This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
While customers can perform some basic analysis within their operational or transactional databases, many still need to build custom datapipelines that use batch or streaming jobs to extract, transform, and load (ETL) data into their data warehouse for more comprehensive analysis. or a later version) database.
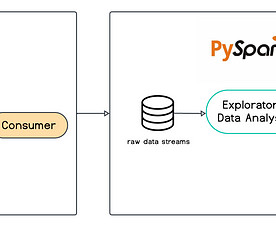
The following diagram illustrates the datapipeline for indexing and query in the foundational search architecture. The listing writer microservice publishes listing change events to an Amazon Simple Notification Service (Amazon SNS) topic, which an Amazon Simple Queue Service (Amazon SQS) queue subscribes to.
You can safely use an Apache Kafka cluster for seamless data movement from the on-premise hardware solution to the data lake using various cloud services like Amazon’s S3 and others. It is because you usually see Kafka producers publish data or push it towards a Kafka topic so that the application can consume the data.
Apache Kafka plays a crucial role in enabling data processing in real-time by efficiently managing data streams and facilitating seamless communication between various components of the system. Apache Kafka Apache Kafka is a distributed event streaming platform used for building real-time datapipelines and streaming applications.
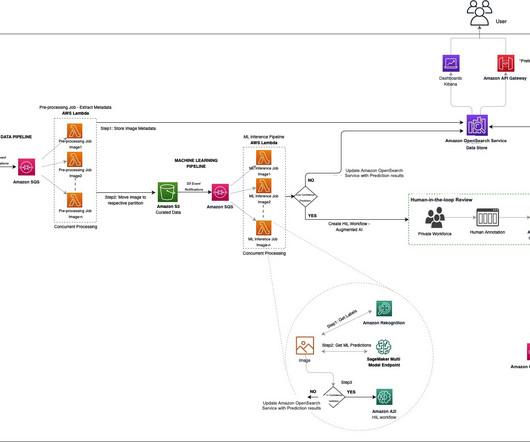
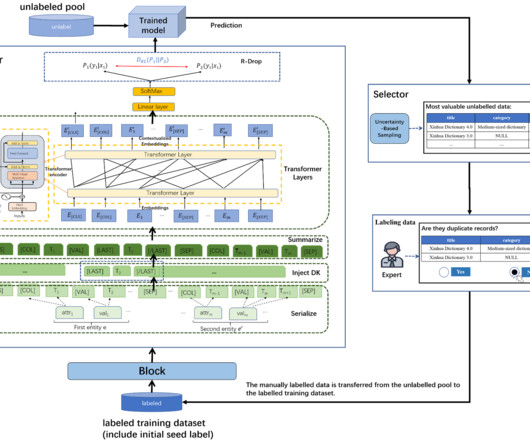
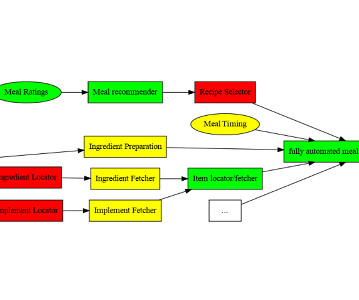
Solution overview In brief, the solution involved building three pipelines: Datapipeline – Extracts the metadata of the images Machine learning pipeline – Classifies and labels images Human-in-the-loop review pipeline – Uses a human team to review results The following diagram illustrates the solution architecture.
Image Source — Pixel Production Inc In the previous article, you were introduced to the intricacies of datapipelines, including the two major types of existing datapipelines. You might be curious how a simple tool like Apache Airflow can be powerful for managing complex datapipelines.
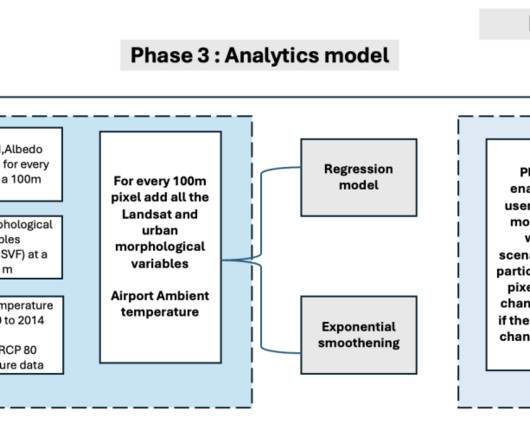
This analytical model provides accurate estimates of land surface temperature (LST) at a granular level, allowing Gramener to quantify changes in the UHI effect based on parameters (names of indexes and data used). It allocates cluster resources for the duration of the job and removes them upon job completion.
Machine Learning : Supervised and unsupervised learning algorithms, including regression, classification, clustering, and deep learning. Big Data Technologies : Handling and processing large datasets using tools like Hadoop, Spark, and cloud platforms such as AWS and Google Cloud.
In this post, you will learn about the 10 best datapipeline tools, their pros, cons, and pricing. A typical datapipeline involves the following steps or processes through which the data passes before being consumed by a downstream process, such as an ML model training process.
Apache Kafka is an open-source , distributed streaming platform that allows developers to build real-time, event-driven applications. With Apache Kafka, developers can build applications that continuously use streaming data records and deliver real-time experiences to users.
In this post, we discuss how to bring data stored in Amazon DocumentDB into SageMaker Canvas and use that data to build ML models for predictive analytics. Without creating and maintaining datapipelines, you will be able to power ML models with your unstructured data stored in Amazon DocumentDB.
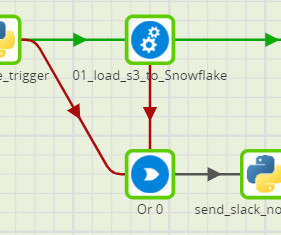
Orchestrating pipelines – Agent Creator orchestrates workflows using interconnected snaps, each performing a specific function such as ingestion, chunking, vectorization, or querying. The architecture employs an event-driven model, where the completion of one snap triggers the next step in the workflow.
HPCC Systems and Spark also differ in that they work with distinct parts of the big datapipeline. Spark is more focused on data science, ingestion, and ETL, while HPCC Systems focuses on ETL and data delivery and governance. You describe HPCC Systems as a complete data lake platform. Can you get more granular?
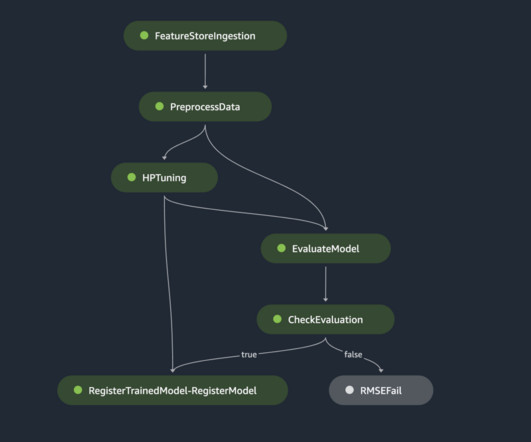
With Ray and AIR, the same Python code can scale seamlessly from a laptop to a large cluster. Prepare the source data for the feature store by adding an event time and record ID for each row of data. Ingest the prepared data into the feature group by using the Boto3 SDK.
Learning means identifying and capturing historical patterns from the data, and inference means mapping a current value to the historical pattern. The following figure illustrates the idea of a large cluster of GPUs being used for learning, followed by a smaller number for inference.
Effective data governance enhances quality and security throughout the data lifecycle. What is Data Engineering? Data Engineering is designing, constructing, and managing systems that enable data collection, storage, and analysis. They are crucial in ensuring data is readily available for analysis and reporting.
It provides tools and components to facilitate end-to-end ML workflows, including data preprocessing, training, serving, and monitoring. Kubeflow integrates with popular ML frameworks, supports versioning and collaboration, and simplifies the deployment and management of ML pipelines on Kubernetes clusters.
Flow-Based Programming : NiFi employs a flow-based programming model, allowing users to create complex data flows using simple drag-and-drop operations. This visual representation simplifies the design and management of datapipelines. Provenance Repository : This repository records all provenance events related to FlowFiles.
Similar Audio: Audio recordings of the same event or sound but with different microphone placements or background noise. Clustering: Clustering can group texts using features like embedding vectors or TF-IDF vectors. Duplicate texts naturally tend to fall into the same clusters. Clustering Techniques (e.g.,
Introduction to LangChain for Including AI from Large Language Models (LLMs) Inside Data Applications and DataPipelines This article will provide an overview of LangChain, the problems it addresses, its use cases, and some of its limitations. Python : Great for including AI in Python-based software or datapipelines.
Image generated with Midjourney In today’s fast-paced world of data science, building impactful machine learning models relies on much more than selecting the best algorithm for the job. Data scientists and machine learning engineers need to collaborate to make sure that together with the model, they develop robust datapipelines.
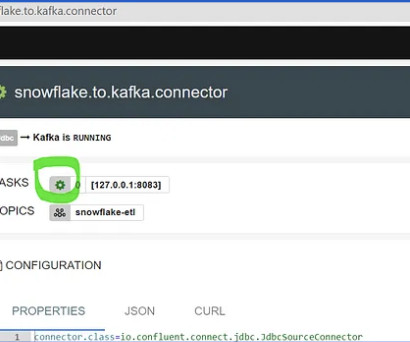
How Snowflake Helps Achieve Real-Time Analytics Snowflake is the ideal platform to achieve real-time analytics for several reasons, but two of the biggest are its ability to manage concurrency due to the multi-cluster architecture of Snowflake and its robust connections to 3rd party tools like Kafka.
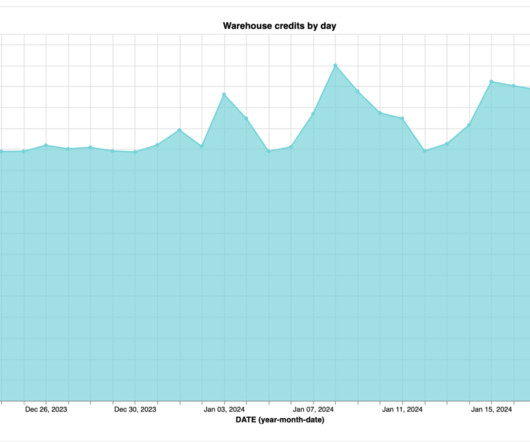
Operational Risks: Uncover operational risks such as data loss or failures in the event of an unforeseen outage or disaster. Performance Optimization: Locate and fix bottlenecks in your datapipelines so that you can get the most out of your Snowflake investment.
With proper unstructured data management, you can write validation checks to detect multiple entries of the same data. Continuous learning: In a properly managed unstructured datapipeline, you can use new entries to train a production ML model, keeping the model up-to-date.
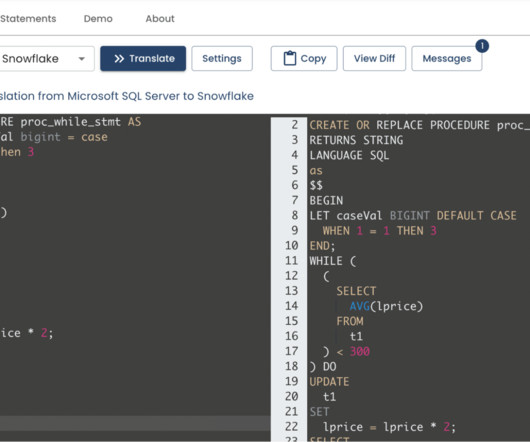
Setting up the Information Architecture Setting up an information architecture during migration to Snowflake poses challenges due to the need to align existing data structures, types, and sources with Snowflake’s multi-cluster, multi-tier architecture.
SciKit-Learn : A popular machine learning library with consistent APIs for regression, classification, clustering, dimensionality reduction, and model selection techniques. Finally, community collaboration appears likely to accelerate sharing, mentoring, and contributions around open data science.
Thus, the solution allows for scaling data workloads independently from one another and seamlessly handling data warehousing, data lakes , data sharing, and engineering. With the help of Snowflake clusters, organizations can effectively deal with both rush times and slowdowns since they ensure scalability upon demand.
Answering these questions allows data scientists to develop useful data products that start out simple and can be improved and made more complex over time until the long-term vision is achieved. At the strategy level, we are not interested in what technologies we will use for data warehousing, datapipelines, serving models, etc.
Balanced Dataset Creation Balanced Dataset Creation refers to active learning's ability to select samples that ensure proper representation across different classes and scenarios, especially in cases of imbalanced data distribution. Supports batch processing for quick processing for the images.
Data Engineering Data engineering remains integral to many data science roles, with workflow pipelines being a key focus. Tools like Apache Airflow are widely used for scheduling and monitoring workflows, while Apache Spark dominates big datapipelines due to its speed and scalability.
The service will consume the features in real time, generate predictions in near real-time , such as in an event processing pipeline, and write the outputs to a prediction queue. Orchestrators are concerned with lower-level abstractions like machines, instances, clusters, service-level grouping, replication, and so on.
Amazon SageMaker Catalog serves as a central repository hub to store both technical and business catalog information of the data product. To establish trust between the data producers and data consumers, SageMaker Catalog also integrates the data quality metrics and data lineage events to track and drive transparency in datapipelines.
However, if the tool supposes an option where we can write our custom programming code to implement features that cannot be achieved using the drag-and-drop components, it broadens the horizon of what we can do with our datapipelines. The default value is 360 seconds. If not, it will retry after a certain duration (E.g., 30 minutes).
Internally within Netflix’s engineering team, Meson was built to manage, orchestrate, schedule, and execute workflows within ML/Datapipelines. Meson managed the lifecycle of ML pipelines, providing functionality such as recommendations and content analysis, and leveraged the Single Leader Architecture.
RabbitMQ ensures reliable, structured message delivery, while Kafka excels in real-time, high-volume data streaming. Choosing between them depends on your systems needsRabbitMQ is best for workflows, while Kafka is ideal for event-driven architectures and big data processing. Thats where message brokers come in.
The Data Plane executes pipelines using Apache NiFi-based Runtimes. dev, staging, prod), horizontal scaling, multi-node and multi-cluster deployments, and DR resilience. With Openflow, teams get turnkey ingestion into Snowflake with minimal overheadno more stitching together brittle, custom pipelines.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

































Let's personalize your content