This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
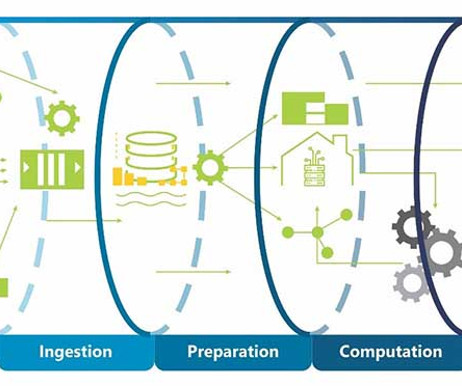
Datapipelines are essential in our increasingly data-driven world, enabling organizations to automate the flow of information from diverse sources to analytical platforms. What are datapipelines? Purpose of a datapipelineDatapipelines serve various essential functions within an organization.
In today’s data-driven world, extracting, transforming, and loading (ETL) data is crucial for gaining valuable insights. While many ETL tools exist, dbt (data build tool) is emerging as a game-changer.
Datapipelines automatically fetch information from various disparate sources for further consolidation and transformation into high-performing data storage. There are a number of challenges in data storage , which datapipelines can help address. Choosing the right datapipeline solution.
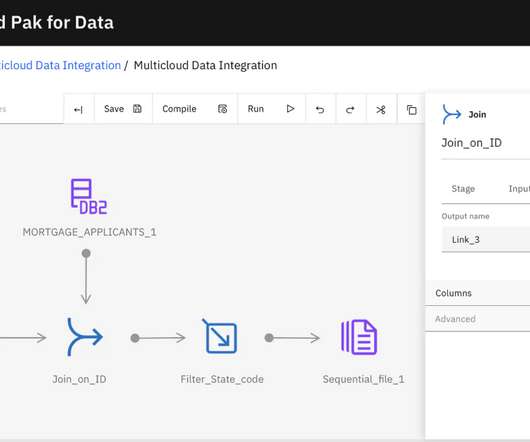
One of the key elements that builds a data fabric architecture is to weave integrated data from many different sources, transform and enrich data, and deliver it to downstream data consumers. This leaves more time for dataanalysis. Let’s use address data as an example.
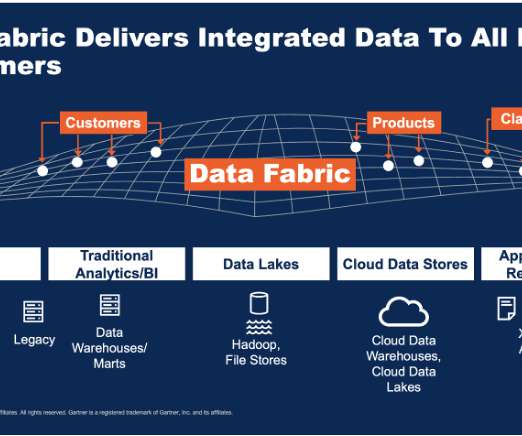
Implementing a data fabric architecture is the answer. What is a data fabric? Data fabric is defined by IBM as “an architecture that facilitates the end-to-end integration of various datapipelines and cloud environments through the use of intelligent and automated systems.” This leaves more time for dataanalysis.
Spark is a general-purpose distributed data processing engine that can handle large volumes of data for applications like dataanalysis, fraud detection, and machine learning. we have Databricks which is an open-source, next-generation data management platform. It has built-in support for machine learning.
These procedures are central to effective data management and crucial for deploying machine learning models and making data-driven decisions. The success of any data initiative hinges on the robustness and flexibility of its big datapipeline. What is a DataPipeline?
To solve this problem, we had to design a strong datapipeline to create the ML features from the raw data and MLOps. Multiple data sources ODIN is an MMORPG where the game players interact with each other, and there are various events such as level-up, item purchase, and gold (game money) hunting.
Data engineers are essential professionals responsible for designing, constructing, and maintaining an organization’s data infrastructure. They create datapipelines, ETL processes, and databases to facilitate smooth data flow and storage. Read more to know.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. ETL is vital for ensuring data quality and integrity.
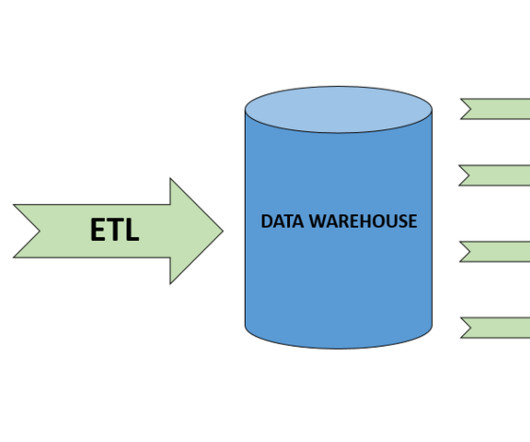
A data warehouse enables advanced analytics, reporting, and business intelligence. The data warehouse emerged as a means of resolving inefficiencies related to data management, dataanalysis, and an inability to access and analyze large volumes of data quickly.
Here’s a list of key skills that are typically covered in a good data science bootcamp: Programming Languages : Python : Widely used for its simplicity and extensive libraries for dataanalysis and machine learning. R : Often used for statistical analysis and data visualization.
This individual is responsible for building and maintaining the infrastructure that stores and processes data; the kinds of data can be diverse, but most commonly it will be structured and unstructured data. They’ll also work with software engineers to ensure that the data infrastructure is scalable and reliable.
Evaluate integration capabilities with existing data sources and Extract Transform and Load (ETL) tools. Security features include data encryption and access control. Weakness: Complex pricing model, limited control over performance, latency for small data, limited data transformation features.
For those unfamiliar with GIT or GIT practices, please refer Git for Business Users with Matillion DPC What is a Matillion Pipeline? A Matillion pipeline is a collection of jobs that extract, load, and transform (ETL/ELT) data from various sources into a target system, such as a cloud data warehouse like Snowflake.
Data engineers play a crucial role in managing and processing big data Ensuring data quality and integrity Data quality and integrity are essential for accurate dataanalysis. Data engineers are responsible for ensuring that the data collected is accurate, consistent, and reliable.
Here are steps you can follow to pursue a career as a BI Developer: Acquire a solid foundation in data and analytics: Start by building a strong understanding of data concepts, relational databases, SQL (Structured Query Language), and data modeling.
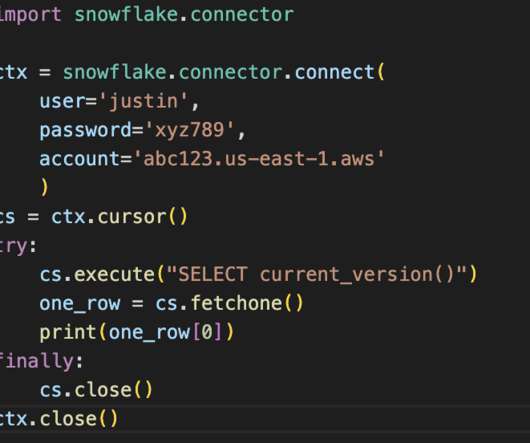
Connecting Snowflake to Python can be a game changer for your data services. Python can be used to migrate your data from a previous platform to Snowflake , create or manage datapipelines for Extract, Transform, and Load (ETL) processes, perform data science tasks such as machine learning or create dataanalysis visualizations.
It integrates well with cloud services, databases, and big data platforms like Hadoop, making it suitable for various data environments. Typical use cases include ETL (Extract, Transform, Load) tasks, data quality enhancement, and data governance across various industries.
Find out how to weave data reliability and quality checks into the execution of your datapipelines and more. More Speakers and Sessions Announced for the 2024 Data Engineering Summit Ranging from experimentation platforms to enhanced ETL models and more, here are some more sessions coming to the 2024 Data Engineering Summit.
Data Ingestion Tools To facilitate the process, various tools and technologies are available. These tools can automate data collection, transformation, and loading processes, making it easier for organisations to manage their datapipelines effectively. The post What is Data Ingestion?
May be useful Best Workflow and Pipeline Orchestration Tools: Machine Learning Guide Phase 1—Datapipeline: getting the house in order Once the dust was settled, we got the Architecture Canvas completed, and the plan was clear to everyone involved, the next step was to take a closer look at the architecture. What’s in the box?
Then, it applies these insights to automate and orchestrate the data lifecycle. Instead of handling extract, transform and load (ETL) operations within a data lake, a data mesh defines the data as a product in multiple repositories, each given its own domain for managing its datapipeline.
This allows iterative dataanalysis workflows rather than rigid scripts. Python forms a common lingua franca for open data science thanks to its flexibility and the breadth of domain-specific packages continuously expanded by the active community. Think plugins, APIs, and microservices working in harmony across environments.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date. Unstructured.io
Traditionally, answering this question would involve multiple data exports, complex extract, transform, and load (ETL) processes, and careful data synchronization across systems. Users can write data to managed RMS tables using Iceberg APIs, Amazon Redshift, or Zero-ETL ingestion from supported data sources.
Summary: Data engineering tools streamline data collection, storage, and processing. Learning these tools is crucial for building scalable datapipelines. offers Data Science courses covering these tools with a job guarantee for career growth. Below are 20 essential tools every data engineer should know.
Current challenges in analyzing field trial data Agronomic field trials are complex and create vast amounts of data. Most companies are unable to use their field trial data based on manual processes and disparate systems. The first step in developing and deploying generative AI use cases is having a well-defined data strategy.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.





























Let's personalize your content