This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
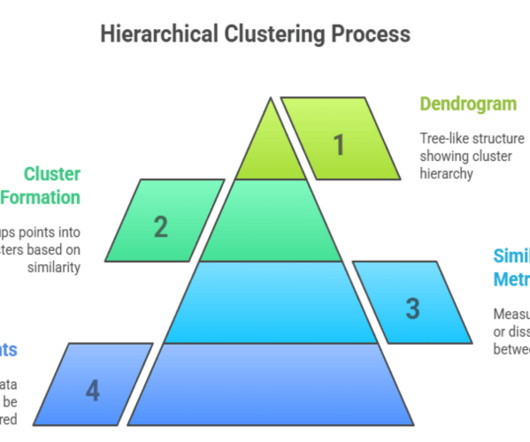
Summary: Hierarchical clustering in machine learning organizes data into nested clusters without predefining cluster numbers. This method uses distance metrics and linkage criteria to build dendrograms, revealing data structure. Dendrograms provide intuitive visualizations of cluster relationships and hierarchy.
To address this challenge, businesses need to use advanced dataanalysis methods. These methods can help businesses to make sense of their data and to identify trends and patterns that would otherwise be invisible. In recent years, there has been a growing interest in the use of artificial intelligence (AI) for dataanalysis.
It supports large, multi-dimensional arrays and matrices of numerical data, as well as a large library of mathematical functions to operate on these arrays. The package is particularly useful for performing mathematical operations on large datasets and is widely used in machine learning, dataanalysis, and scientific computing.
Text Analysis: Feature extraction might involve extracting keywords, sentiment scores, or topic information from text data for tasks like sentiment analysis or document classification. Sensor DataAnalysis: Extracting relevant features from sensor data (e.g., shirt, pants). shirt, pants).
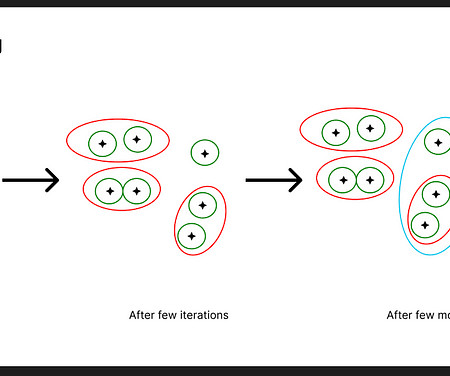
Merging clustering and classification Clustering techniques like K-means are instrumental in semi-supervised learning, facilitating the grouping of unlabeled data. K-means works by partitioning data into a number of clusters based on feature similarity.
The unsupervised ML algorithms are used to: Find groups or clusters; Perform density estimation; Reduce dimensionality. Overall, unsupervised algorithms get to the point of unspecified data bits. In this regard, unsupervised learning falls into two groups of algorithms – clustering and dimensionality reduction. Source ].
It supports large, multi-dimensional arrays and matrices of numerical data, as well as a large library of mathematical functions to operate on these arrays. The package is particularly useful for performing mathematical operations on large datasets and is widely used in machine learning, dataanalysis, and scientific computing.
This article breaks down what Late Chunking is, why its essential for embedding larger or more intricate documents, and how to build it into your search pipeline using Chonkie and KDB.AI When you have a document that spans thousands of words, encoding it into a single embedding often isnt optimal. as the vector store. Image By Author.
Summary: Python simplicity, extensive libraries like Pandas and Scikit-learn, and strong community support make it a powerhouse in DataAnalysis. It excels in data cleaning, visualisation, statistical analysis, and Machine Learning, making it a must-know tool for Data Analysts and scientists. Why Python?
Hierarchical Clustering. Hierarchical Clustering: Since, we have already learnt “ K- Means” as a popular clustering algorithm. The other popular clustering algorithm is “Hierarchical clustering”. remember we have two types of “Hierarchical Clustering”. Divisive Hierarchical clustering. They are : 1.Agglomerative
Clustering — Beyonds KMeans+PCA… Perhaps the most popular way of clustering is K-Means. It natively supports only numerical data, so typically an encoding is applied first for converting the categorical data into a numerical form. this link ).
When you see interactive and colorful charts on news websites or in business presentations that help explain complex data, that’s the power of AI-powered data visualization tools. Data scientists are using these tools to make data more understandable and actionable.
The Use of LLMs: An Attractive Solution for DataAnalysis Not only can LLMs deliver dataanalysis in a user-friendly and conversational format “via the most universal interface: Natural Language,” as Satya Nadella, the CEO of Microsoft, puts it, but also they can adapt and tailor their responses to immediate context and user needs.
This article will guide you through effective strategies to learn Python for Data Science, covering essential resources, libraries, and practical applications to kickstart your journey in this thriving field. Key Takeaways Python’s simplicity makes it ideal for DataAnalysis. in 2022, according to the PYPL Index.
Thus, enabling quantitative analysis and data-driven decision-making. Understanding Unstructured Data Unstructured data refers to data that does not have a predefined format or organization. It includes text documents, social media posts, customer reviews, emails, and more.
Its internal deployment strengthens our leadership in developing dataanalysis, homologation, and vehicle engineering solutions. These included document translations, inquiries about IDIADAs internal services, file uploads, and other specialized requests.
HCLTechs AutoWise Companion solution addresses these pain points, benefiting both customers and manufacturers by simplifying the decision-making process for customers and enhancing dataanalysis and customer sentiment alignment for manufacturers.
It enables fast, efficient full-text search, real-time DataAnalysis , and scalable data retrieval across large datasets. Known for its speed and flexibility, Elasticsearch is widely used in applications where quick access to data is critical, such as e-commerce search, log analysis, and Business Intelligence.
Use DataRobot’s AutoML and AutoTS to tackle various data science problems such as classification, forecasting, and regression. Not sure where to start with your massive trove of text data? Simply fire up DataRobot’s unsupervised mode and use clustering or anomaly detection to help you discover patterns and insights with your data.
In this era of information overload, utilizing the power of data and technology has become paramount to drive effective decision-making. Decision intelligence is an innovative approach that blends the realms of dataanalysis, artificial intelligence, and human judgment to empower businesses with actionable insights.
A basic, production-ready cluster priced out to the low-six-figures. A company then needed to train up their ops team to manage the cluster, and their analysts to express their ideas in MapReduce. Plus there was all of the infrastructure to push data into the cluster in the first place. Goodbye, Hadoop. And it was good.
Prerequisites To follow along, you should have a Kubernetes cluster with the SageMaker ACK controller v1.2.9 For instructions on how to provision an Amazon Elastic Kubernetes Service (Amazon EKS) cluster with Amazon Elastic Compute Cloud (Amazon EC2) Linux managed nodes using eksctl, see Getting started with Amazon EKS – eksctl.
This cost reduction opens up new avenues for using LLMs in scenarios where repeated querying of the same input tokens is essential, such as multi-step dataanalysis of a large dataset, repeated questioning of a full code base, and multi-turn conversations.
Lastly, if you don’t want to set up custom integrations with large data sources, you can simply upload your documents and support multi-turn conversations. The text generation LLM can optionally be used to create the search query and synthesize a response from the returned document excerpts.
Colab allows anybody to write and execute arbitrary python code through the browser, and is especially well suited to machine learning, dataanalysis and education. Moreover, the notebook is always available on the drive, enabling one to easily share its content or just to review it offline (similar to any other document on G-drive).
Look for features such as scalability (the ability to handle growing datasets), performance (speed of processing), ease of use (user-friendly interfaces), integration capabilities (compatibility with existing systems), security measures (data protection features), and pricing models (licensing costs). Statistics Kafka handles over 1.1
As a programming language it provides objects, operators and functions allowing you to explore, model and visualise data. The programming language can handle Big Data and perform effective dataanalysis and statistical modelling. R’s workflow support enhances productivity and collaboration among data scientists.
At the same time such plant data have very complicated structures and hard to label. And also in my work, have to detect certain values in various formats in very specific documents, in German. Such data are far from general datasets, and even labeling is hard in that case. “Shut up and annotate!”
The Snowflake AI Data Cloud has added the VECTOR datatype, Vector Embeddings, and Vector Similarity functions, allowing us to use Snowflake as a vector database. Text splitting is breaking down a long document or text into smaller, manageable segments or “chunks” for processing. Token Size for Token-Based Splitting.
Conversely, OLAP systems are optimized for conducting complex dataanalysis and are designed for use by data scientists, business analysts, and knowledge workers. OLAP systems support business intelligence, data mining, and other decision support applications.
AI users say that AI programming (66%) and dataanalysis (59%) are the most needed skills. And there are tools for archiving and indexing prompts for reuse, vector databases for retrieving documents that an AI can use to answer a question, and much more. Many AI adopters are still in the early stages.
Big DataAnalysis with PySpark Bharti Motwani | Associate Professor | University of Maryland, USA Ideal for business analysts, this session will provide practical examples of how to use PySpark to solve business problems. Finally, you’ll discuss a stack that offers an improved UX that frees up time for tasks that matter.
This allows you to explore features spanning more than 40 Tableau releases, including links to release documentation. . In this blog post, I'll describe my analysis of Tableau's history to drive analytics innovation—in particular, I've identified six key innovation vectors through reflecting on the top innovations across Tableau releases.
Data preprocessing is essential for preparing textual data obtained from sources like Twitter for sentiment classification ( Image Credit ) Influence of data preprocessing on text classification Text classification is a significant research area that involves assigning natural language text documents to predefined categories.
A well-organized portfolio demonstrates your ability to work with data and draw valuable insights. Here are the steps to build an impressive data analyst portfolio: Select Relevant Projects: Choose a variety of dataanalysis projects that highlight your skills and cover different aspects of dataanalysis.
You can often integrate these models with your systems through APIs, which are designed to be straightforward and well-documented. Use Case #1: Process Automation Process automation can be used to improve activities like framing images or analyzing data. In these cases, accuracy cannot be compromised, especially in dataanalysis.
Summary: Statistical Modeling is essential for DataAnalysis, helping organisations predict outcomes and understand relationships between variables. Introduction Statistical Modeling is crucial for analysing data, identifying patterns, and making informed decisions.
Vectors (and Word Vectors) Vector Databases hold information like documents, images, and audio files that do not fit into the tabular format expected by traditional databases. This is why it makes them appropriate for storing and retrieving non-traditional data sources like documents, images, and audio files.
By the end of the lesson, readers will have a solid grasp of the underlying principles that enable these applications to make suggestions based on dataanalysis. For example, term frequency–inverse document frequency (TF-IDF) ( Figure 7 ) is a popular text-mining technique in content-based recommendations.
Text Representation The next step is the representation of text, which involves the conversion of the data into a numerical format such that it is easily comprehensible. Some of the common methods involved in this are Bag-of-Words (BoW), Term Frequency-Inverse Document Frequency (TF-IDF), and word embeddings.
Applications: It is extensively used for statistical analysis, data visualisation, and machine learning tasks such as regression, classification, and clustering. Scikit-learn Functionality: Scikit-learn is a simple and efficient tool for data mining and analysis, built on NumPy, SciPy, and matplotlib.
Implementing this unified image and text search application consists of two phases: k-NN reference index – In this phase, you pass a set of corpus documents or product images through a CLIP model to encode them into embeddings. You use pandas to load the metadata, then select products that have US English titles from the data frame.
You can often integrate these models with your systems through APIs, which are designed to be straightforward and well-documented. Use Case #1: Process Automation Process automation can be used to improve activities like framing images or analyzing data. In these cases, accuracy cannot be compromised, especially in dataanalysis.
We organize all of the trending information in your field so you don't have to. Join 17,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.









































Let's personalize your content