This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
By understanding machine learning algorithms, you can appreciate the power of this technology and how it’s changing the world around you! It’s like having a super-powered tool to sort through information and make better sense of the world. Learn in detail about machine learning algorithms 2.
Learn how to apply state-of-the-art clustering algorithms efficiently and boost your machine-learning skills.Image source: unsplash.com. Each book is a unique piece of information, and your goal is to organize them based on their characteristics. This is called clustering. As… Read the full blog for free on Medium.
They are also used in machine learning, such as supportvectormachines and k-means clustering. Robust inference: Robust inference is a technique that is used to make inferences that are not sensitive to outliers or extreme observations.
Matplotlib is a great tool for data visualization and is widely used in data analysis, scientific computing, and machine learning. Seaborn Seaborn is a library for creating attractive and informative statistical graphics in Python. Scikit-learn Scikit-learn is a powerful library for machine learning in Python.
Example: Determining whether an email is spam or not based on features like word frequency and sender information. SupportVectorMachines (SVM) SVMs are powerful classification algorithms that work by finding the hyperplane that best separates different classes in high-dimensional space.
Matplotlib is a great tool for data visualization and is widely used in data analysis, scientific computing, and machine learning. Seaborn Seaborn is a library for creating attractive and informative statistical graphics in Python. Scikit-learn Scikit-learn is a powerful library for machine learning in Python.
Throughout the course of history, the significance of creating and disseminating information has been immensely crucial. Moreover, statistical inference empowers them to make informed decisions and draw meaningful conclusions based on sample data. Supportvectormachines are used to classify data and to predict continuous outcomes.
SmartCore SmartCore is a machine learning library written in Rust that provides a variety of algorithms for regression, classification, clustering, and more. Many of the algorithms included in SmartCore provide detailed information about the models they build, including feature importance, decision paths, and more.
Home Table of Contents Credit Card Fraud Detection Using Spectral Clustering Understanding Anomaly Detection: Concepts, Types and Algorithms What Is Anomaly Detection? Spectral clustering, a technique rooted in graph theory, offers a unique way to detect anomalies by transforming data into a graph and analyzing its spectral properties.
Examples include: Spam vs. Not Spam Disease Positive vs. Negative Fraudulent Transaction vs. Legitimate Transaction Popular algorithms for binary classification include Logistic Regression, SupportVectorMachines (SVM), and Decision Trees. These models can detect subtle patterns that might be missed by human radiologists.
Data mining can help governments identify areas of concern, allocate resources, and make informed policy decisions. In data mining, popular algorithms include decision trees, supportvectormachines, and k-means clustering.
It guarantees reliable information, essential for applications like disaster management and environmental monitoring while optimizing processing time and resource use. Tailoring the algorithm to the specific data type and application enhances performance and interpretability, facilitating clear communication and informed decision-making.
Develop Hybrid Models Combine traditional analytical methods with modern algorithms such as decision trees, neural networks, and supportvectormachines. Clustering algorithms, such as k-means, group similar data points, and regression models predict trends based on historical data.
We can analyze activities by identifying stops made by the user or mobile device by clustering pings using ML models in Amazon SageMaker. For more information, refer to Common techniques to detect PHI and PII data using AWS Services. Manually managing a DIY compute cluster is slow and expensive.
Adding such extra information should improve the classification compared to the previous method (Principle Label Space Transformation). The feature space reduction is performed by aggregating clusters of features of balanced size. This clustering is usually performed using hierarchical clustering.
On the other hand, artificial intelligence is the simulation of human intelligence in machines that are programmed to think and learn like humans. By leveraging advanced algorithms and machine learning techniques, IoT devices can analyze and interpret data in real-time, enabling them to make informed decisions and take autonomous actions.
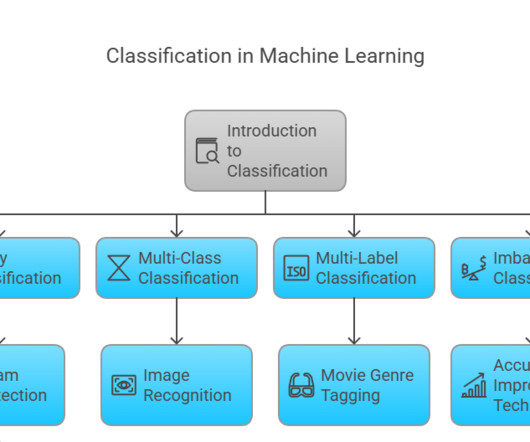
The classification model learns from the training data, identifying the distinguishing characteristics between each class, enabling it to make informed predictions. Classification in machine learning can be a versatile tool with numerous applications across various industries. Next, you need to select a model.
Machine learning algorithms for unstructured data include: K-means: This algorithm is a data visualization technique that processes data points through a mathematical equation with the intention of clustering similar data points. Isolation forest models can be found on the free machine learning library for Python, scikit-learn.
Common Machine Learning Algorithms Machine learning algorithms are not limited to those mentioned below, but these are a few which are very common. Linear Regression Decision Trees SupportVectorMachines Neural Networks Clustering Algorithms (e.g., Models […]
Examples of supervised learning models include linear regression, decision trees, supportvectormachines, and neural networks. Common examples include: Linear Regression: It is the best Machine Learning model and is used for predicting continuous numerical values based on input features.
Services class Texts belonging to this class consist of explicit requests for services such as room reservations, hotel bookings, dining services, cinema information, tourism-related inquiries, and similar service-oriented requests. Embeddings are vector representations of text that capture semantic and contextual information.
Logistic Regression K-Nearest Neighbors (K-NN) SupportVectorMachine (SVM) Kernel SVM Naive Bayes Decision Tree Classification Random Forest Classification I will not go too deep about these algorithms in this article, but it’s worth it for you to do it yourself. Great example of this tecnique is K-means clustering algorithm.
Text mining is primarily a technique in the field of Data Science that encompasses the extraction of meaningful insights and information from unstructured textual data. This helps businesses gain insights into market trends, consumer preferences, and competitive landscapes, allowing them to make informed strategic decisions.
In this era of information overload, utilizing the power of data and technology has become paramount to drive effective decision-making. It enables organizations to make informed choices, capitalize on emerging trends, and seize growth opportunities with confidence. What is decision intelligence?
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? For more information, click here.
Some of the common types are: Linear Regression Deep Neural Networks Logistic Regression Decision Trees AI Linear Discriminant Analysis Naive Bayes SupportVectorMachines Learning Vector Quantization K-nearest Neighbors Random Forest What do they mean? For more information, click here.
Flow analysis tools like IPFIX, NetFlow, and sFlow collect flow data, which includes information about source and destination IPs, ports, and protocols. Clustering can help in identifying patterns and anomalies within specific groups What are the best machine learning tools to analyze network traffic?
The earlier models that were SOTA for NLP mainly fell under the traditional machine learning algorithms. These included the Supportvectormachine (SVM) based models. Use Cases : Web Search, Information Retrieval, Text Mining Significant papers: “ Latent Dirichlet Allocation ” by Blei et al.
NLP tasks include machine translation, speech recognition, and sentiment analysis. Computer Vision This is a field of computer science that deals with the extraction of information from images and videos. EDA guides subsequent preprocessing steps and informs the selection of appropriate AI algorithms based on data insights.
Determinants and Inverses The determinant of a square matrix provides information about the matrix’s properties, such as whether it is invertible (non-singular) or not (singular). These techniques enhance algorithm efficiency and improve performance across various Machine Learning tasks.
Machine Learning Algorithms Candidates should demonstrate proficiency in a variety of Machine Learning algorithms, including linear regression, logistic regression, decision trees, random forests, supportvectormachines, and neural networks. How do you handle missing values in a dataset?
Customer Feedback: Understanding why customers leave provides valuable information to improve your service. Model stacking involves training multiple machine learning models and using another model to combine their predictions to improve accuracy. Are there clusters of customers with different spending patterns? #3.
It encompasses various models and techniques, applicable across industries like finance and healthcare, to drive informed decision-making. Introduction Statistical Modeling is crucial for analysing data, identifying patterns, and making informed decisions. Popular clustering algorithms include k-means and hierarchical clustering.
We need a way to use lower-dimensionality to represent most information as one-hot encoding does. It leverages the overall word co-occurrence information in the entire corpus and computes word vectors based on the probability of a word appearing near another word in the corpus.
In many fields, finding anomalies can yield insightful data and useful information. Density-Based Spatial Clustering of Applications with Noise (DBSCAN): DBSCAN is a density-based clustering algorithm. It identifies regions of high data point density as clusters and flags points with low densities as anomalies.
Researchers can comprehensively understand biological systems by combining information from genomics, transcriptomics, proteomics, and other omics fields. b) Data Privacy and Security: As bioinformatics deals with sensitive genetic and health-related information, ensuring data privacy and security is crucial.
Basic Concepts of Machine Learning Machine Learning revolves around training algorithms to learn from data. The training process involves feeding data into a model, allowing it to make predictions or classify information based on patterns observed. Clustering and anomaly detection are examples of unsupervised learning tasks.
What type of text or information do you aim to extract? scikit-learn – The most widely Machine learning for text used for Python, scikit-learn is an open-source, free machine learning library. It has many useful tools for stats modeling and machine learning including regression, classification, and clustering.
Scikit-learn: Scikit-learn is an open-source library that provides a range of tools for building and training machine learning models, including classification, regression, and clustering. Feature engineering: Improve the quality of the input data by performing feature engineering to capture more information.
By understanding crucial concepts like Machine Learning, Data Mining, and Predictive Modelling, analysts can communicate effectively, collaborate with cross-functional teams, and make informed decisions that drive business success. Data Science is the art and science of extracting valuable information from data.
Organisations must develop strategies to store and manage this vast amount of information effectively. Some of the most notable technologies include: Hadoop An open-source framework that allows for distributed storage and processing of large datasets across clusters of computers.
We must understand that not all the data samples contribute to providing valuable information. Faster Learning Curve Active Learning achieves better model performance with fewer labeled examples by focusing on the most informative cases. But why is this an important and valuable approach? Reason, presence of redundant samples.
Machine Learning Algorithms and Techniques Machine Learning offers a variety of algorithms and techniques that help models learn from data and make informed decisions. SupportVectorMachines (SVM) SVMs are powerful classifiers that separate data into distinct categories by finding an optimal hyperplane.
These include: Reasoning: Drawing logical conclusions from information. Knowledge Representation: Storing and organizing information effectively. It’s about building systems that can perform tasks that typically require human intelligence. What kind of tasks? Problem-Solving: Finding solutions to complex challenges.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content