DataScientist at the AWS Worldwide Specialist Organization.
Semantics, context, and how data is tracked and used mean even more as you stretch to reach post-migration goals. This is why, when data moves, it’s imperative for organizations to prioritize data discovery. Data discovery is also critical for datagovernance , which, when ineffective, can actually hinder organizational growth.
It brings together business users, datascientists , data analysts, IT, and application developers to fulfill the business need for insights. DataOps then works to continuously improve and adjust data models, visualizations, reports, and dashboards to achieve business goals. Using DataOps to Empower Users.
This integration empowers all data consumers, from business users, to stewards, analysts, and datascientists, to access trustworthy and reliable data. These users can also gain visibility into the health of the data in real-time. Alation’s Data Catalog: Built-in Data Quality Capabilities.
When done well, data democratization empowers employees with tools that let everyone work with data, not just the datascientists. When workers get their hands on the right data, it not only gives them what they need to solve problems, but also prompts them to ask, “What else can I do with data?
And because data assets within the catalog have quality scores and social recommendations, Alex has greater trust and confidence in the data she’s using for her decision-making recommendations. This is especially helpful when handling massive amounts of big data. Protected and compliant data.
Insurance companies often face challenges with data silos and inconsistencies among their legacy systems. To address these issues, they need a centralized and integrated data platform that serves as a single source of truth, preferably with strong datagovernance capabilities.
Snowpark , an innovative technology from the Snowflake Data Cloud , promises to meet this demand by allowing datascientists to develop complex data transformation logic using familiar programming languages such as Java, Scala, and Python.
This is the practice of creating, updating and consistently enforcing the processes, rules and standards that prevent errors, data loss, data corruption, mishandling of sensitive or regulated data, and data breaches. Learn more about designing the right data architecture to elevate your data quality here.
A broken datapipeline might bring operational systems to a halt, or it could cause executive dashboards to fail, reporting inaccurate KPIs to top management. Is your datagovernance structure up to the task? Read What Is Data Observability? Complexity leads to risk.
To answer these questions we need to look at how data roles within the job market have evolved, and how academic programs have changed to meet new workforce demands. In the 2010s, the growing scope of the data landscape gave rise to a new profession: the datascientist. The datascientist.
This May, were heading to Boston for ODSC East 2025, where datascientists, AI engineers, and industry leaders will gather to explore the latest advancements in AI, machine learning, and data engineering. The wait is almost over! Dont miss out register today and take advantage of early-bird pricing to save on yourpass!
Additionally, Snowflake Cortex integrates seamlessly with Snowflake’s core platform, ensuring that all AI and machine learning processes benefit from Snowflake’s scalability, security, and datagovernance features. What is Snowpark? At phData, we’ve seen tremendous performance benefits of running ML workloads in Snowpark.
Though just about every industry imaginable utilizes the skills of a data-focused professional, each has its own challenges, needs, and desired outcomes. This is why you’ll often find that there are jobs in AI specific to an industry, or desired outcome when it comes to data.
Data quality is crucial across various domains within an organization. For example, software engineers focus on operational accuracy and efficiency, while datascientists require clean data for training machine learning models. Without high-quality data, even the most advanced models can't deliver value.
Key Players in AI Development Enterprises increasingly rely on AI to automate and enhance their data engineering workflows, making data more ready for building, training, and deploying AI applications. Let’s dive deeper into data readiness next. This involves various professionals.
Image generated with Midjourney In today’s fast-paced world of data science, building impactful machine learning models relies on much more than selecting the best algorithm for the job. Datascientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust datapipelines.
Snowflake enables organizations to instantaneously scale to meet SLAs with timely delivery of regulatory obligations like SEC Filings, MiFID II, Dodd-Frank, FRTB, or Basel III—all with a single copy of data enabled by data sharing capabilities across various internal departments.
Powered by cloud computing, more data professionals have access to the data, too. Data analysts have access to the data warehouse using BI tools like Tableau; datascientists have access to data science tools, such as Dataiku. Better Data Culture. Who Can Adopt the Modern Data Stack?
My name is Erin Babinski and I’m a datascientist at Capital One, and I’m speaking today with my colleagues Bayan and Kishore. We’re here to talk to you all about data-centric AI. billion is lost by Fortune 500 companies because of broken datapipelines and communications.
My name is Erin Babinski and I’m a datascientist at Capital One, and I’m speaking today with my colleagues Bayan and Kishore. We’re here to talk to you all about data-centric AI. billion is lost by Fortune 500 companies because of broken datapipelines and communications.
Collaboration : Ensuring that all teams involved in the project, including datascientists, engineers, and operations teams, are working together effectively. Datagovernance: Ensure that the data used to train and test the model, as well as any new data used for prediction, is properly governed.
However, in scenarios where dataset versioning solutions are leveraged, there can still be various challenges experienced by ML/AI/Data teams. Data aggregation: Data sources could increase as more data points are required to train ML models. Existing datapipelines will have to be modified to accommodate new data sources.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, data lakes , data sharing, and engineering. Data Security and Governance Maintaining data security is crucial for any company.
Better Transparency: There’s more clarity about where data is coming from, where it’s going, why it’s being transformed, and how it’s being used. Improved DataGovernance: This level of transparency can also enhance datagovernance and control mechanisms in the new data system.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.















































Let's personalize your content