This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
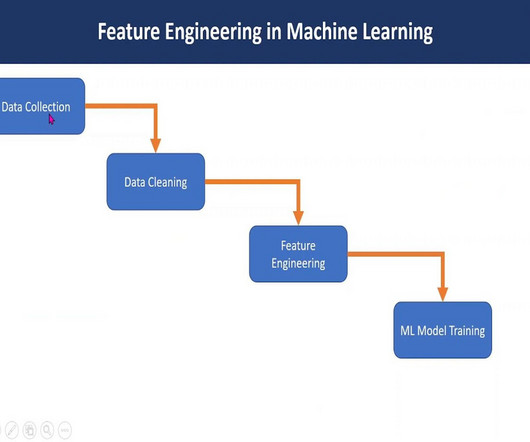
Feature engineering in machine learning is a pivotal process that transforms raw data into a format comprehensible to algorithms. Through ExploratoryDataAnalysis , imputation, and outlier handling, robust models are crafted. Time features Objective: Extracting valuable information from time-related data.
They assist in data cleaning, feature scaling, and transformation, ensuring that the data is in a suitable format for model training. This empowers developers to make informed decisions, optimize their models, and improve the overall quality of their machine learning solutions.
For more information, you can read the competition's Problem Description. Summary of approach: In the end I managed to create two submissions, both employing an ensemble of models trained across all 10-fold cross-validation (CV) splits, achieving a private leaderboard (LB) score of 0.7318.
This is a unique opportunity for data people to dive into real-world data and uncover insights that could shape the future of aviation safety, understanding, airline efficiency, and pilots driving planes. It’s also a good practice to perform cross-validation to assess the robustness of your model.
It involves selecting, extracting, and transforming raw data into informative features that capture the underlying patterns and relationships in the data. What is cross-validation, and why is it used in Machine Learning? However, there are a few fundamental principles that remain the same throughout.
Data storage : Store the data in a Snowflake data warehouse by creating a data pipe between AWS and Snowflake. Data Extraction, Preprocessing & EDA : Extract & Pre-process the data using Python and perform basic ExploratoryDataAnalysis. The data is in good shape.
This technique is widely used across various fields, including economics, finance, biology, engineering, and social sciences, to make predictions and inform decision-making. This data can come from various sources such as surveys, experiments, or historical records.
MicroMasters Program in Statistics and Data Science MIT – edX 1 year 2 months (INR 1,11,739) This program integrates Data Science, Statistics, and Machine Learning basics. It emphasises probabilistic modeling and Statistical inference for analysing big data and extracting information.
Applying XGBoost on a Problem Statement Applying XGBoost to Our Dataset Summary Citation Information Scaling Kaggle Competitions Using XGBoost: Part 4 Over the last few blog posts of this series, we have been steadily building up toward our grand finish: deciphering the mystery behind eXtreme Gradient Boosting (XGBoost) itself. What's next?
NLP tasks include machine translation, speech recognition, and sentiment analysis. Computer Vision This is a field of computer science that deals with the extraction of information from images and videos. ExploratoryDataAnalysis (EDA) EDA is a crucial preliminary step in understanding the characteristics of the dataset.
Summary: AI in Time Series Forecasting revolutionizes predictive analytics by leveraging advanced algorithms to identify patterns and trends in temporal data. This technology enables businesses to make informed decisions, optimize resources, and enhance strategic planning. billion in 2024 and is projected to reach a mark of USD 1339.1
One of the most effective programming languages used by Data Scientists is R, that helps them to conduct dataanalysis and make future predictions. Statistical modeling in R is enables by Data Scientists to extract meaningful information friom data and test hypotheses, ensuring that decision-making is efficient.
Many real estate players have long made decisions based on traditional data to answer the question of the quality of asset’s assessment and an investment’s location within a city. You can understand the data and model’s behavior at any time. parks and restaurants), and transportation networks. Rapid Modeling with DataRobot AutoML.
By understanding crucial concepts like Machine Learning, Data Mining, and Predictive Modelling, analysts can communicate effectively, collaborate with cross-functional teams, and make informed decisions that drive business success. Join us as we explore the language of Data Science and unlock your potential as a Data Analyst.
The blog also presents popular data analytics courses, emphasizing their curriculum, learning methods, certification opportunities, and benefits to help aspiring Data Analysts choose the proper training for their career advancement. Techniques such as cross-validation, regularisation , and feature selection can prevent overfitting.
Feature Engineering: Feature engineering involves creating new features from existing ones that may be more informative or relevant for the machine learning task. This process may involve combining or transforming existing features, or extracting new features from the data.
Data Science Project — Build a Decision Tree Model with Healthcare Data Using Decision Trees to Categorize Adverse Drug Reactions from Mild to Severe Photo by Maksim Goncharenok Decision trees are a powerful and popular machine learning technique for classification tasks.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















Let's personalize your content