This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
This data alone does not make any sense unless it’s identified to be related in some pattern. Datamining is the process of discovering these patterns among the data and is therefore also known as Knowledge Discovery from Data (KDD). Machine learning provides the technical basis for datamining.
The unsupervised ML algorithms are used to: Find groups or clusters; Perform density estimation; Reduce dimensionality. Overall, unsupervised algorithms get to the point of unspecified data bits. In this regard, unsupervised learning falls into two groups of algorithms – clustering and dimensionality reduction. Source ].
Data archiving is the systematic process of securely storing and preserving electronic data, including documents, images, videos, and other digital content, for long-term retention and easy retrieval. Lastly, data archiving allows organizations to preserve historical records and documents for future reference.
Here are some ways data scientists can leverage GPT for regular data science tasks with real-life examples Text Generation and Summarization: Data scientists can use GPT to generate synthetic text or create automatic summaries of lengthy documents.
At the same time such plant data have very complicated structures and hard to label. And also in my work, have to detect certain values in various formats in very specific documents, in German. Such data are far from general datasets, and even labeling is hard in that case.
This code can cover a diverse array of tasks, such as creating a KMeans cluster, in which users input their data and ask ChatGPT to generate the relevant code. In the realm of data science, seasoned professionals often carry out research to comprehend how similar issues have been tackled in the past.
Conversely, OLAP systems are optimized for conducting complex data analysis and are designed for use by data scientists, business analysts, and knowledge workers. OLAP systems support business intelligence, datamining, and other decision support applications.
Thus, enabling quantitative analysis and data-driven decision-making. Understanding Unstructured Data Unstructured data refers to data that does not have a predefined format or organization. It includes text documents, social media posts, customer reviews, emails, and more. Consequently, it boosts decision-making.
You can create a new environment for your Data Science projects, ensuring that dependencies do not conflict. Jupyter Notebook is another vital tool for Data Science. It allows you to create and share live code, equations, visualisations, and narrative text documents.
Recommendation Techniques Datamining techniques are incredibly valuable for uncovering patterns and correlations within data. Figure 5 provides an overview of the various datamining techniques commonly used in recommendation engines today, and we’ll delve into each of these techniques in more detail.
At its core, decision intelligence involves collecting and integrating relevant data from various sources, such as databases, text documents, and APIs. This data is then analyzed using statistical methods, machine learning algorithms, and datamining techniques to uncover meaningful patterns and relationships.
This community-driven approach ensures that there are plenty of useful analytics libraries available, along with extensive documentation and support materials. For Data Analysts needing help, there are numerous resources available, including Stack Overflow, mailing lists, and user-contributed code.
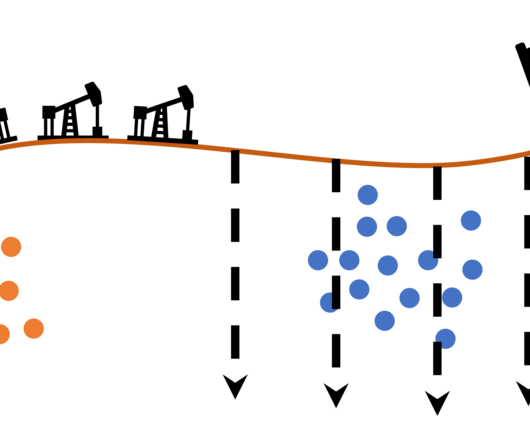
To get the most out of your unstructured data sources, you must carefully select which subsets to use. Data scientists can clean this up ahead of pre-training in a number of ways. For example, by generating embeddings for a wide sample of texts, you can use unsupervised clustering techniques to identify the topics in the data.
To get the most out of your unstructured data sources, you must carefully select which subsets to use. Data scientists can clean this up ahead of pre-training in a number of ways. For example, by generating embeddings for a wide sample of texts, you can use unsupervised clustering techniques to identify the topics in the data.
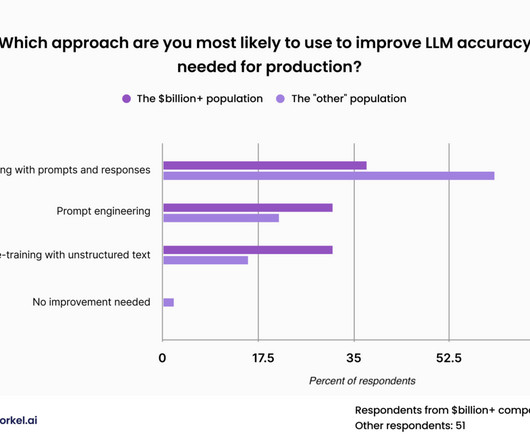
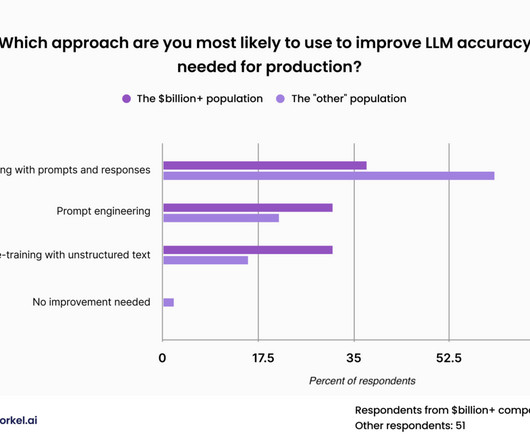
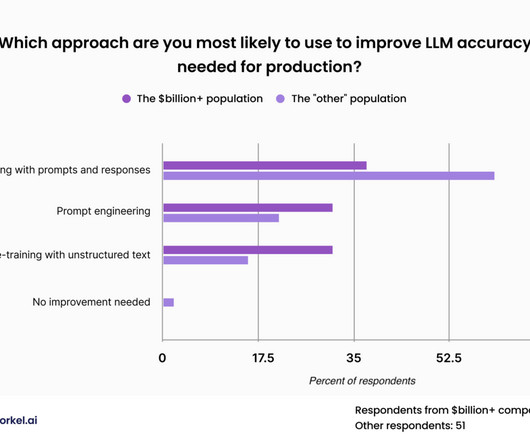
Summary : This article equips Data Analysts with a solid foundation of key Data Science terms, from A to Z. Introduction In the rapidly evolving field of Data Science, understanding key terminology is crucial for Data Analysts to communicate effectively, collaborate effectively, and drive data-driven projects.
Jupyter notebooks allow you to create and share live code, equations, visualisations, and narrative text documents. Jupyter notebooks are widely used in AI for prototyping, data visualisation, and collaborative work. Their interactive nature makes them suitable for experimenting with AI algorithms and analysing data.
Data preprocessing is essential for preparing textual data obtained from sources like Twitter for sentiment classification ( Image Credit ) Influence of data preprocessing on text classification Text classification is a significant research area that involves assigning natural language text documents to predefined categories.
To get the most out of your unstructured data sources, you must carefully select which subsets to use. Data scientists can clean this up ahead of pre-training in a number of ways. For example, by generating embeddings for a wide sample of texts, you can use unsupervised clustering techniques to identify the topics in the data.
Scikit-Learn Scikit-Learn, or simply called SKLearn, is the most popular machine learning framework that supports various algorithms for classification, regression, and clustering. It is very easy to implement and well documented. It is one of the most commonly used frameworks for datamining and analysis in the current scenario.
Applications: It is extensively used for statistical analysis, data visualisation, and machine learning tasks such as regression, classification, and clustering. Recent Advancements: The R community continues to release updates and packages, expanding its capabilities in data visualisation and machine learning algorithms in 2024.
Also Check: What is Data Integration in DataMining with Example? VMware vSphere supports many hosts and VMs per cluster, ensuring seamless scalability as your infrastructure grows. VMware vSphere provides superior scalability with its support for many hosts and VMs per cluster. What is Cloud Computing?
The startup cost is now lower to deploy everything from a GPU-enabled virtual machine for a one-off experiment to a scalable cluster for real-time model execution. Deep learning - It is hard to overstate how deep learning has transformed data science. Data science processes are canonically illustrated as iterative processes.
Scikit-learn Scikit-learn is a machine learning library in Python that is majorly used for datamining and data analysis. It offers implementations of various machine learning algorithms, including linear and logistic regression , decision trees , random forests , support vector machines , clustering algorithms , and more.
We cover the setup process and provide a step-by-step guide to running a NeMo job on a SageMaker HyperPod cluster. They are scalable and optimized for GPUs, making them ideal for curating natural language data to train or fine-tune LLMs. Prerequisites First, you deploy a SageMaker HyperPod cluster before running the job.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.
















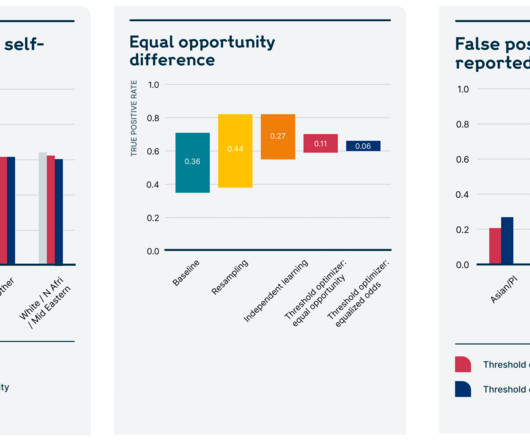








Let's personalize your content