This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This year, generative AI and machine learning (ML) will again be in focus, with exciting keynote announcements and a variety of sessions showcasing insights from AWS experts, customer stories, and hands-on experiences with AWS services. Visit the session catalog to learn about all our generative AI and ML sessions.
The banking industry has long struggled with the inefficiencies associated with repetitive processes such as information extraction, document review, and auditing. To further enhance the capabilities of specialized information extraction solutions, advanced ML infrastructure is essential.
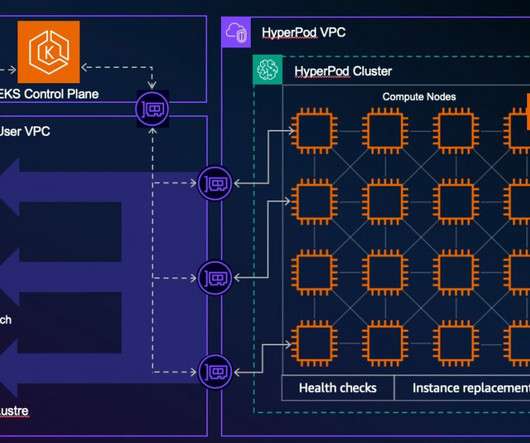
SageMaker HyperPod is a purpose-built infrastructure service that automates the management of large-scale AI training clusters so developers can efficiently build and train complex models such as large language models (LLMs) by automatically handling cluster provisioning, monitoring, and fault tolerance across thousands of GPUs.
The launcher interfaces with underlying cluster management systems such as SageMaker HyperPod (Slurm or Kubernetes) or training jobs, which handle resource allocation and scheduling. Alternatively, you can use a launcher script, which is a bash script that is preconfigured to run the chosen training or fine-tuning job on your cluster.
Businesses are under pressure to show return on investment (ROI) from AI use cases, whether predictive machine learning (ML) or generative AI. Only 54% of ML prototypes make it to production, and only 5% of generative AI use cases make it to production. Using SageMaker, you can build, train and deploy ML models.
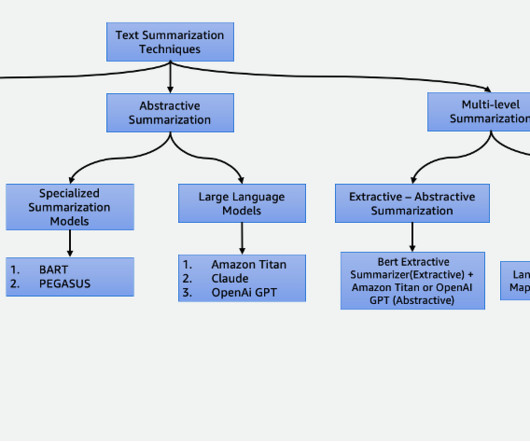
The model then uses a clustering algorithm to group the sentences into clusters. The sentences that are closest to the center of each cluster are selected to form the summary. Implementation includes the following steps: The first step is to break down the large document, such as a book, into smaller sections, or chunks.
This allows SageMaker Studio users to perform petabyte-scale interactive data preparation, exploration, and machine learning (ML) directly within their familiar Studio notebooks, without the need to manage the underlying compute infrastructure. This same interface is also used for provisioning EMR clusters.
Snowpark ML is transforming the way that organizations implement AI solutions. Snowpark allows ML models and code to run on Snowflake warehouses. By “bringing the code to the data,” we’ve seen ML applications run anywhere from 4-100x faster than other architectures. Let’s create a table to hold our document vectors.
For modern companies that deal with enormous volumes of documents such as contracts, invoices, resumes, and reports, efficiently processing and retrieving pertinent data is critical to maintaining a competitive edge. What if there was a way to process documents intelligently and make them searchable in with high accuracy?
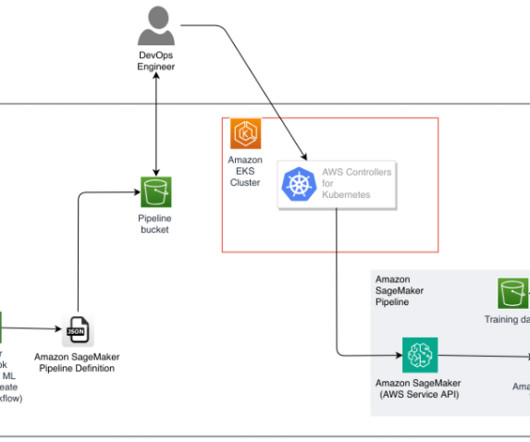
Amazon SageMaker HyperPod is purpose-built to accelerate foundation model (FM) training, removing the undifferentiated heavy lifting involved in managing and optimizing a large training compute cluster. In this solution, HyperPod cluster instances use the LDAPS protocol to connect to the AWS Managed Microsoft AD via an NLB.
As a global leader in agriculture, Syngenta has led the charge in using data science and machine learning (ML) to elevate customer experiences with an unwavering commitment to innovation. Efficient metadata storage with Amazon DynamoDB – To support quick and efficient data retrieval, document metadata is stored in Amazon DynamoDB.
By accelerating the speed of issue detection and remediation, it increases the reliability of your ML training and reduces the wasted time and cost due to hardware failure. Choose Clusters in the navigation pane, open the trainium-inferentia cluster, choose Node groups, and locate your node group. # install.sh
Overview of vector search and the OpenSearch Vector Engine Vector search is a technique that improves search quality by enabling similarity matching on content that has been encoded by machine learning (ML) models into vectors (numerical encodings). These benchmarks arent designed for evaluating ML models.
Customers want to search through all of the data and applications across their organization, and they want to see the provenance information for all of the documents retrieved. For more details about RDF data format, refer to the W3C documentation. The following is an example of RDF triples in N-triples file format: "sales_qty_sold".
Recent developments in machine learning (ML) have led to increasingly large models, some of which require hundreds of billions of parameters. In such distributed environments, observability of both instances and ML chips becomes key to model performance fine-tuning and cost optimization.
Question and answering (Q&A) using documents is a commonly used application in various use cases like customer support chatbots, legal research assistants, and healthcare advisors. In this collaboration, the AWS GenAIIC team created a RAG-based solution for Deltek to enable Q&A on single and multiple government solicitation documents.
TensorFlow provides high-level APIs, such as tf.distribute, to distribute training across multiple devices, machines, or clusters. It is recommended to evaluate each framework’s documentation, performance benchmarks, and community support to determine the best fit for your distributed learning needs.
At its core, Ray offers a unified programming model that allows developers to seamlessly scale their applications from a single machine to a distributed cluster. Ray promotes the same coding patterns for both a simple machine learning (ML) experiment and a scalable, resilient production application.
On June 12, 2025 at NVIDIA GTC Paris, learn more about cuML and clustering algorithms during the hands-on workshop, Accelerate Clustering Algorithms to Achieve the Highest Performance. Data-Intensive Workloads Today’s data is growing at an unprecedented rate which makes for highly complex data processing workflows for ML.
Although QLoRA helps optimize memory during fine-tuning, we will use Amazon SageMaker Training to spin up a resilient training cluster, manage orchestration, and monitor the cluster for failures. To take complete advantage of this multi-GPU cluster, we use the recent support of QLoRA and PyTorch FSDP. 24xlarge compute instance.
Organizations can search for PII using methods such as keyword searches, pattern matching, data loss prevention tools, machine learning (ML), metadata analysis, data classification software, optical character recognition (OCR), document fingerprinting, and encryption.
Unsupervised ML: The Basics. Unlike supervised ML, we do not manage the unsupervised model. Unsupervised ML uses algorithms that draw conclusions on unlabeled datasets. As a result, unsupervised ML algorithms are more elaborate than supervised ones, since we have little to no information or the predicted outcomes.
We recently announced the general availability of cross-account sharing of Amazon SageMaker Model Registry using AWS Resource Access Manager (AWS RAM) , making it easier to securely share and discover machine learning (ML) models across your AWS accounts.
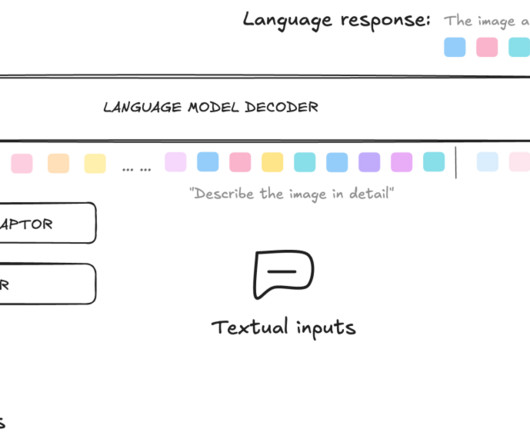
This significant improvement showcases how the fine-tuning process can equip these powerful multimodal AI systems with specialized skills for excelling at understanding and answering natural language questions about complex, document-based visual information. For a detailed walkthrough on fine-tuning the Meta Llama 3.2
These longer sequence lengths allow models to better understand long-range dependencies in text, generate more globally coherent outputs, and handle tasks requiring analysis of lengthy documents. After they’re initiated, SageMaker training jobs spin up the cluster, provisioning the specified number and type of compute instances.
The Retrieval-Augmented Generation (RAG) framework augments prompts with external data from multiple sources, such as document repositories, databases, or APIs, to make foundation models effective for domain-specific tasks. Amazon SageMaker enables enterprises to build, train, and deploy machine learning (ML) models.
Tesla’s Automated Driving Documents Have Been Requested by The U.S. Architectures for Running ML at the Edge Tue, Feb 28, 2023, 12:00 PM — 1:00 PM EST In this webinar, we will explore different paradigms for edge deployment of ML models, including federated learning, cloud-edge hybrid architectures, and standalone edge models.
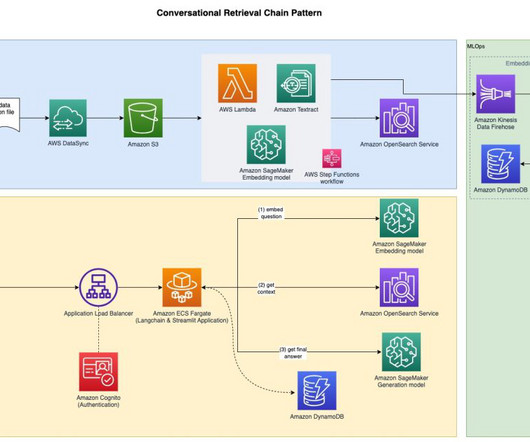
This post presents a solution for developing a chatbot capable of answering queries from both documentation and databases, with straightforward deployment. For documentation retrieval, Retrieval Augmented Generation (RAG) stands out as a key tool. Virginia) AWS Region. The following diagram illustrates the solution architecture.
With HyperPod, users can begin the process by connecting to the login/head node of the Slurm cluster. Alternatively, you can also use the AWS CloudFormation template provided in the Own Account workshop and follow the instructions to set up a cluster and a development environment to access and submit jobs to the cluster.
This code can cover a diverse array of tasks, such as creating a KMeans cluster, in which users input their data and ask ChatGPT to generate the relevant code. This is where ML CoPilot enters the scene. In this paper, the authors suggest the use of LLMs to make use of past ML experiences to suggest solutions for new ML tasks.
Amazon OpenSearch Service is a fully managed solution that simplifies the deployment, operation, and scaling of OpenSearch clusters in the AWS Cloud. Full-Text and Structured Search: Powers fast, scalable, and accurate search for e-commerce, enterprise search, and document retrieval systems. following Elastics licensing changes.
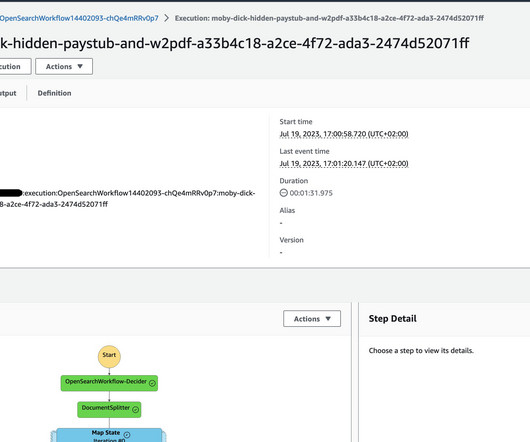
The traditional approach of manually sifting through countless research documents, industry reports, and financial statements is not only time-consuming but can also lead to missed opportunities and incomplete analysis. This event-driven architecture provides immediate processing of new documents.
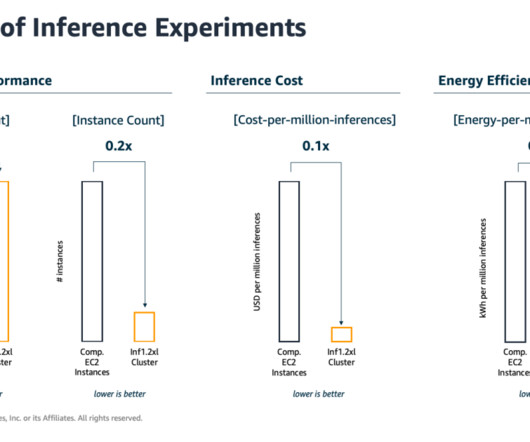
Machine learning (ML) engineers have traditionally focused on striking a balance between model training and deployment cost vs. performance. This is important because training ML models and then using the trained models to make predictions (inference) can be highly energy-intensive tasks.
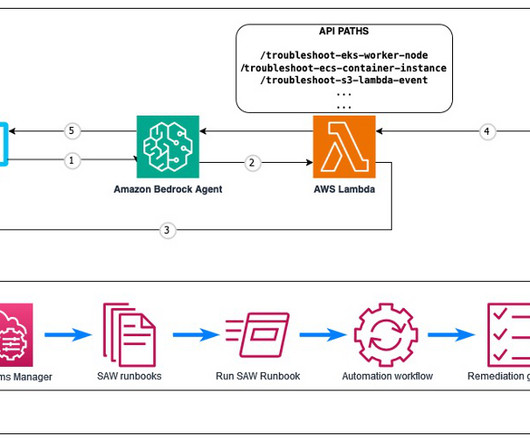
Solution overview Although the solution is versatile and can be adapted to use a variety of AWS Support Automation Workflows, we focus on a specific example: troubleshooting an Amazon Elastic Kubernetes Service (Amazon EKS) worker node that failed to join a cluster. For example, Why isnt my EKS worker node joining the cluster?
Companies across various industries create, scan, and store large volumes of PDF documents. There’s a need to find a scalable, reliable, and cost-effective solution to translate documents while retaining the original document formatting. It also uses the open-source Java library Apache PDFBox to create PDF documents.
The onset of the pandemic has triggered a rapid increase in the demand and adoption of ML technology. Building ML team Following the surge in ML use cases that have the potential to transform business, the leaders are making a significant investment in ML collaboration, building teams that can deliver the promise of machine learning.
Its scalability and load-balancing capabilities make it ideal for handling the variable workloads typical of machine learning (ML) applications. Amazon SageMaker provides capabilities to remove the undifferentiated heavy lifting of building and deploying ML models. kubectl for working with Kubernetes clusters.
Their impact on ML tasks has made them a cornerstone of AI advancements. It allows ML models to work with data but in a limited manner. Hence, while it is helpful to develop a basic understanding of a document, it is limited in forming a connection between words to grasp a deeper meaning.
Have you ever faced the challenge of obtaining high-quality data for fine-tuning your machine learning (ML) models? For instance, when developing a medical search engine, obtaining a large dataset of real user queries and relevant documents is often infeasible due to privacy concerns surrounding personal health information.
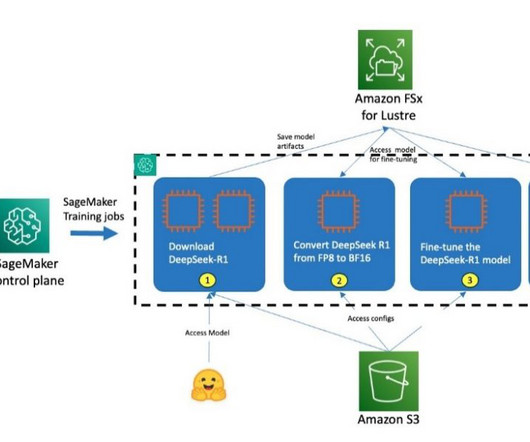
In this post, we dive into how organizations can use Amazon SageMaker AI , a fully managed service that allows you to build, train, and deploy ML models at scale, and can build AI agents using CrewAI, a popular agentic framework and open source models like DeepSeek-R1.
In this post, you’ll see an example of performing drift detection on embedding vectors using a clustering technique with large language models (LLMS) deployed from Amazon SageMaker JumpStart. Then we use K-Means to identify a set of cluster centers. A visual representation of the silhouette score can be seen in the following figure.
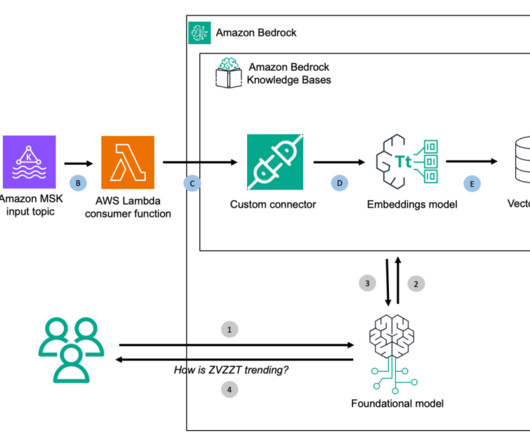
With custom data connectors, you can quickly ingest specific documents from custom data sources without requiring a full sync and ingest streaming data without the need for intermediary storage. The next step is to use a SageMaker Studio terminal instance to connect to the MSK cluster and create the test stream topic.
With cloud computing, as compute power and data became more available, machine learning (ML) is now making an impact across every industry and is a core part of every business and industry. Amazon SageMaker Studio is the first fully integrated ML development environment (IDE) with a web-based visual interface.
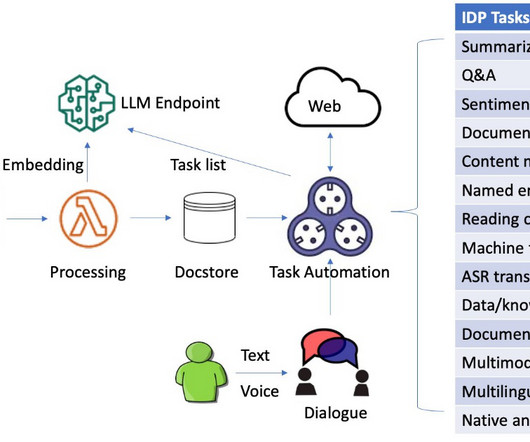
Intelligent document processing (IDP) is a technology that automates the processing of high volumes of unstructured data, including text, images, and videos. The system is capable of processing images, large PDF, and documents in other format and answering questions derived from the content via interactive text or voice inputs.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content