
Feature Engineering in Machine Learning
Pickl AI
JANUARY 3, 2024
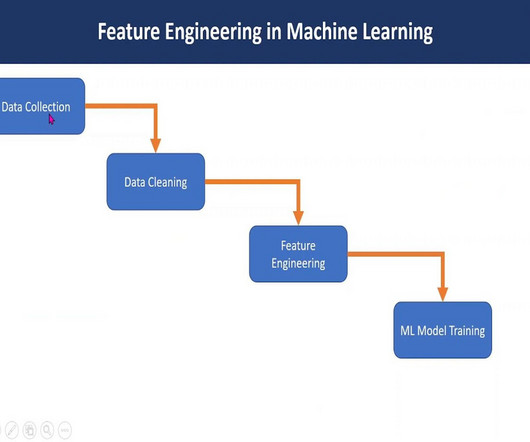
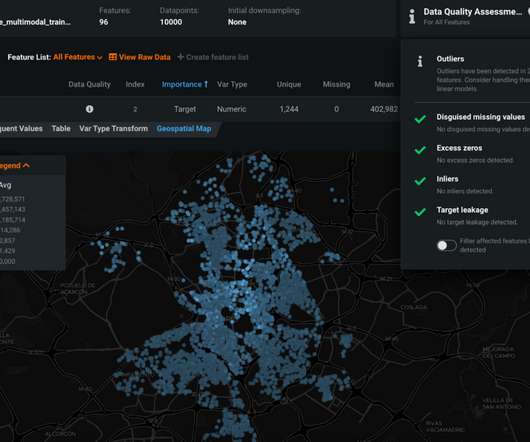
Feature engineering in machine learning is a pivotal process that transforms raw data into a format comprehensible to algorithms. Through Exploratory Data Analysis , imputation, and outlier handling, robust models are crafted. Steps of Feature Engineering 1.



















Let's personalize your content