This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
SupportVectorMachines (SVM) SVMs are powerful classification algorithms that work by finding the hyperplane that best separates different classes in high-dimensional space. K-Means Clustering K-means clustering partitions data into k distinct clusters based on feature similarity.
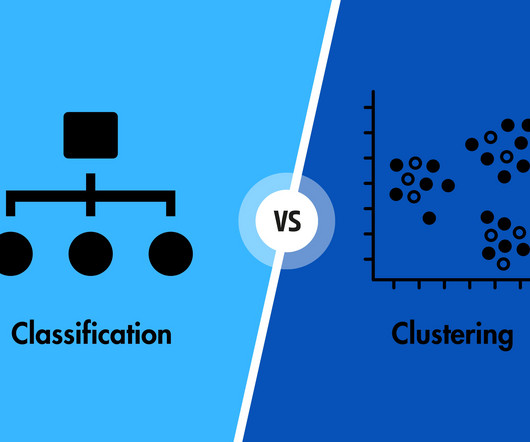
ML algorithms fall into various categories which can be generally characterised as Regression, Clustering, and Classification. While Classification is an example of directed Machine Learning technique, Clustering is an unsupervised Machine Learning algorithm. What is Classification?
Beginner’s Guide to ML-001: Introducing the Wonderful World of Machine Learning: An Introduction Everyone is using mobile or web applications which are based on one or other machine learning algorithms. You might be using machine learning algorithms from everything you see on OTT or everything you shop online.
The articles cover a range of topics, from the basics of Rust to more advanced machine learning concepts, and provide practical examples to help readers get started with implementing ML algorithms in Rust. One of the unique features of SmartCore is its emphasis on interpretability.
Machine learning (ML) technologies can drive decision-making in virtually all industries, from healthcare to human resources to finance and in myriad use cases, like computer vision , large language models (LLMs), speech recognition, self-driving cars and more. However, the growing influence of ML isn’t without complications.
We then discuss the various use cases and explore how you can use AWS services to clean the data, how machine learning (ML) can aid in this effort, and how you can make ethical use of the data in generating visuals and insights. The following reference architecture depicts a workflow using ML with geospatial data.
Basically, Machine learning is a part of the Artificial intelligence field, which is mainly defined as a technic that gives the possibility to predict the future based on a massive amount of past known or unknown data. ML algorithms can be broadly divided into supervised learning , unsupervised learning , and reinforcement learning.
This is where the power of machine learning (ML) comes into play. Machine learning algorithms, with their ability to recognize patterns, anomalies, and trends within vast datasets, are revolutionizing network traffic analysis by providing more accurate insights, faster response times, and enhanced security measures.
values.tolist() neigh = KNeighborsClassifier(n_neighbors=3) neigh.fit(X_train_emb, y_train) y_pred = neigh.predict(X_test_emb) print(classification_report(y_test, y_pred, target_names=['Conversation', 'Document_Translation', 'Services'])) We used the Amazon Titan Text Embeddings G1 model, which generates vectors of 1,536 dimensions.
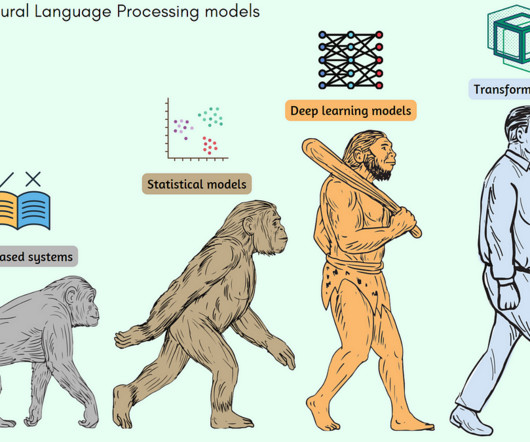
In this article, we’ll look at the evolution of these state-of-the-art (SOTA) models and algorithms, the ML techniques behind them, the people who envisioned them, and the papers that introduced them. The earlier models that were SOTA for NLP mainly fell under the traditional machine learning algorithms.
To address this challenge, data scientists harness the power of machine learning to predict customer churn and develop strategies for customer retention. I write about Machine Learning on Medium || Github || Kaggle || Linkedin. ? Our project uses Comet ML to: 1. The entire code can be found on both GitHub and Kaggle.
Understanding Machine Learning algorithms and effective data handling are also critical for success in the field. Introduction Machine Learning ( ML ) is revolutionising industries, from healthcare and finance to retail and manufacturing. Fundamental Programming Skills Strong programming skills are essential for success in ML.
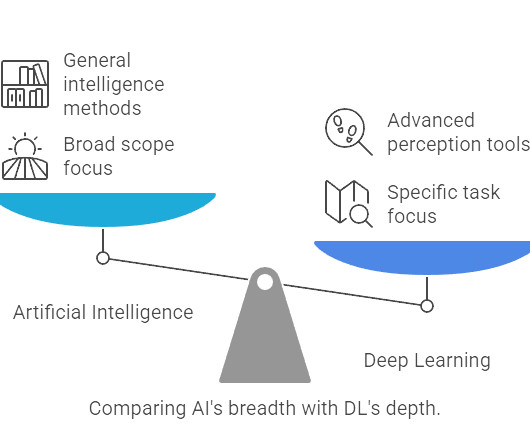
Summary: Machine Learning and Deep Learning are AI subsets with distinct applications. ML works with structured data, while DL processes complex, unstructured data. ML requires less computing power, whereas DL excels with large datasets. Key Takeaways ML requires structured data, while DL handles complex, unstructured data.
Introduction In today’s rapidly evolving technological landscape, terms like Artificial Intelligence (AI), Machine Learning (ML), and Deep Learning (DL) are thrown around constantly. This led to the rise of Machine Learning (ML). Machine Learning is a subset of Artificial Intelligence.
ML algorithms for analyzing IoT data using artificial intelligence Machine learning forms the foundation of AI in IoT, allowing devices to learn patterns, make predictions, and adapt to changing circumstances. Unsupervised learning Unsupervised learning involves training machine learning models with unlabeled datasets.
Here are a few of the key concepts that you should know: Machine Learning (ML) This is a type of AI that allows computers to learn without being explicitly programmed. Machine Learning algorithms are trained on large amounts of data, and they can then use that data to make predictions or decisions about new data.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? Let’s dig deeper and learn more about them!
Source: [link] Similarly, while building any machine learning-based product or service, training and evaluating the model on a few real-world samples does not necessarily mean the end of your responsibilities. You need to make that model available to the end users, monitor it, and retrain it for better performance if needed. What is MLOps?
This harmonization is particularly critical in algorithms such as k-Nearest Neighbors and SupportVectorMachines, where distances dictate decisions. To start your learning journey in Machine Learning, you can opt for a free course in ML.
49% of companies in the world that use Machine Learning and AI in their marketing and sales processes apply it to identify the prospects of sales. On the other hand, 48% use ML and AI for gaining insights into the prospects and customers. Anomalies, being different from normal data, result in higher reconstruction errors.
Netflix-style if-you-like-these-movies-you’ll-like-this-one-too) All kinds of search Text search (like Google Search) Image search (like Google Reverse Image Search) Chatbots and question-answering systems Data preprocessing (preparing data to be fed into a machine learning model) One-shot/zero-shot learning (i.e.
Machine Learning Tools in Bioinformatics Machine learning is vital in bioinformatics, providing data scientists and machine learning engineers with powerful tools to extract knowledge from biological data. Clustering algorithms can group similar biological samples or identify distinct subtypes within a disease.
left: neutral pose — do nothing | right: fist — close gripper | Photos from myo-readings-dataset left: extension — move forward | right: flexion — move backward | Photos from myo-readings-dataset This project uses the scikit-learn implementation of a SupportVectorMachine (SVM) trained for gesture recognition.
Scikit-learn: Scikit-learn is an open-source library that provides a range of tools for building and training machine learning models, including classification, regression, and clustering. Algorithm selection: Choose algorithms that are less prone to biases, such as decision trees or supportvectormachines.
As MLOps become more relevant to ML demand for strong software architecture skills will increase aswell. Machine Learning As machine learning is one of the most notable disciplines under data science, most employers are looking to build a team to work on ML fundamentals like algorithms, automation, and so on.
Explore Machine Learning with Python: Become familiar with prominent Python artificial intelligence libraries such as sci-kit-learn and TensorFlow. Begin by employing algorithms for supervised learning such as linear regression , logistic regression, decision trees, and supportvectormachines.
Machine Learning Machine Learning (ML) is a crucial component of Data Science. ML models help predict outcomes, automate tasks, and improve decision-making by identifying patterns in large datasets. Unsupervised Learning techniques such as clustering and dimensionality reduction to discover patterns in data.
This allows it to evaluate and find relationships between the data points which is essential for clustering. Supports batch processing for quick processing for the images. For instance, clustering algorithms like k-means can identify distinct groups within data, or distance-based methods can prioritize outliers.
There are majorly two categories of sampling techniques based on the usage of statistics, they are: Probability Sampling techniques: Clustered sampling, Simple random sampling, and Stratified sampling. It is introduced into an ML Model when an ML algorithm is made highly complex. These are called supportvectors.
Some participants combined a transformer neural network with a tree-based model or supportvectormachine (SVM). For more practical guidance about extracting ML features from speech data, including example code to generate transformer embeddings, see this blog post ! Cluster 1 and 2 were both Spanish.
Definition of Supervised Learning and Unsupervised Learning Supervised learning is a process where an ML model is trained using labeled data. After training, the machine learning model can predict outcomes for new, unseen data. The ML algorithm tries to find hidden patterns and structures in this data.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















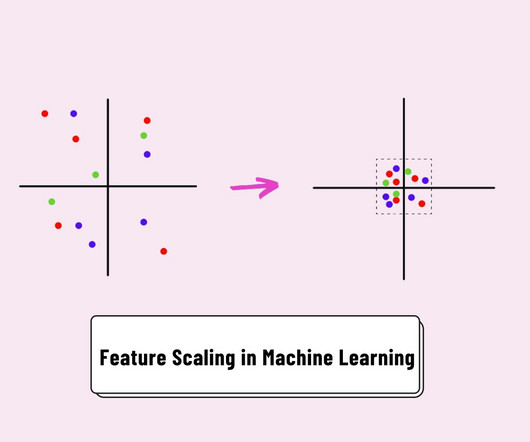

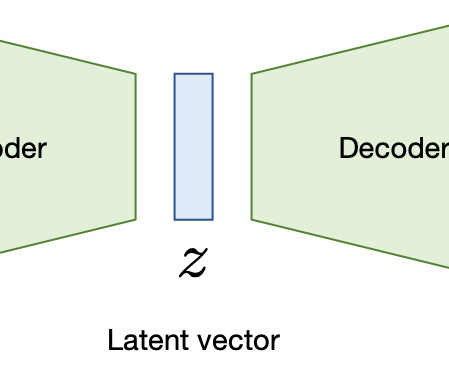
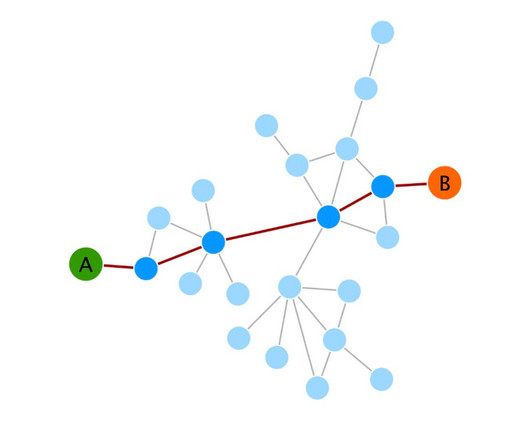















Let's personalize your content